Проблема непротиворечивости формализованной базы знаний
При добавлении информации от экспертов в базу знаний, необходимо обеспечить непротиворечивость базы знаний. Непротиворечивость означает, что в базе знаний не выводимы никакие два факта (формулы) вида а и 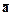 (из которых один отрицает другой). Проблема непротиворечивости не является тотальной, т.е. вполне допустимы противоречивые системы, однако, нужно иметь в виду следующее.
(из которых один отрицает другой). Проблема непротиворечивости не является тотальной, т.е. вполне допустимы противоречивые системы, однако, нужно иметь в виду следующее.
Во-первых, практически многие хорошо разработанные теории вывода работают с непротиворечивыми системами формул. Действительно, если система противоречива, то в ней выводимо все что угодно! Это обстоятельство практически лишает смысла само понятие вывода в противоречивой системе. В такой системе, следовательно, вывод заменяется иными механизмами (например, механизмами классификации - распознавания и принятия решений).
Во-вторых, сам характер задачи, стоящей перед СИИ, не допускает противоречивого толкования знаний (например, заключения 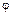 : "пациента нужно немедленно прооперировать" и
: "пациента нужно немедленно прооперировать" и 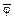 : "пациента не нужно немедленно оперировать" таковы, что неясность в смысле их выбора может стоить жизни человеку. (Такова, к примеру, фабула романа А. Хейли "Окончательный диагноз").
: "пациента не нужно немедленно оперировать" таковы, что неясность в смысле их выбора может стоить жизни человеку. (Такова, к примеру, фабула романа А. Хейли "Окончательный диагноз").
В формальных логических системах первого порядка противоречивость эквивалентна выводимости в системе пустой формулы (интерпретируемой как ложь).
Неизбыточность. Требование незбыточности означает, что в базе знаний хранятся лишь независимые друг от друга знания. Формула зависима от формул x1, x2, ..., xk, если выводима из x1, x2, ..., xk в силу правил вывода. Неизбыточность знаний не является императивным требованием. Фактически, избыточность имеет сильный положительный момент, который заключается в следующем.
Пусть СИИ в результате доказательства цели построила цепочку
Пi1, Пi2, Пi3, ..., Пi n-1
C0 ® C1 ® C2 ® ... ® Cn,
где Сk - k-ый контекст вывода (k-ое состояние трассы вывода); Пij - правило вывода (продукция), применяемое к контексту Сj-1.
Это позволяет ввести в базу знаний новую продукцию
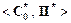 ,
,
где является выводом по образцу из С0 и Сi1 (Ci1 - условная часть продукции Пi1 ),
П* = <Пi1, Пi2, ..., Пi n-1> - представляет последовательную цепочку операционных частей продукций Пi1, Пi2, ..., Пi n-1.
Добавление продукции в базу знаний при следующем решении задачи < 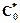 , Cn - ?> избавит от необходимости строить план решения задачи снова, т.е. приводит к увеличению быстродействия СИИ. Рассмотрим, как определяется зависимость формул в логике высказывании, являющейся той частью логики предикатов, которая позволяет формализовать фактуальные знания (т.е. знания, представленные совокупностью фактов). Итак, пусть требуется установить выводимость пропозициональной формулы G, представленной в виде
, Cn - ?> избавит от необходимости строить план решения задачи снова, т.е. приводит к увеличению быстродействия СИИ. Рассмотрим, как определяется зависимость формул в логике высказывании, являющейся той частью логики предикатов, которая позволяет формализовать фактуальные знания (т.е. знания, представленные совокупностью фактов). Итак, пусть требуется установить выводимость пропозициональной формулы G, представленной в виде
G = g1 Ú g2 Ú g3 Ú ... Ú gm, (1.41)
где gi - формулы (гипотезы), взятые с отрицанием или без него, из формулы F произвольного вида, т.е. доказать справедливость:
F ® g1 Ú g2 Ú g3 Ú ... Ú gm, (1.42)
Суть предлагаемого метода заключается в последовательном умножении обеих частей (1.42) на 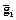 ,
, 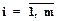 . Например, в порядке возрастания индекса i, пока не будет получена одна из следующих ситуаций:
. Например, в порядке возрастания индекса i, пока не будет получена одна из следующих ситуаций:
(a1) F* ® ð
(a2) F* ® F* (ð®ðили F* ® 1)
(a3) ð® F*,
где ð - символ пустой формулы, ð = х & 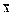 ; F - непустая формула формальной системы.
; F - непустая формула формальной системы.
Тогда справедливы следующие заключения:
Ситуация (а1) означает невыводимость G из F (G не находится в отношении логического следствия из F);
Ситуация (а2 и а3) означает, что G логически следует из F, 1 = х Ú .
Таким образом, для доказательства произвольной формулыF ® G, ее необходимо привести к виду (1.42) и выполнить описанную процедуру, доказательство которой здесь опускается.
Пример. Пусть даны формулы
f1 = a ® b&c& 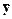 ,
,
f2 = b ® 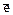 &f,
&f,
f3 = c Ú ® x Ú y.
Покажем, что имеет место
a&f1&f2&f3 ® x.
Умножим обе части нах:
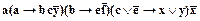 ®ð.
®ð.
Заменим (p ® q) на 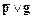 :
:
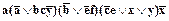 ®ð.
®ð.
Откуда, раскрывая скобки, имеем
ð ®ð,
что устанавливает доказываемое соотношение.
С другой стороны, отношение
a&f1&f2&f3 ® y
невыводимо, поскольку имеет место:
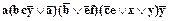 ®ð.
®ð.
Или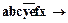 ð.
ð.
Итак, проблема избыточности решается с помощью механизма вывода.
Обучение системы
Как уже отмечалось, более менее развитая техника обучения имеется для задач распознавания и классификации. Задача классификации заключается в отнесении предъявленного образца к некоторому классу. В качестве классифицирующей функции может, например, использоваться функция
g(x) = w1x1 + w2x2 + ... + wdxd + wd+1, (1.43)
Данная функция называется также линейной дискриминаторной функцией. Для того, чтобы использовать линейную дискриминаторную функцию, исходное множество cобъектов разбивается на классы c1, c2, ..., cN, причем каждый объект из cпринадлежит только одному классу ci.
Для каждого класса некоторым (определенным) образом подбираются весовые коэффициенты W = <w1, w2, ..., wd+1>. Считается, что предъявленный объект относится к тому классу, для которого значение дискриминаторной функции достигает максимального значения. Рассмотрим, из каких соображений определяются весовые коэффициенты wi. Прежде всего, для каждого класса выбирается представитель Рi этого класса.
Расстояние между произвольной точкой X d-мерного пространства и представителем Рi, вычисляется как
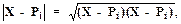 (1.44)
(1.44)
где(Х - Рi )(Х - Рi) = Х·Х - 2Х · Рi + Рi · Pi. (1.45)
Естественно полагать, что точка X принадлежит тому классу, расстояние между представителем которого Рi иX минимально. Поскольку член X×X в (1.45) для всех классов один и тот же, то минимум (-2ХРi + Рi Рi) эквивалентен максимуму(2ХРi - РiРi). В связи с этим в качестве gi(Х) используется функция
gi(X) = 2X×Pi - Pi×Pi. (1.46)
Из (1.46) имеем, что 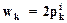 где
где 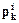 - i-ая компонента вектораРi и wd+1 = Pi×Pi.
- i-ая компонента вектораРi и wd+1 = Pi×Pi.
Теперь выясним, в чем заключается процесс обучения. Если заранее не известен представитель каждого класса, то нужно определить подходящим образом весовые коэффициенты wi, в дискриминантной функции (1.43). Определение весовых коэффициентов осуществляется с помощью обучающей выборки, относительно которой известна результирующая классификация. В качестве обучающей выборки для СИИ может выступать накопленный опыт решения задач классификации. Рассмотрим алгоритм непараметрического обучения, как он описан. В качестве начальных весов выбираются произвольные векторы, изменение которых производится только в случае неправильной классификации объектов. Допустим, при классификации объекта Y он неверно относится к классу ), вместо отнесения его к классу 1. Тогда весовые векторы, используемые как в 1-ой, так и в 1-ой дискриминантных функциях, изменяются следующим образом:
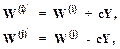 (1.47)
(1.47)
где 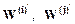 - новые весовые выходы; с - коэффициент коррекции.
- новые весовые выходы; с - коэффициент коррекции.
Таким образом, исправление состоит в увеличении дискриминантной функции W(i) и уменьшении дискриминантной функции W(i). Также доказывается, что приведенный обобщенный алгоритм обучения находит разделяющие весовые наборы за конечное число исправлений.
Отметим в заключении этого параграфа, что обучение может быть связано также с выдвижением гипотез и методами индуктивных рассуждений. Соответствующие формализмы были предложены в начале века Д.С.Миллем.
Дата добавления: 2016-03-05; просмотров: 1395;