Критерии распознавания открытого текста.
Строятся на основе моделей открытого текста двумя методами:
· на основе различения статистических гипотез;
· на основе ограничений по запретным или ожидаемым сочетаниям букв (ЪЪ и прочие).
Первый подход:
Открытый текст – реализация независимых испытаний случайной величины, значениями которой являются буквы алфавита A = {a1,…,an}, появляющиеся в соответствии с распределением вероятностей P(A) = (p(a1),…, p(an)). Требуется определить, является ли случайная последовательность c1c2…cl букв алфавита A открытым текстом или нет.
Пусть H0 – гипотеза, состоящая в том, что данная последовательность – открытый текст, H1 – альтернативная гипотеза. В простейшем случае последовательность c1c2…cl можно рассматривать при гипотезе H1 как случайную и равновероятную либо реализация независимых испытаний некоторой случайной величины, значениями которой являются буквы алфавита A = {a1,…,an}, появляющиеся в соответствии с распределением вероятностей Q(A) = (q(a1),…, q(an)).
Наиболее мощный критерий различения двух простых гипотез – лемма Неймана-Пирсона. Также может использоваться и теорема Фробениуса.
Возможны ошибки двух родов:
Ø ошибка первого рода (открытый текст принят за случайный набор знаков) ее вероятность 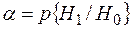 ;
;
Ø ошибка второго рода (случайный набор знаков принимается за открытый текст) ее вероятность 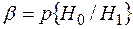 .
.
Второй подход:
Критерий запретных m-грамм. Устроен просто. Отбирается некоторое число s редких m-грамм, которые объявляются запретными. Теперь последовательно просматривая все m-граммы анализируемой последовательности c1c2…cl , мы объявляем ее случайной как только в ней встретится одна из запретных k-грамм. Весьма эффективны не смотря на простоту.
Распознавание открытого текста производится также на основе особенностей нетекстовых сообщений (файловые метки и пр.).
Дата добавления: 2016-02-13; просмотров: 1552;