Задачі кодування повідомлень
Кодуванням називається відображення стану однієї системи за допомогою стану деякої іншої. Найбільш простим випадком кодування є випадок, коли обидві системи Х та У мають кінцеву кількість можливих станів.
Нехай маємо деяку систему Х ( наприклад, літери російської абетки), яка може випадковим чином прийняти один з можливих станів х1, х2,…,хn. Необхідно закодувати (відобразити) її за допомогою іншої системи У, можливі стани якої у1,у2,…,уm. Якщо m<n, то неможливо кожен стан системи Х закодувати за допомогою одного-единого стану системи У. У даному випадку один стан системи Х відображається за допомогою певної комбінації (послідовності) стану системи У.
Одне й те саме повідомлення можна закодувати різними способами. Оптимальним (найвигіднішим) способом кодування є такий код, при якому на передачу повідомлень використовується мінімальний час. Якщо при передачі кожного елементарного символу використовується один і той самий час, то оптимальним буде такий код, при якому на передачу повідомлення заданої довжини буде використана мінімальна кількість елементарних символів.
Приклад
Необхідно закодувати двійковим кодом літери російської абетки так, щоб кожній літері відповідала певна комбінація елементарних символів «0» та «1» і щоб середня кількість цих символів на літеру тексту була мінімальною.
Розв’язання.
Розглянемо 32 літери російської абетки. Якщо не розрізняти літери «ъ» та «ь», а також додати проміжок між словами «-», то для кодування залишається 32 символи.
Перший метод. Не змінюючи порядки букв, занумерувати їх по порядку, надаючи їм номери від 0 до 31, а потім перевести нумерацію в двійкову систему числення. Так, число 25=1*24 + 1*23 +0*22 +0*21 +1*20 . У двійковій системі числення число 25 дорівнює 11001 ( (25)10=(11001)2). Таким чином будемо мати такий код; а ~ 00000; б ~ 00001; в ~ 00010; … я ~11110; «-» ~ 11111. У цьому коді витрачається на зображення кожної літери рівно 5 елементарних символів.
Другий метод. Побудуємо інший код, в якому на одну літеру буде в середньому припадати менша кількість елементарних символів. Для цього необхідно знати частоти літер у російському тексті. У таблиці 2.1 літери розміщені у спадчому порядку.
Таблиця 2.1 - Розміщення літер за частотами
| Літера | Частота | Літера | Частота | Літера | Частота | Літера | Частота |
| «-» | 0,145 | р | 0,041 | я | 0,019 | х | 0,009 |
| о | 0,095 | в | 0,039 | ы | 0,016 | ж | 0,008 |
| е | 0,074 | л | 0,036 | з | 0,015 | ю | 0,007 |
| а | 0,064 | к | 0,029 | ъ ь | 0,015 | ш | 0,006 |
| и | 0,064 | м | 0,026 | б | 0,015 | ц | 0,004 |
| т | 0,056 | д | 0,026 | г | 0,014 | щ | 0,003 |
| н | 0,056 | п | 0,024 | ч | 0,013 | э | 0,003 |
| с | 0,047 | у | 0,021 | й | 0,010 | ф | 0,002 |
Враховуючи табл.1, найбільш економічним буде код, в якому кожний елементарний символ буде передавати максимальну інформацію. У даному випадку інформація, яку дає цей символ, дорівнює ентропії системи і вона є максимальною, коли два стани рівноймовірні.
Такий спосіб побудови коду відомий під назвою « коду Шеннона-Фено». Він полягає у тому, що символи, які кодуються, поділяються на дві приблизно однакові рівноймовірні групи. Для першої групи символів на першому місці комбінації ставиться «0»; для другої групи – «1». Далі кожна група знову поділяється на дві приблизно рівноймовірні підгрупи. Для символів першої підгрупи на другому місці ставиться «0», а для другої підгрупи – «1» і т.д.
Побудова коду Шеннона-Фено на основі таблиці1 наведена в таблиці 2.2.
Таблиця 2.2 - Код Шеннона-Фено
| Літера | Двійкове число | Літера | Двійкове число | Літера | Двійкове число |
| «-» | к | ч | |||
| о | м | й | |||
| е | д | х | |||
| а | п | ж | |||
| и | у | ю | |||
| Продовження табл.2.2 | |||||
| т | я | ш | |||
| н | ы | ц | |||
| с | з | щ | |||
| р | ъ ь | э | |||
| в | б | ф | |||
| л | г |
Так, за допомогою коду таблиці 2.2 слово «теория» в двійковому коді має вигляд: 0111 010 001 10100 0110 110110.
Цей принцип кодування може бути застосований у тому випадку, коли помилки при кодуванні та при передачі повідомлень практично неможливі.
Третій метод. Враховуючи, що при об’єднанні залежних систем сумарна ентропія менша суми ентропій окремих систем, то інформація, яка передається відрізком пов’язаного тексту, завжди менша, ніж інформація, на один символ помножена на число символів. Враховуючи це, можна побудувати більш економічний код, якщо не кодувати окремо кожну літеру, а кодувати цілі блоки з літерів. Ці блоки необхідно розміщувати в порядку зменшення частот, і здійснювати кодування за допомогою коду Шеннона-Фено.
Знайдемо середню інформацію, яка припадає на один символ, та порівняємо її з максимально можливою інформацією, яка дорівнює двійковій одиниці. Для цього знайдемо середню інформацію, яка знаходиться в одній літері тексту, що передається (ентропію на одну літеру):

Враховуючи дані таблиць 2.1 та 2.2, знайдемо середню кількість елементарних символів на літеру:
nсер.=3*0,145+3*0,095+4*0,074+…+9*0,002=4,45.
Знайдемо інформацію на один символ:
перший метод: 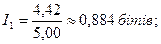
другий метод 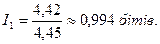
Таким чином, код, знайдений другим методом, є наближеним до оптимального.
Дата добавления: 2016-05-05; просмотров: 1190;