Лекция. Лингвистические переменные
Лингвистические переменные(ЛП)являются способом описания сложных систем, параметры которых рассматриваются не с количественных позиций, а как качественные. При этом лингвистические переменные позволяют поставить в соответствие качественным характеристикам некоторую количественную интерпретацию с заданной долей уверенности, что обеспечивает возможность обработки качественных данных на ЭВМ. Другой сферой применения лингвистических переменных является нечеткий логический вывод, отличие которого от обычного заключается в том, что истинность логических высказываний определяется не двумя значениями 0 и 1, а множеством значений в интервале [0, 1].
В основе понятия лингвистической переменной лежит понятие нечетной переменной.
Нечеткой переменнойназывается совокупность трех элементов:
<X, U, µA(u) >,
где Х – название нечеткой переменной; U – универсальное множество; µA(u) – нечеткое подмножество А универсального множества U. Другими словами, нечеткая переменная представляет собой именованное нечеткое множество.
Лингвистической переменной называется совокупность пяти элементов:
<L, T(X), U, G, M >,
где L – название лингвистической переменной;
Т(X) –множество базовых термов лингвистической переменной, состоящее из множества названий значений лингвистических переменных {T1, T2, …, Tn}, каждому из которых соответствует нечеткая переменная Х универсального множества U;
U – универсальное множество, на котором определена лингвистическая переменная;
G – синтаксическое правило, порождающее названия X значений переменной;
М – семантическое правило, которое ставит в соответствие каждой нечеткой переменной X ее смысл М(X), т.е. нечеткое подмножество универсального множества U.
К термам лингвистической переменной предъявляется требование упорядоченности: T1 < T2 < … < Tn.
Функции принадлежности нечетких множеств, составляющих количественный смысл базовых термов лингвистической переменной, должны удовлетворять следующим условиям:
1. 
2. 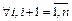 :
: 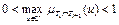 ;
;
3. 
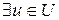 :
: 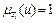
4. : 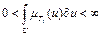 .
.
Здесь n – количество базовых термов лингвистической переменной; umin, umax – границы универсального множества U, на котором определяется лингвистическая переменная. Если U  R (R – множество действительных чисел, то U = [umin, umax].
R (R – множество действительных чисел, то U = [umin, umax].
Синтаксическое правило G представляет собой совокупность четырех элементов: G = < VT, VN, T, P >,
где VT – совокупность терминальных символов или слов; VN – совокупность нетерминальных символов или фраз; Т – совокупность базовых термов; Р – совокупность правил подстановки, определяющих эквивалентность фраз.
Семантическое правило М ставит в соответствие каждой фразе новое не-
четкое множество, определенное на основе функций принадлежности базовых термов и совокупности операций с нечеткими множествами.
В качестве примера рассмотрим числовую лингвистическую переменную «рост человека». Пусть значения переменной задаются с помощью трех базовых термов: «низкий», «средний», «высокий». Термы упорядочены. Универсальным числовым множеством U в данном случае является интервал U = [0; 300].
 Функции принадлежности термов приведены на рис. 7.6 и удовлетворяют рассмотренным выше требованиям.
Функции принадлежности термов приведены на рис. 7.6 и удовлетворяют рассмотренным выше требованиям.
Рис. 7.6 Лингвистическая переменная «Рост человека»
В качестве синтаксического правила определим, что в множество нетерминальных символов включены слова «и», «или», «более или менее», «не», «очень», которые могут сочетаться с базовыми термами «низкий», «средний», «высокий», причем должны выполняться следующие правила:
- символы «и» и «или» могут соединять только две фразы или базовых терма, а остальные нетерминальные символы являются унарными, т.е. могут предварять фразу или базовый терм; например, «не высокий», «очень низкий», «низкий или средний»;
- одновременное отрицание двух базовых термов, например, «не низкий и не высокий», эквивалентно оставшемуся базовому терму, т.е. «средний».
Применяя эти правила, можно построить множество фраз и правил подстановки. В случае, если синтаксическое правило нельзя задать алгоритмически, то просто перечисляются все возможные фразы.
В качестве семантического правила определим соответствие между нетерминальными символами и операциями над нечеткими множествами:
«не» – дополнение;
«и» - пересечение;
«или» - объединение;
«очень» - концентрирование;
«более или менее» - расширение.
Используя рассмотренную лингвистическую переменную, можно оцени-
вать рост людей, не прибегая к точным измерениям.
Таким образом, с помощью лингвистических переменных можно описывать объекты, точное измерение характеристик которых либо крайне трудоемко, либо вообще невозможно.
Формирование лингвистической переменной, как правило, реализуется на основе опроса экспертов – специалистов в той области, для которой строится ЛП. При этом особое внимание уделяется формированию функций принадлежности нечетких множеств, являющихся базовыми термами лингвистической переменной, так как определение синтаксического и семантического правил для большинства лингвистических переменных стандартно и на практике сводится к перечислению всех возможных фраз и интерпретации нетерминальных символов, как показано выше.
Процесс формирования лингвистической переменной включает следующие этапы:
1. Определение множества термов ЛП и его упорядочение.
2. Построение числовой области определения ЛП.
3. Выяснение схемы опроса экспертов и проведение опроса.
4. Построение функций принадлежности для каждого терма ЛП.
Этап 1 предполагает задание экспертом количества термов ЛП и названий соответствующих им нечетких переменных. Количество термов выбирается из диапазона n = 7±2.
На этапе 2 описывается универсальное множество U, которое может быть числовым и нечисловым. Вид универсального множества зависит от описываемых объектов и определяет способ формирования функций принадлежности термов ЛП.
Этап 3 является ключевым при формировании ЛП. Существует два вида
опроса экспертов: прямой и косвенный. Каждый из этих способов может быть индивидуальным или групповым. Наиболее простым с точки зрения организации и
программной реализации является индивидуальный способ опроса экспертов.
При прямом опросе экспертов непосредственно указывают все параметры функций принадлежности. Недостатком здесь является проявление субъективизма в суждениях, а также необходимость знания экспертом основ нечеткой логики. При косвенном опросе функции принадлежности формируются на основе ответа эксперта на «наводящие» вопросы. При этом повышается объективность оценки и не требуется знания нечеткой логики, однако усиливается риск несогласованности суждений эксперта.
При групповых методах опроса результат формируется на основе объединения мнений нескольких экспертов. На практике наиболее часто используется индивидуальный косвенный опрос.
Содержанием этапа 4 является обработка результатов опроса экспертов и построение функций принадлежности термов ЛП.
Дата добавления: 2016-04-22; просмотров: 3238;