Этап анализы высказывания
На этапе анализа выделяют описания сущностей, упомянутых во входном высказывании, выявляют свойства этих сущностей и отношения между ними. Анализаторы, разрабатываемые для ЕЯ-систем, различают по следующим параметрам:
типу анализируемых предложений - повествовательные, вопросительные, отрицательные, полные, неполные, простые, сложные, распространенные, нераспространенные и др.;
выделяемым описаниям сущностей: выделяют понятия конкретные, абстрактные, метапонятия; отношения — предикаты: вспомогательные, состояния и действия, функциональные и др.; кванторы, модальности; прессупозиции — семантические, прагматические, экзистенциальные. Отсутствие прессупозиции;
глубине проникновения в смысл (множество ключевых слов, имя события и описания участников события, их роли и характеристики, сценарий с отсылкой к связанным подсценариям, пространственно-временное или причинно-следственное представление ситуации);
используемым для анализа средствам (морфологический, синтаксический, прагматический анализ).
В методах анализа выделяют анализ слов, предложений и текстов.
Анализ слов сводится к морфологическому анализу, обнаружению и исправлению орфографических ошибок. Цель морфологического анализа состоит в получении основ (словоформ с отсеченным окончанием) со значениями грамматических категорий (например, часть речи, род, число, падеж) для каждой из словоформ высказывания, поступившего на вход ЕЯ-системы.
Методы обнаружения и исправления орфографических ошибок подразделяют на два класса в зависимости от того, используют ли они словари основ или нет. К методам, не использующим словари, относят частотные и полигамные. Частотные методы основаны на сортировке слов по частоте их встречаемости в текстах. Предполагается, что частота встречаемости слов, содержащих ошибки, низкая. Однако среди редко употребляющихся слов тоже встречается неправильное написание. Это снижает эффективность частотных методов. В полигамных методах для поиска ошибок применяют списки возможных сочетаний букв в словах. Обычно анализируются пары и тройки идущих подряд букв. Полигамные методы целесообразно использовать в системах с открытым словарем.
Методы, в которых используются словари, подразделяют в зависимости от типа стратегии на абсолютные и относительные. К абсолютным относят «исторический» метод, основанный на словаре встречаемых ранее ошибок. Эффективность этого метода существенно зависит от размера текстов, на основе которых порожден словарь ошибок. Относительный метод состоит в нахождении в словаре слов, наиболее похожих на анализируемые. Искаженное слово подвергается определенной обработке для получения из него правильного слова. Обработка включает действия по пропуску, переносу и вставлении букв. При этом для уменьшения списка новых слов применяют частотные и полигамные методы.
Анализ предложений, как правило, сводится к синтаксическому и семантическому анализу. Наиболее распространенные методы анализа предложений были разработаны еще при создании первых ЕЯ-систем и предназначались для обработки только правильных, т.е., не содержащих отклонений от грамматической нормы, предложений. Эти методы аналогичны методам обработки искусственных языков. Однако с точки зрения требований к современным ЕЯ-системам важным является вопрос о том, насколько существующие анализаторы могут быть приспособлены к обработке «неграмматичностей», т. е. характерных для диалогов между людьми высказываний с отклонениями от грамматической нормы. Это лексические и грамматические ошибки, пропуски, повторы, шумы и т. д. Различают следующие типы ЕЯ-анализаторов: традиционные, концептуальные, использующие сопоставление по образцу, а также разнообразные стратегии.
Традиционные анализаторы используют разбор предложений сверху вниз, слева направо, основанный на некоторой фиксированной грамматике. Анализаторы этого типа осуществляют разбор предложения либо в общих грамматических категориях, либо в терминах категорий, имеющих значение в некоторой ограниченной области. Данные анализаторы очень хрупки и терпят неудачу при разборе предложений с малейшими отклонениями от нормы. Один из возможных подходов к преодолению хрупкости традиционных анализаторов состоит в одновременном применении нескольких подграмматик. Каждая из них предназначена для анализа частных конструкций какого-то одного вида. Применение подграмматик осуществляется независимо, поэтому неудача одной грамматики не влияет на возможности других. При данном подходе предложение в процессе анализа разбивается на несколько независимых фрагментов. В этом случае в задачу анализатора входит построение объединенной интерпретации предложения. При достаточно ограниченной проблемной области интерпретация фрагментов всегда уникальна, однако в общем случае эта задача не имеет единственного решения и может стать трудно разрешимой.
Концептуальные анализаторы используют методы разбора, направляемые значениями базовых событий, обнаруженных в анализируемых предложениях. Различают анализаторы, основанные моделях концептуальной зависимости Р. Шенка (1980) и управления Ю.Д. Апресяна (1995). Заложенные в них идеи позволяют реализующим их алгоритмам работать в условиях пропусков и повторов слов. Концептуальные анализаторы игнорируют непонятные им слова, а понятные (даже с ошибками) приспосабливают к базовым событиям обрабатываемого предложения.
Анализаторы, использующие сопоставление по образцу. Анализ и данном случае сводится к сопоставлению предложения с некоторым множеством шаблонов, представляющих последовательности из одного или нескольких слов. Шаблоны могут содержать переменные и сопоставляться с любой строкой символов. Гибкость анализаторов определяется гибкостью процесса сопоставления. Разнообразие форм сопоставления позволяет анализировать входные предложения, отклоняющиеся от традиционной грамматики, однако глубина проникновения в смысл обычно невелика.
Последние исследования показали, что использование в одном анализаторе нескольких специфических методов позволяет обеспечить гибкость процесса анализа, необходимую для обработки неграмматических конструкций.
Анализ текстов. Связность текста (дискурса) достигается как лингвистическими средствами, так и ситуационными средствами — умолчаниями, не имеющими языкового выражения и основанными на общности знаний коммуникантов о цели общения и проблемной области. На этапе анализа связного текста решают задачу выявления связей между предложениями, выражаемых лингвистическими средствами, а на этапе интерпретации — ситуационными.
К основным лингвистическим средствам связи предложений относят ссылки и эллипсис. При установлении ссылок выделяют две задачи:
поиск в предыдущих предложениях (контексте) референта, обозначаемого данной ссылкой;
определение соответствия между референтом и ссылкой.
Отсутствие критерия для определения количества просматриваемых предыдущих предложений приводит на практике как к увеличению времени поиска, так и ошибкам в установлении ссылок. Решение второй задачи тривиально в случае тождества референта и ссылки и весьма затруднительно при их несовпадении. Отсутствие хороших методов решения обеих задач на этапе анализа текста стимулировало попытки их решения на этапе интерпретации.
Задачу обработки эллиптических конструкций решают на этапе анализа также в ограниченной постановке. Под эллипсисом понимают сжатую форму высказывания, смысл которой определяется либо предыдущими высказываниями (текстовый эллипсис), либо ситуацией, имеющей место в проблемной области (ситуативный эллипсис). Высказывания, содержащие эллипсис, выглядят как неполные (содержащие пропуски слов) предложения. На этапе анализа может быть обработан (т.е. восстановлен) только текстовый эллипсис. Сущность методов восстановления текстового эллипсиса состоит в подстановке фрагментов предыдущих высказываний в текущее высказывание, содержащее эллипсис. Восстановление ситуационного эллипсиса осуществляется на этапе интерпретации.
Этап интерпретации высказывания
На этапе интерпретации решают две основные задачи:
буквальная интерпретация высказывания в контексте диалога
интерпретация на цели участников общения.
Методов решения этих проблем в общей постановке не существует, однако применительно к простым предметным областям их решение существенно упрощается. К простым относят задачи информационного обслуживания (погода, товары, литература и т. д.) и резервирования (мест, билетов, товаров). Эти задачи оперируют ограниченным количеством сущностей, которые являются параметрами предлагаемого вида обслуживания.
В общем случае процесс идентификации сущности может иметь три исхода: однозначный, многозначный и неудовлетворительный. Последние два исхода рассматриваются как неудачи буквальной интерпретации и служат сигналами о необходимости установления подцелей более глубокого уровня, предусматривающих устранение неудачи. При этом в диалоговый компонент, кроме сообщения о неудаче и типе неудачи, передаются исходные данные, позволяющие сформировать (с помощью компонента генерации высказывания действие системы по перехвату инициативы и открытия уточняющего поддиалога, преследующего новую подцель. При решении задач интерпретации важную роль играет имеющееся в системе представление общей точки зрения на то, о чем идет речь в текущий момент. Данную точку зрения называют фокусом. Разделяемый участниками фокус позволяет им повысить компактность диалога за счет того, что сущности, находящиеся в фокусе, могут либо вообще не упоминаться в высказываниях (эллипсис), либо упоминаться в виде кратких описаний (ссылок).
Указанные методы базируются на фреймовых представлении». Методы интерпретации, используемые в более сложных областях (например, понимание связных текстов, описывающих разворачивающиеся во времени события с большим числом участников), находятся в стадии становления и не поддаются обобщенному описанию, так как сильно зависят от условий задач и специфики применяемых средств представления знаний.
4. Компонент генерации высказываний ЕЯ-системы
Первые попытки синтеза осмысленных ЕЯ-текстов с использованием ЭВМ относят к началу 60-х годов XIX века, когда были разработаны программы синтеза отдельных английских и русских предложений. В 1969 г. был предложен алгоритм синтеза русского абзаца с использованием упрощенной грамматики зависимостей. Первые программы синтеза связного текста строили последовательность ЕЯ-фраз заданной синтаксической структуры.
Общим недостатком ранних ЕЯ-систем является то, что они имитировали, а не порождали текст. Эти программы не имели заданной темы и заранее определенных действующих лиц.
Выделяют два основных этапа, необходимых для синтеза высказывания: генерация смысла высказывания и преобразование смысла в высказывание на ограниченном ЕЯ. Первый этап называют внелингвистическим синтезом, второй — лингвистическим.
Внелингвистический синтез является сложным и малоизученным, связанным с решением таких задач, как определение информации, которая должна быть сообщена пользователю; определение уровня общности информации, включаемой в высказывание; определение лексем и построение семантического представления высказывания и т.п.
Вопрос создания общей теории внелингвистического синтеза, позволяющей формализовать генерацию смысла высказывания, на данном этапе не решен.
В большинстве действующих ЕЯ-систем генерация смысла упрощена или сильно ограничена рамками решения конкретных задач, что приводит к значительному упрощению процедуры синтеза. Во многих приложениях используется метод шаблонов, содержащий элементы семантики и синтаксиса. Как правило, шаблон представляет собой текст на естественном языке с некоторыми пробелами. В процессе синтеза осуществляется подстановка на места пробелов необходимых слов в соответствующей форме. Собственно лингвистический синтез связан непосредственно с синтаксисом и лексикой ЕЯ, а также с референцией, т. е. с соотнесением языковых сущностей с сущностями внеязыковыми. Имеется ряд моделей для описания лингвистического синтеза. Наиболее распространены деревья синтаксического подчинения, системы составляющих, а также синтаксических групп. В современной лингвистике в последнее время для решения частных задач применяют математический аппарат теории автоматов и нечеткой логики. Предпринимаются попытки аксиоматического описания фрагментов естественного языка.
5. Классификация ЕЯ-систем
В контексте компьютерных систем естественный язык рассматривается как средство хранения и передачи информации внутри человеческого сообщества. Теорию языка как структуры, соответствующую классификацию и методы обработки формальных языков начали разрабатывать в математике (а позднее и в информатике) еще с 30-х годов XIX в. Однако прямое применение существующего аппарата описания формальных языков к ЕЯ невозможно вследствие того, что это объект принципиально другой природы. Естественный язык в отличие от формального языка не следует задуманной и последовательно реализованной концепции. Он развивается с течением времени под воздействием многих внешних и внутренних сил и усваивается в сообществе через использование в коммуникации, а не благодаря правилам. Кроме того, чисто грамматическое описание естественного языка недостаточно для использования, поскольку он соотносится со структурами знаний, используемыми его носителями. В результате описание грамматики ЕЯ как некоторого класса грамматики формальной оказывается затруднено.
Задача автоматизированной обработки ЕЯ-текстов впервые появилась в 60—70-х годах XIX в. С тех пор было предпринято множество различных попыток ее решения, однако широкого распространения такие системы пока не получили, как правило, из-за невысокого качества распознавания фраз, жестких требований к синтаксису «естественного языка», а также больших затрат машинных ресурсом, необходимых для их работы. Во всех системах машинного анализа текста используют ограниченный ЕЯ, поскольку полной и строгой формальной модели ни для одного ЕЯ пока не создано. Тем не менее ЕЯ-системы постоянно развиваются, что обусловлено, с одной стороны, развитием теоретических средств описания ЕЯ, а с другой прогрессом технологий программирования.
Исторически ЕЯ-системы происходят от информационно-поисковых систем, с одной стороны, и систем машинного перевода с другой. Поэтому на начальном этапе ЕЯ-системы представляли собой макеты информационно-поисковых систем, демонстрирующие принципиальную возможность ввода данных (фактов) и обработки запросов на естественном языке. Такие системы часто назывались интеллектуальными вопрос-ответными системами. Название можно, по-видимому, объяснить стремлением их разработчиков подчеркнуть, что в отличие от обычных информационно-поисковых систем и систем машинного перевода того времени в данных системах широко используются концепции, выработанные в исследованиях по искусственному интеллекту.
Основное внимание при разработке интеллектуальных вопрос-ответных систем уделялось не столько возможностям их практического использования в реальных задачах, сколько развитию моделей и методов, позволяющих осуществлять перевод ЕЯ-высказываний, относящихся к узким и заранее фиксированным проблемным областям, в формальное представление, а также обратный перевод. Накопленный опыт разработки интеллектуальных вопрос-ответных систем позволил, с одной стороны, углубить понимание процесса ЕЯ-общения и, следовательно, поставить новые проблемы (в том числе и специфичные для общения в различных классах проблемных областей), требующие дальнейшей проработки, а с другой - оценить перспективы практического применения ЕЯ-систем.
Первые предпосылки для практического использования ЕЯ-систем создало появление баз данных (БД). В связи с этим возникла проблема обеспечения доступа к информации, хранящейся в БД, широкому классу неподготовленных конечных пользователей, к которым относят специалистов в той или иной предметной области, как правило, не обладающих знаниями о логической структуре БД, о системе представления информации в БД и не умеющих пользоваться формализованными языками запросов. Для решения этой проблемы стали создаваться системы общения с базами данных, основная задача которых (в простейшем случае) заключается в выполнении перевода запросов неподготовленных конечных пользователей с ЕЯ на формализованные языки запросов к БД.
Следующим типом ЕЯ-систем стали диалоговые системы решения задач, которые в отличие от систем общения с БД берут на себя не только функции ЕЯ-доступа к БД, но и функции интеллектуального монитора, обеспечивающего решение заранее определенных классов задач (например, планирование путешествий, боевых операций, составление контрактов и т. п.). В этом случае разбиение задач на подзадачи и распределение ролей между участниками, т. е. определение, кто из участников (пользователь или система) решает ту или иную подзадачу, осуществляется не пользователем (как в случае применения систем общения с БД), а диалоговой системой. Решение подзадач, «порученных» системе, может осуществляться как на основе использования собственных знаний и механизмов вывода, так и в результате обращения к прикладным программам и пакетам, не входящим в состав ЕЯ-системы. Основным направлением практического использования ЕЯ-систем данного класса является реализация ЕЯ-общения с экспертными системами.
Возникновение последнего типа ЕЯ-систем — систем обработки связных текстов, обусловлено возрастанием объема хранимой в ЭВМ текстовой информации (газетные статьи, сообщения о различных событиях, патенты, авторские свидетельства и т.п.) и необходимостью извлечения из нее разнообразных сведений (например, о структуре некоторых объектов, о действующих лицах некоторых событий, о мотивах их поступков и т.д.).
С учетом истории развития различают следующие основные классы ЕЯ-систем:
интеллектуальные вопрос-ответные системы;
системы общения с базами данных;
диалоговые системы решения задач;
системы обработки текстов.
В данной классификации выделен аспект речевого взаимодействия.
Кроме того, существуют другие категории классификации ЕЯ-систем:
цель моделирования: анализ, синтез, машинный перевод;
количество языков: одноязычные, двуязычные, многоязычные;
уровень представления: морфологический, синтаксический, семантический, прагматический;
языковая единица: слово, предложение, текст, корпус текста;
тип обработки: внелингвистические, статистические, психолингвистические, морфологические, синтаксические, семантические, прагматические.
Каждый из классов ЕЯ-систем обладает специфическими особенностями, которые хорошо заметны при рассмотрении характера задач, решаемых основными функциональными компонентами этих систем (рис. 3).
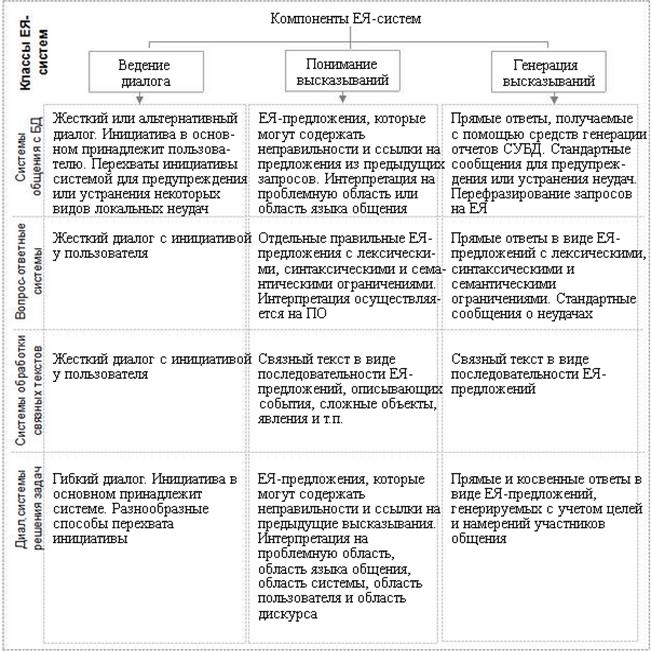
Рис.3. Сравнительная характеристика основных классов ЕЯ-систем
Необходимо отметить, что класс систем обработки связных текстов дал начало развитию более совершенных ЕЯ-систем, к которым относятся:
системы обработки множества текстов;
системы проверки орфографии;
системы автоматического (машинного) перевода;
Поэтому указанные системы вместе с системами обработки связных текстов образовали более широкий класс ЕЯ-систем – систем обработки текстов.
6. Обзор ЕЯ-систем
В интеллектуальных вопрос-ответных системах основное внимание уделено приближению языка общения к литературному естественному языку. Данный класс систем развился с ориентацией не столько на использование в реальных задачах, сколько на развитие методов и моделей, позволяющих осуществлять перевод естественно-языковых высказываний, относящихся к узким и заранее фиксированным проблемным областям, в формальное представление, а также обратный перевод. Представителями данного класса являются системы ПОЭТ, ДИСПУТ, LUNAR, LIFER и др. (рис. 4).
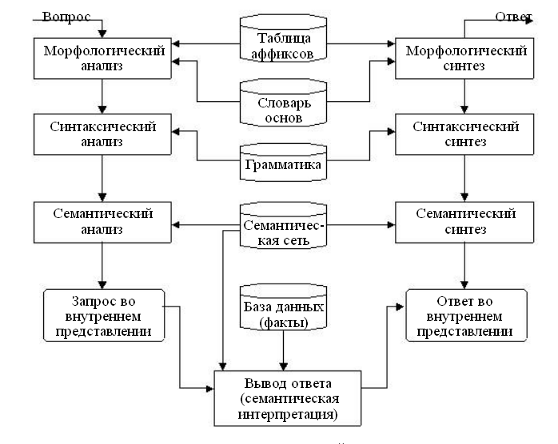
Рис. 4 Схема вопрос-ответной системы ПОЭТ
ЕЯ-системы общения с базами данных возник в появлением баз данных с целью обеспечения доступа к информации широкого класса неподготовленных пользователей. К системам этого класса относят PARNAX, TEAM, IRUS, АИСТ и др. (рис. 5).
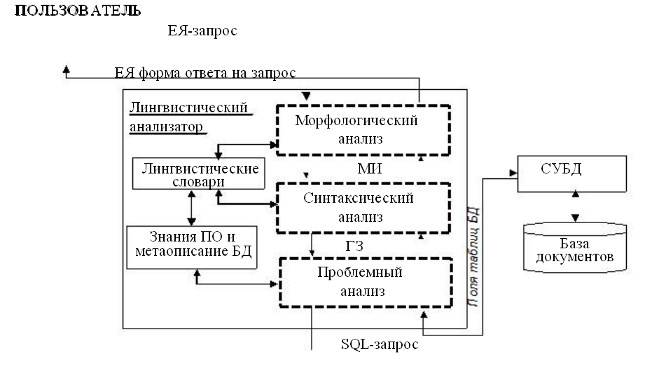
Рис. 5. Структурная схема системы с базой данных
Диалоговые системы решения задачи в отличие от систем общения с базами данных берут на себя не только функции доступа к базе данных, но и функции интеллектуального монитора, обеспечивающего решение заранее определенных классов задач. Основным направлением практического применения систем данного класса является реализация естественно-языкового общения с экспертными системами. В рамках данного подхода были созданы системы: XCALIBUR, ADVISOR, UC и др. (рис. 6).
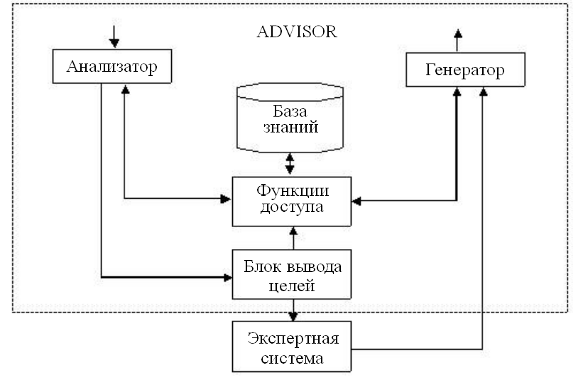
Рис. 6. Структурная схема системы решения задач ADVISOR
Класс систем обработки текстов включает в себя множество различных направлений.
Это, прежде всего, системы обработки связных текстов, которые моделируют процесс понимания законченных описаний каких-то фрагментов действительности, выраженных в виде текста на естественном языке, т. е. последовательности связанных друг с другом предложений. Обычно такие системы используют для поиска текста с нужной пользователю информацией, его реферирования, поиска дополнительной информации, связанной с ним, и т. д. К этим системам относят ТАСС, KERNEL, RESEARCHER, TAILOR, FAUSTUS и др. (рис. 7).
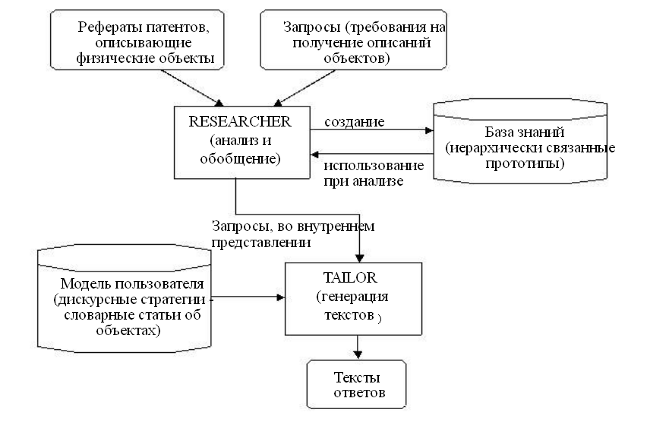
Рис. 7. Схема взаимодействия систем обработки связных текстов RESEARCHER и TAILOR
Большой интерес представляют системы, работающие с множеством текстов:
TEXTANALYST;
МИНЕРВА;
ВААЛ 2000;
RELATUS и др.
TEXTANALYST позволяет работать с отдельными текстами и (корпусом текстов, автоматизирует процесс решения следующих задач:
структурный анализ содержания текста;
построение тематической структуры текста; реферирование;
формирование гипертекста; смысловой поиск.
В данной системе работа с текстом осуществляется на уровне слов, а для построения семантической сети используют методы контент-анализа. В связи с этим задачи реферирования и смыслового поиска решаются недостаточно эффективно. Реферирование является простой выборкой предложений с наибольшими весами, а поиск ограничен множеством терминов данного текста. Тем не менее в ряде случаев данная система справляется с решением указанных задач, особенно при анализе больших текстов.
МИНЕРВА предназначена для формирования семантического описания текста документа и помещения его в базу данных. Результатом работы системы является описание смысла текста на объектно-ориентированном языке МИНЕРВА, составляющее базу знаний юридической экспертной системы. В настоящее время проект находится в стадии разработки.
ВААЛ 2000 — психолингвистическая система, позволяющая прогнозировать эффект неосознаваемого эмоционального воздействия текстов на массовую аудиторию, анализировать тексты с точки зрения такого воздействия, составлять тексты с заданным вектором воздействия, выявлять личностно-психологические качества авторов текста. ВААЛ работает на уровне слов методами контент-анализа и использует оригинальную экспертную систему оценки психологического воздействия.
RELATUS была создана с целью анализа текстов, отражающих политические события. Система приобретает знания посредством отображения точных и явных текстов в динамическое представление знаний в виде структурированных ссылок. Работа с RELATUS рассчитана на специалистов, рядовой пользователь должен пройти серьезное обучение.
Таким образом, наиболее известные в настоящее время разработки в области анализа текста осуществляют семантический анализ на уровне предложения или слова.
Важным классом ЕЯ-систем являются системы проверки орфографии. К наиболее развитой системе этого типа относят систему построения гипертекстовых документов на русском языке КОМП-ТЕК. Система отличается от аналогов построением индексов не по словоформам, а по словам, что позволяет однозначно идентифицировать слова во всех формах в тексте. Система ориентирована на поиск статей по ключевым выражениям, заданным в запросе, и сейчас идет дальнейшее развитие системы, ориентированное на обработку текстов на русском языке.
Другим направлением обработки текстов на естественных языках являются системы автоматического перевода. В них также использованы индексация словаря по словам и принципы синтаксического анализа и дополнительную информацию о характерных оборотах. Обычно текст предварительно переводится на внутренний язык системы и затем, уже с этого промежуточного языка, строится текст на целевом языке. Такая конструкция позволяет использовать модульное построение системы и расширять область ее действия простым формированием дополнительных словарей. К таким системам относят STYLUS, СОКРАТ, TRANSLATION OFFICE и т. д. Более простые версии представляют собой обычные интерактивные словари, например «Контекст».
Для всех описанных выше систем характерны следующие недостатки: узкая область применения и высокие ресурсные требования. Ни одна из них не может предложить полноценный интерфейс на естественном языке, который позволял бы эффективно управлять компьютером.
Дата добавления: 2016-04-22; просмотров: 2187;