Понятие базы данных. Системы управления базами данных. Создание, ведение и использование баз данных при решении учебных и практических задач.
Любой из нас, начиная с раннего детства, многократно сталкивался с бытовыми аналогами баз данных. Это — всевозможные справочники, энциклопедии и т. п., и самый популярный из всех — телефонный. Записная книжка — тоже «база данных», которая есть у каждого из нас. Большая или маленькая, простая или многофункциональная, она — обязательный элемент деловой жизни любого человека. Где бы мы хранили имена, телефоны, адреса, даты рождения и пр. своих многочисленных друзей, знакомых, деловых партнеров, непосредственных начальников, коллег и т. д., если бы не было записных книжек? В необходимых случаях мы обращаемся к ней, чтобы получить нужные сведения.
Потребность структурировать накопленную или накапливающуюся информацию (организовывать массивы данных в определенном порядке и последовательности, с определенной обработкой этих данных), содержащую совокупность сведений в какой-либо предметной области, возникла у человечества давно. Всевозможные справочники и энциклопедии уже в прошлом веке были широко распространены. Подобные «базы данных» и базы данных настоящего времени — это принципиально разные вещи, но их объединяет одна главная идея — структурирование данных по какому-либо основанию.
Другими словами, база данных(БД) — это организованная совокупность структурированных данных в какой-либо предметной области.
Развитие технологии «баз данных» привело к созданию компьютерных баз данных, которые являются основой упорядочивания, сортировки, хранения, математической и графической обработки данных. Самый простой способ создания баз данных для большинства пользователей — с помощью специальных программных сред, которые называются системами управления базами данных(СУБД). Все современные компьютерные базы данных можно разделить на
иерархические, реляционные и сетевые, т. е. в основе любой СУБД лежит один из трех указанных типов моделей данных. Дадим краткую характеристику этим моделям.
Иерархическая модель графически представляет собой перевернутое дерево. Основные параметры этой модели - это уровни, узлы, связи. Первый уровень занимает центральный узел, второй — узлы второго уровня и т. д. Между узлами установлены связи, причем эти связи фиксированы, т. е. каждый узел связан со своим подмножеством узлов следующего уровня, и эти подмножества не пересекаются. Данная модель может быть представлена на примере школы: параллели, классы, учащиеся.
Сетевая модель подобна иерархической модели. Она представлена теми же компонентами: уровнями, узлами, связями, но характер их взаимодействия другой. В этой модели все связи между элементами различных уровней являются свободными, т. е. каждый элемент вышестоящего уровня может быть связан одновременно с любыми элементами следующего уровня. Пример — Всемирная паутина (WWW).
Что же такое реляционная база данных? Прежде, чем ответить на этот вопрос, сделаем краткий исторический экскурс по наиболее ярким представителям реляционных баз данных разных поколений. Первые компьютерные базы данных появились в 80-х годах XX века. Это были «неповоротливые» среды, с достаточно примитивным инструментом обработки данных, который создавал множество файлов, необходимых для полноценного функционирования базы данных в целом. Для создания более гибких структур в подобных БД необходимо было использовать их внутренний язык. Интерфейс таких сред напоминал экран MS DOS. Все команды БД вводились в командной строке, точно так же, как и в MS DOS. Подобными особенностями обладали базы данных семейств dBase II, dBase III (например, база данных «Карат»). Базы данных FoxPro и Paradox различных версий были представлены улучшенным (более удобным и многофункциональным) интерфейсом, а также имели усовершенствованные Мастера для создания отчетов и среды для написания процедур.
Обычно базу данных, состоящую из двумерных таблиц, принято называть реляционной. Тогда все базы данных семейства dBase II, dBase III, FoxPro и т. п. — реляционные, так как данные в них представляются в виде таблиц.
Понятно, что с усовершенствованием и развитием БД нового поколения, сам термин «реляционная база данных» расширился, т. е. говоря о реляционных БД недостаточно упоминать только о представлении в ней данных в виде двумерных таблиц.
Характерные особенности реляционных баз данных:
• табличное представление данных;
• все реляционные СУБД обрабатывают большие объемы информации, намного больше, чем те, с которыми справляются электронные таблицы;
• реляционная СУБД может легко связывать таблицы так, что для пользователя они будут представляться одной таблицей (создание сложных информационных моделей);
• реляционная СУБД минимизирует общий объем базы данных. Для этого таблицы, содержащие повторяющиеся данные, разбиваются на несколько связанных таблиц;
• реляционная СУБД отличается от традиционных СУБД тем, что в единственном файле базы данных находятся не только таблица с данными, но и различные другие объекты (пример — файл базы данных Access). Хотя идеальный вариант в реляционной СУБД — два файла базы данных. В одном находятся данные, в другом -объекты, модули. Такое разбиение позволяет сделать защиту базы данных более эффективной: защита информации (файл с таблицами) и защита объектов и программ (файл с объектами и модулями).
Объекты БД
Таблица.В СУБД вся информация хранится в таблицах. Это базовый объект БД, все остальные объекты создаются на основе существующих таблиц (производные объекты). Каждая строка в таблице — запись БД, а столбец — поле. Запись содержит набор данных об одном объекте, а поле — однородные данные обо всех объектах.
Запросы.В СУБД запросы являются важнейшим инструментом. Они служат для выборки записей, обновления таблиц и включения в них новых записей. С помощью запросов можно просматривать и изменять данные из нескольких таблиц. Они также используются в качестве источника данных для форм и отчетов. Но главное предназначение запросов — это отбор данных на основании критериев и математическая обработка данных (вычисляемые поля). В любой момент можно выбрать из БД необходимую информацию и создать вычисляемое поле. Запрос — производный объект БД.
Формы.Они предназначены для ввода данных в таблицу, для открытия других форм и отчетов (кнопочные формы), а также с их помощью можно ограничить объем информации, доступной пользователям, обращающимся к БД (маска). Другими словами, форма представляет собой бланк, подлежащий заполнению, или маску, накладываемую на набор данных. Большая часть данных, представленных в форме, берется из таблицы или запроса. Другая информация, не связанная ни с таблицей, ни с запросом, хранится в макете формы (например, кнопки, вычисляемые поля и т. п.). Форма также является производным объектом БД.
Отчеты.Они служат для отображения итоговых данных из таблиц и запросов в удобном для просмотра виде. В отчетах, так же, как и в формах, часть данных берется из таблицы и запроса, другая часть информации хранится в макете отчета. Отчет — производный объект БД.
Разработчик— это человек (опытный пользователь или программист), которой самостоятельно создает новую БД. Прежде, чем приступить к созданию БД, необходимо продумать ее проект.
Проект— это абстрактная (теоретическая) модель будущей БД, состоящая из объектов и их связей, необходимых для выполнения поставленных задач.
Процесс проектирования включает, прежде всего, создание структуры таблиц, установку связей между этими таблицами, создание производных объектов (запросы, формы, отчеты, макросы, модули).
Компьютерные телекоммуникации: назначение, структура. Информационные ресурсы в телекоммуникационных сетях. Комплексы аппаратных и программных средств организации компьютерных сетей. Представления о телекоммуникационных службах: электронная почта, чат, телеконференции, форумы, Интернет-телефония. Информационно-поисковые системы. Организация поиска информации в сетях.
Одной из наиболее полезных возможностей, предоставляемых современным компьютером, является возможность использования его для автоматизированного обмена информацией с другими компьютерами по линиям связи. Реализуется эта возможность с помощью компьютерных сетей — объединений компьютеров.
Под компьютерной телекоммуникационной (вычислительной)сетью понимается программно-аппаратный комплекс, обеспечивающий автоматизированный обмен данными между компьютерами по линиям связи. Любые информационные ресурсы в том или ином виде можно передавать по сети. Современная сеть, состоящая из компьютеров (возможно специализированных), представляет собой некий комплекс узлов и каналов связи — аппаратуры и программ, обеспечивающих прием и передачу данных.
Большая часть возможностей, обеспечиваемых современными телекоммуникационными сетями, опирается на то, что эти сети могут обмениваться данными между собой, создавая межсетевую среду. Самое крупное такое объединение общедоступных сетей — это межсетевая среда Интернет (Internet).
Огромная распространенность сетей, их многофункциональность, в первую очередь, опираются на ряд принципов, соблюдение которых обеспечивает:
• открытость, т. е. возможность разработки различных сетевых приложений, в том числе не предусмотренных ранее;
• использование для обмена данными сетей на базе различных технологий, с самыми разными каналами связи;
• возможность подключения новых абонентов и новых сетей, а также расширения существующих без принципиальной перестройки;
• возможность обеспечения автоматического перепланирования схемы обмена (изменение маршрутизации) при возникновении технической необходимости (например, отказе канала связи);
• контроль обмена данными и минимизацию потерь в случае возникновения ошибок.
Основным принципом, лежащим в основе современных телекоммуникационных сетей, является принцип пакетной коммутации.
Этот принцип состоит в том, что для доставки данные разбиваются на независимые фрагменты (пакеты), каждый пакет снабжается служебной информацией и передается отдельно от других пакетов. Итоговое сообщение (последовательность пакетов) восстанавливается при необходимости в конечной точке.
Основой конструирования и функционирования современных сетей являются их модели. Модель сети— это схема разделения функций между компонентами сети, определяющая основы их взаимодействия.
В основе Интернета лежит сетевая модель DOD(Department of Defence, министерство обороны США). Эта модель подразумевает, что все функции делятся на четыре уровня — от непосредственных клиентских программ до средств обмена сигналами. За каждым уровнем закреплены определенные задачи, выполняя их, уровень обменивается данными только с выше- и нижележащими уровнями.
С логической точки зрения каждый уровень одного узла посылает данные такому же уровню другого узла.
За каждым уровнем закреплены следующие функции: 1. За уровнем доступа к среде — функции приема и передачи сигналов, преобразования их в цифровую форму и/или перекодирование. Этот уровень характеризует каждую сетевую технологию, применяемую для создания отдел: чой сети. Именно здесь осуществляется фактические прием и передача сигнала.
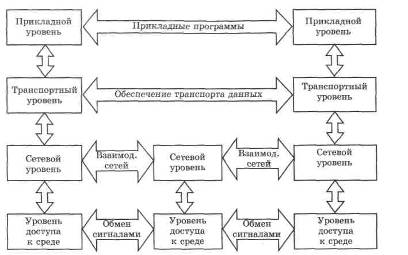
2. За сетевым уровнем закреплены функции организации межсетевого взаимодействия, он связывает отдельные сети. Протоколы этого уровня определяют маршруты следования пакетов (т. е. выполняют операцию перенаправления пакетов из одной сети в другую) и обмениваются необходимой технической информацией о пересылке. Узлы, выполняющие пересылку, называются шлюзами; выполняющие обработку пакетов и маршрутизацию, — маршрутизаторами. У таких специализированных узлов могут не задействоваться другие уровни, кроме первых двух.
3. За транспортным уровнем — задачи транспорта данных. Этот уровень связывает между собой программы, запущенные на конкретных узлах, т. е. позволяет определить, какая конкретно программа должна обработать полученный поток данных или обеспечить программе возможность отправки данных. Некоторые протоколы этого уровня позволяют также определять, получены ли отправленные данные.
4. К прикладному уровню отнесены все программы, взаимодействующие с пользователем и формирующие поток данных для обмена.
Основным набором протоколов, реализующих эту модель и обеспечивающим работу среды Интернет, является стек протоколов TCP/IP.Этот набор протоколов не предусматривает никаких стандартов на уровень доступа к среде, что позволяет использовать любые каналы передачи данных. Стек протоколов предусматривает механизм, позволяющий разрабатывать различные сетевые приложения и использовать для их работы существующую инфраструктуру без модернизации. На основе этого стека протоколов уже разработано большое количество программ, реализующих разнообразные сервисы (службы, программы для предоставления специализированных услуг).
Большинство телекоммуникационных служб предполагают обмен данными между двумя основными типами программ: клиентом(программа, взаимодействующая с пользователем) и сервером(программа, обслуживающая запросы).
Наиболее популярны следующие сетевые службы:
1. Служба электронной почты.Этот сервис позволяет обмениваться сообщениями в асинхронном режиме, т. е. отправить сообщение можно даже если адресат не работает с сетью в момент отправки и получит его только через некоторое время. Основу инфраструктуры электронной почты составляют почтовые отделения — серверы, принимающие почту и обрабатывающие ее (либо пересылая, либо помещая в хранилище до обращения пользователя). Индивидуальный «раздел» пользователя в такой системе называется почтовым ящиком.Для обращения к содержимому своего почтового ящика или при отправке новой почты пользователь должен использовать специальную программу-клиент. Во многих случаях этот клиент реализован как web-приложение.
2. Служба World Wide Web(Всемирная паутина). В этой службе информация представляется в виде отдельных объектов, связанных между собой. Структура такого рода называется гипертекстом. Для описания отдельных объектов и связей между ними применяется специальный язык разметки гипертекста — HTML. Основу функционирования этой службы составляют программы, выдающие объекты-страницы (и/или их составляющие) по запросу клиента (web-серверы), и программы, демонстрирующие полученные страницы (браузеры). Содержимое такой страницы может быть подготовлено заранее, а может быть создано WEB-cep-вером по запросу, с помощью специальных программ. Это позволяет применять эту службу как универсальное средство создания интерфейсов к большинству других служб, а также как средство создания специализированных приложений.
В качестве примера таких приложений можно привести форумы (приложения, в которых посетители обмениваются мнениями по различным вопросам, оставляя в выделенных разделах, хранящихся в БД на серверах, свои комментарии), чаты (приложения, позволяющие организовать беседу в режиме реального времени, непосредственно передавая всем пользователям отправляемые каждым сообщения). 3. Телеконференции и Интернет-телефония.Эти сервисы опираются на возможность передавать по сети потоки (т. е. не сообщения фиксированной длины, а некоторое количество данных за определенное время) аудио- и видеоинформации. С помощью телеконференций организуется обсуждение в режиме реального времени (это проще и эффективнее во многих случаях чатов и пр.), а с помощью Интернет-телефонии — передача звуковой информации телефонной сети между узлами Интернет в виде потока IP-пакетов. Такими узлами могут быть специальные телефонные станции или просто компьютеры. Передача такого потока обходится значительно дешевле междугородного канала связи.
Служба WWW, выполняя роль универсального интерфейса к большей части современных сетевых служб, позволяет добиться сходства в представлении информации из самых разных источников.
Тем не менее, поскольку сам язык подготовки страниц ориентирован на оформление текста (а не на отражение его логической структуры), и в каждом конкретном случае авторы отдельных наборов страниц сами принимают решение о том, что и как отображать на своих страницах, не уведомляя об этом никого, то возникает проблема поиска информации в среде Интернет. С ростом общего количества страниц и объема представленной в такой форме информации, эта проблема становится все острее.
Для поиска нужной информации в среде Интернет применяют несколько способов:
1. Применение классификации и каталогизации. В соответствии с этим подходом создаются специальные ресурсы-рубрикаторы, на которых аннотированные ссылки разносят по некоторым категориям. Поиск информации в этом случае осуществляется постепенным уточнением области до тех пор, пока набор страниц не будет сокращен до обозримого минимума. К сожалению, сам поисковый рубрикатор должен пополняться с помощью людей. В результате, в таких рубрикаторах просто не упомянуто подавляющее большинство страниц.
2. Применение методов полнотекстового поиска и поиска по ключевым словам. В этом случае автоматизированными средствами готовится поисковый индекс — фактически, база данных, содержащая информацию о наполнении страниц. Пользователь, обращаясь к этому индексу, просит найти страницу, на которой содержатся определенные слова. Постепенно уточняя область поиска, снова получаем обозримый набор документов. Поисковый индекс формируется, в основном, автоматически, что резко увеличивает количество участвующей в поиске информации. К сожалению, это также увеличивает и количество «мусора», попадающего в результаты обработки запросов. Для борьбы с этим применяют систему ранжирования результатов на основе релевантности — некоторого вычисленного коэффициента «соответствия» найденной страницы запросу.
3. Поиск информации в специализированных источниках. Если точно известна область поиска, то вполне возможно, что существуют специализированные хранилища информации, имеющие специально разработанные поисковые системы. Такая система позволит найти нужное существенно быстрее, чем использование поисковых систем общего назначения.
Дата добавления: 2016-02-16; просмотров: 10197;