Линейные регрессионные модели с гетероскедастичными и автокоррелированными остатками.
Наличие гетероскедастичности может в отдельных случаях привести к смещенности оценок коэффициентов регрессии, хотя несмещенность оценок коэффициентов регрессии в основном зависит от соблюдения второй предпосылки МНК, т. е. независимости остатков и величин факторов. Гетероскедастичность будет сказываться на уменьшении эффективности оценок 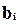 . В частности, становится затруднительным использование формулы стандартной ошибки коэффициента регрессии
. В частности, становится затруднительным использование формулы стандартной ошибки коэффициента регрессии 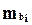 , предполагающей единую дисперсию остатков для любых фактора. Практически при нарушении гомоскедастичности мы имеем неравенства:
, предполагающей единую дисперсию остатков для любых фактора. Практически при нарушении гомоскедастичности мы имеем неравенства:
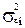
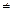
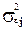
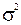 , j I,
, j I, 
и можно записать
· 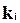 .
.
При этом величина может меняться при переходе от одного значения фактора 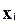 к другому. Это означает, что сумма квадратов отклонений для зависимости
к другому. Это означает, что сумма квадратов отклонений для зависимости
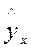 =
=  a+b·x
a+b·x
При наличии гетероскедастичности должна иметь вид:
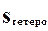 =
= 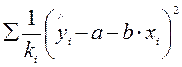 .
.
При минимизации этой суммы квадратов отдельные ее слагаемые взвешиваются: наблюдениям с наибольшей дисперсией придается пропорционально меньший вес. Иными словами, вклад каждого сочетания с 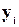 в сумму квадратов остатков должен быть дисконтирован, чтобы учесть систематическое влияние неоднородных элементов .
в сумму квадратов остатков должен быть дисконтирован, чтобы учесть систематическое влияние неоднородных элементов .
Задача состоит в том, чтобы определить величину и внести поправку в исходные переменные. С этой целью рекомендуется использовать обобщенный метод наименьших квадратов, который эквивалентен обыкновенному МНК, примененному к преобразованным данным. Чтобы убедиться в необходимости использования обобщенного МНК, обычно не ограничиваются визуальной проверкой гетероскедастичности, а проводят ее эмпирическое подтверждение.
Гетероскедастичность становится проблемой, когда значения переменных, входящих в уравнение регрессии, значительно различаются в разных наблюдениях. Если истинная зависимость описывается уравнением у = а + 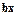 +
+ 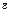 и переменные меняют свой масштаб одновременно, то изменения значений не включенных переменных и ошибки измерения, влияя совместно на случайную составляющую, делают его сравнительно малым при малых у и x и сравнительно большим при больших у и х. Пусть рассматривается зависимость между государственными расходами на образование и валовым внутренним продуктом в различных странах. Доля государственных расходов на образование составляет обычно 3-9% от ВВП. Очевидно, что если одновременно включить в выборку данные как по малым странам, таким как Люксембург, и большим, таким как Россия, то цифры будут несоотносимыми. Правда, из такой ситуации просто найти выход – вместо расходов на образование в их численном эквиваленте можно исследовать долю этих расходов в ВВП соответствующей страны. Также гетероскедастичность может проявиться при анализе данных, которые увеличиваются со временем. Например, при исследовании зависимости спроса от доходов населения очевидно, что как доходы, как и цены на товары и услуги могли просто возрасти со временем, и дисперсия случайной составляющей тоже может со временем увеличиваться.
и переменные меняют свой масштаб одновременно, то изменения значений не включенных переменных и ошибки измерения, влияя совместно на случайную составляющую, делают его сравнительно малым при малых у и x и сравнительно большим при больших у и х. Пусть рассматривается зависимость между государственными расходами на образование и валовым внутренним продуктом в различных странах. Доля государственных расходов на образование составляет обычно 3-9% от ВВП. Очевидно, что если одновременно включить в выборку данные как по малым странам, таким как Люксембург, и большим, таким как Россия, то цифры будут несоотносимыми. Правда, из такой ситуации просто найти выход – вместо расходов на образование в их численном эквиваленте можно исследовать долю этих расходов в ВВП соответствующей страны. Также гетероскедастичность может проявиться при анализе данных, которые увеличиваются со временем. Например, при исследовании зависимости спроса от доходов населения очевидно, что как доходы, как и цены на товары и услуги могли просто возрасти со временем, и дисперсия случайной составляющей тоже может со временем увеличиваться.
При наличии такой ситуации используют обобщенный МНК, который будет рассмотрен ниже. Чтобы убедиться в необходимости применения этого метода, визуальной проверки гетероскедастичности недостаточно, необходима формальная проверка. Существует большое количество разнообразных тестов.
Если предполагается, что дисперсия случайной составляющей будет либо увеличиваться, либо уменьшаться по мере увеличения x, можно применить тест ранговой корреляции Спирмена. Данные по x и остатки упорядочиваются, и коэффициент ранговой корреляции определяется как:
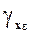 =1-
=1- 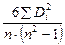 ,
,
Где 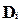 - разность между рангом x и рангом
- разность между рангом x и рангом 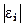 .
.
Если предположить, что соответствующий коэффициент корреляции для генеральной совокупности равен нулю, то коэффициент ранговой корреляции имеет нормальное распределение с M=0 и 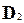 =
= 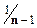 в больших выборках. Соответствующая тестовая статистика будет равна
в больших выборках. Соответствующая тестовая статистика будет равна 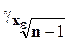 , и гипотеза об отсутствии гетероскедастичности будет отклонена при уровне значимости в 5%, если она превысит 1,96 и при уровне значимости в 1%, если она превысит 2,58. Если в модели несколько объясняющих переменных, гипотезы может выполняться с использованием любой из них.
, и гипотеза об отсутствии гетероскедастичности будет отклонена при уровне значимости в 5%, если она превысит 1,96 и при уровне значимости в 1%, если она превысит 2,58. Если в модели несколько объясняющих переменных, гипотезы может выполняться с использованием любой из них.
При малом объеме выборки, что наиболее характерно для эконометрических исследований, для оценки гетероскедастичности может использоваться метод Гольдфельда – Квандта, разработанный в 1965 г. Гольдфельд и Квандт рассмотрели однофакторную линейную модель, для которой дисперсия остатков возрастает пропорционально квадрату фактора. Чтобы оценить нарушение гомоскедастичности, они предложили параметрический тест, который включает в себе следующие шаги.
1. Упорядочение n наблюдений по мере возрастания переменной x.
2. Исключение из рассмотрение. С центральных наблюдений; при этом
(n-C):2 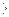 p, где p – число оцениваемых параметров.
p, где p – число оцениваемых параметров.
Таблица 3.7
Поступление доходов в консолидированный бюджет Санкт – Петербурга (у-млрд. руб.) в зависимости от численности работающих на крупных и средних предприятиях(x-тыс. чел.) экономики районов за 1994 г.
| № П / П | Районы города |
|
| 
| 
|
| Павловский | 4,4 | -1,0 | 5,4 | ||
| Кронштадт | 8,1 | 2,5 | 5,6 | ||
| Ломоносовский | 12,9 | 4,9 | 8,0 | ||
| Курортный | 20,8 | 16,6 | 4,2 | ||
| Петродворец | 15,5 | 19,0 | -3,5 | ||
| Пушкинский | 28,8 | 22,5 | 6,3 | ||
| Красносельский | 37,5 | 41,4 | -3,9 | ||
| Приморский | 48,7 | 53,2 | -4,5 | ||
| Колпинский | 68,6 | 66,1 | 2,5 | ||
| Фрунзенский | 104,6 | 82,6 | 22,0 | ||
| Красногвардейский | 90,5 | 88,5 | 2,0 | ||
| Василеостровский | 88,3 | 107,4 | -19,1 | ||
| Невский | 132,4 | 120,4 | 12,0 | ||
| Петроградский | 122,0 | 127,4 | -5,4 | ||
| Калиниский | 99,1 | 131,0 | -31,9 | ||
| Выборгский | 114,2 | 142,7 | -28,5 | ||
| Кировский | 150,6 | 151,0 | -0,4 | ||
| Московский | 156,1 | 171,0 | -14,9 | ||
| Адмиралтейский | 209,5 | 180,5 | 29,0 | ||
| Центральный | 342,9 | 327,8 | 15,1 | ||
| Итого | 1855,5 | 1855,5 | 0,0 |
3. Разделение совокупности из (n-C) наблюдений на две группы (соответственно с малыми и большими значениями фактора x) и определение по каждой из групп уравнений регрессии.
4. Определение остаточной суммы квадратов для первой ( 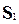 ) и второй (
) и второй ( 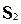 )
)
Групп и нахождение их отношения: 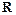 = : .
= : .
При выполнении нулевой гипотезы о гомоскедастичности отношение будет удовлетворять F-критерию с (n-C-2p):2 степенями свободы для каждой остаточной суммы квадратов. Чем больше величина 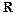 превышает табличное значение F-критерия, тем более нарушена предпосылка о равенстве дисперсий остаточных величин.
превышает табличное значение F-критерия, тем более нарушена предпосылка о равенстве дисперсий остаточных величин.
Пример. Рассмотрим табл. 3.7.
В соответствии с уравнением
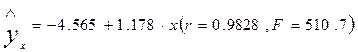
Найдены теоретические значения и отклонения от них фактических значений y, т. е. 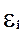 .
.
Итак остаточные величины 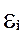 обнаруживают тенденции к росту по мере увеличения x и y (рис. 3.11).
обнаруживают тенденции к росту по мере увеличения x и y (рис. 3.11).
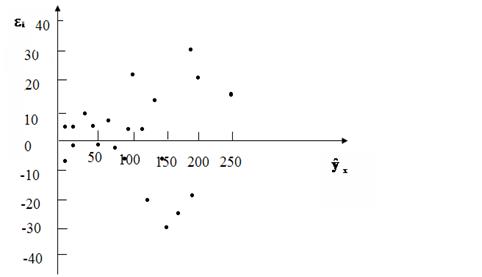
Рис.3.11. График остатков для примера по табл. 3.7
Этот вывод подтверждается и по критерию Гольдфельда – Квандта. Для его применения необходимо определить сначала число исключаемых центральных наблюдений С. Из экспериментальных расчетов, проведенных авторами метода для случая одного фактора, рекомендовано при n=30 принимать С=8, а при n=60 – соответственно С=16. в рассматриваемом примере при n=20 было отобрано С=4. Тогда в каждой группе будет по 8 наблюдений [(20-4):2]. Результаты расчетов представлены в табл. 3.8.
Таблица 3.8
Проверка линейной регрессии на гетероскедастичность
| Уравнения Регрессии | Х | У |
| 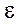
| 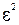
|
| 1-я группа с первыми 8 районами: | 4,4 | 5,7 | -1,3 | 1,69 | |
| 8,1 | 8,5 | -0,4 | ,016 | ||
| 12,9 | 10,3 | 2,6 | 6,76 | ||
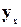 =2,978+
+0,921х =2,978+
+0,921х
| 20,8 | 19,6 | 1,2 | 1,44 | |
| 15,5 | 21,4 | -5,9 | 34,81 | ||
| r=0,979 | 28,8 | 24,2 | 4,6 | 21,16 | |
| F=136,4 | 37,5 | 38,9 | -1,4 | 1,96 | |
| 48,7 | 48,1 | 0,6 | 0,36 | ||
| Сумма | 68,34 | ||||
| 2-я группа с последними 8 районами: | 132,4 | 110,7 | 21,7 | 470,89 | |
| 122,0 | 118,7 | 3,3 | 10,89 | ||
| 99,1 | 122,7 | -23,6 | 556,96 | ||
| =31,142+
+1,338х
| 114,2 | 136,1 | -21,9 | 479,61 | |
| 150,6 | 145,4 | 5,2 | 27,04 | ||
| r=0,969 | 156,1 | 168,2 | -12,1 | 146,41 | |
| F=93,4 | 209,5 | 178,9 | 30,6 | 936,36 | |
| 342,9 | 346,1 | -3,2 | 10,24 | ||
| Сумма | 2638,40 |
Величина R=2638,4: 68,34=19,3 . что превышает табличное значение F-критерия 4,28 при 5%-ном и 8,47 при 1%-ном уровне значимости для числа степеней свободы 6 для каждой остаточной суммы квадратов ((20-4-2*2):2), подтверждая тем самым наличие гетероскедастичности.
Более тщательно рассмотреть характер гетероскедастичности позволяет тест Глейзера. Уже не предполагается пропорциональность дисперсии остатков квадрату x, а проверяется какая – либо другая форма, например 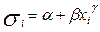
Оценивают регрессионную зависимость у от x обычным МНК, вычисляют абсолютные значения остатков 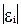 и оценивают их регрессию на
и оценивают их регрессию на 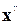 для данного значения с, после оценивается статистическая значимость коэффициента b.
для данного значения с, после оценивается статистическая значимость коэффициента b.
При построении регрессионных моделей чрезвычайно важно соблюдение четвертой предпосылки МНК – отсутствие автокорреляции остатков, т. е. значения остатков распределены независимо друг от друга. Автокорреляция остатков означает наличие корреляции между остатками текущих предыдущих(последующих) наблюдений. Коэффициент корреляции между и 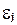 , где -остатки текущих наблюдений, - остатки предыдущих наблюдений (например, j= i -1), может быть определен как
, где -остатки текущих наблюдений, - остатки предыдущих наблюдений (например, j= i -1), может быть определен как
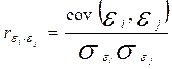 ,
,
Т.е. по обычной формуле линейного коэффициента корреляции. Если этот коэффициент окажется существенно отличным от нуля, то остатки автокоррелированы и функция плотности вероятности F(ε) зависит от j-й точки наблюдения и от распределения значений остатков в других точках наблюдения.
Для регрессионных моделей по статической информации автокорреляция остатков может быть подсчитана, если наблюдения упорядочены по фактору x, как это имеет место в таблю3ю7. Коэффициент автокорреляции остатков может быть найден по следующим рядам данных (n=19):
|
| 5,6 | 4,2 | -3,5 | 6,3 | … | -14,9 | 29,0 | 15,1 | |
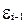
| 5,4 | 5,6 | 4,2 | -3,5 | … | -0,4 | -14,9 | 29,0 |
Учитывая, что
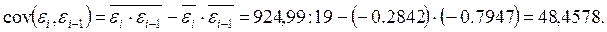
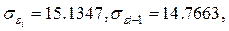 получим:
получим:
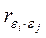 =0,2168, что при 17 степенях свободы явно незначимо (F-отношение<1) и демонстрирует отсутствие автокорреляции остатков.
=0,2168, что при 17 степенях свободы явно незначимо (F-отношение<1) и демонстрирует отсутствие автокорреляции остатков.
Если его значение по модулю оказывается близким к 1, автокорреляция присутствует.
Широко известна также статистика Дарбина - Уотсотна:
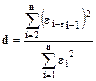
Можно показать, что при больших выборках d→2-2p.
Если автокорреляция отсутствует, то p=0, и величина d должна быть близкой к двум. При наличии положительной автокорреляции величина d,вообще говоря, будет меньше двух; при отрицательной автокорреляции она, вообще говоря, будет превышать два. Т .к. P должно лежать между -1 и 1, то d должно лежать между 0 и 4.
Наиболее желательным решением при наличии автокорреляции является попытка выявить ответственный за нее фактор и ввести его в уравнение регрессии. Как правило автокорреляция встречается, когда переменные изменяются со временем, и введение фактора времени в уравнение регрессии в этих случаях решает проблему.
Если автокорреляция подчиняется авторегрессионной схеме первого порядка 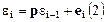 , т.е. величина случайной составляющей в любом наблюдении равна ее значению в предшествующем наблюдении, множенному на p, плюс новая ошибка е, то если известна величина p, можно полностью устранить автокорреляцию. Например, пусть рассматриваем уравнение вида (1) (при нескольких факторах принцип будет тот же). Наблюдения n и n-1 соответственно равны:
, т.е. величина случайной составляющей в любом наблюдении равна ее значению в предшествующем наблюдении, множенному на p, плюс новая ошибка е, то если известна величина p, можно полностью устранить автокорреляцию. Например, пусть рассматриваем уравнение вида (1) (при нескольких факторах принцип будет тот же). Наблюдения n и n-1 соответственно равны:
Переменной, «скрытой» в 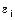 , должно быть некоррелированным с ее значением в предыдущем наблюдении. В экономическом анализе чаще всего встречается положительная автокорреляция. Предположим, оценивается зависимость спроса на мороженое от дохода и что неучтенным фактором, «скрытым» в , является только погода. Скорее всего, если наблюдения проводятся по неделям или месяцам, будет несколько последовательных наблюдений, когда погода теплая, что, естественно, увеличивает спрос на мороженое, и для них будет положительна, а затем несколько последовательных наблюдений, когда ситуация противоположна, и график зависимости объема продаж от дохода будет иметь вид:
, должно быть некоррелированным с ее значением в предыдущем наблюдении. В экономическом анализе чаще всего встречается положительная автокорреляция. Предположим, оценивается зависимость спроса на мороженое от дохода и что неучтенным фактором, «скрытым» в , является только погода. Скорее всего, если наблюдения проводятся по неделям или месяцам, будет несколько последовательных наблюдений, когда погода теплая, что, естественно, увеличивает спрос на мороженое, и для них будет положительна, а затем несколько последовательных наблюдений, когда ситуация противоположна, и график зависимости объема продаж от дохода будет иметь вид:
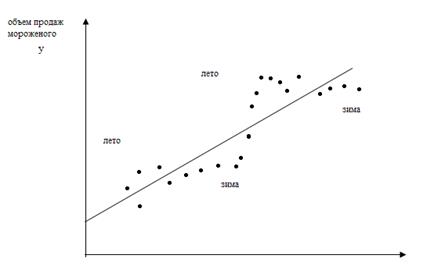
Рис.4.
Фактические наблюдения будут выше регрессии, затем ниже ее, затем опять выше. Изменения экономической конъюнктуры часто приводят к похожим результатам. Здесь важно отметить, что автокорреляция в целом тем более существенна, чем меньше интервал между наблюдениями. Чем он больше, тем менее правдоподобно, что при переходе от одного наблюдения к другому характер влияния неучтенных переменных будет сохраняться. Если например в примере с мороженым проводить наблюдения ежегодно, то автокорреляции вообще не будет.
При отрицательной корреляции, которая тоже иногда имеет место, корреляция между последовательными значениями случайной составляющей будет отрицательна. Тогда диаграмма рассеяния может иметь такой вид:
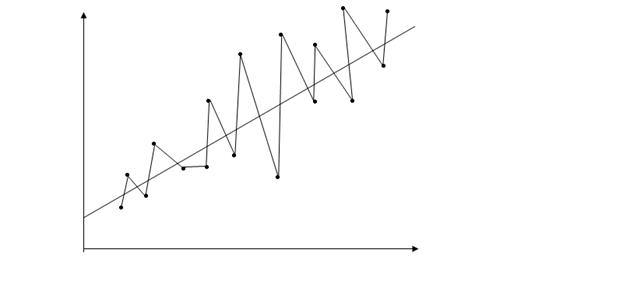
Рис .5.
В экономике отрицательная автокорреляция может появляться при преобразовании первоначальной спецификации модели в форму, подходящую для регрессионного анализа.
Отсутствие автокорреляции остаточных величин обеспечивает состоятельность и эффективность оценок коэффициентов регрессии. Особенно актуально соблюдение данной предпосылки МНК при построении регрессионных моделей по рядам динамики, где ввиду наличия тенденции последующие уровни динамического ряда, зависят от своих предыдущих уровней. О специфике исследования остаточных величин по регрессионным моделям по временным рядам.
Наряду с предпосылками МНК как метода оценивания параметров регрессии при построении регрессионных моделей должны соблюдаться определенные требования относительно переменных, включаемых в модель. Они были рассмотрены ранее при решении проблемы отбора факторов. Это прежде всего требование относительно числа факторов модели по заданному объему наблюдений (отношение 1 к 6-7). Иначе параметры регрессии оказываются статистически незначимыми. В общем виде применение МНК возможно, если число наблюдений n превышает число оцениваемых параметров m, т.е. система нормальных уравнений имеет решение только тогда, когда n>m.
Чрезвычайно важным является и требование относительно матрицы исследуемых факторов. Она должна быть свободна от мультиколлинеарности. Во множественной регрессии предполагается, что матрица факторов представляет собой невырожденную матрицу, определитель которой отличен от нуля. Наличие мультиколлинеарности может исказить правильную экономическую интерпретацию параметров регрессии (см. П.3.2.).
При несоблюдении основных предпосылок МНК приходится корректировать модель, изменяя ее спецификацию, добавлять(исключать) некоторые факторы, преобразовывать исходные данные для того, чтобы получить оценки коэффициентов регрессии, которые обладают свойством несмещенности, имеют меньшее значение дисперсии остатков и обеспечивают в связи с этом более эффективную статистическую проверку значимости параметров регрессии. Этой цели, как уже указывалось, служит и применение обобщенного метода наименьших квадратов, к рассмотрению которого мы и переходим далее.
Дата добавления: 2016-05-16; просмотров: 1286;