Микросхемы памяти в составе микропроцессорной системы
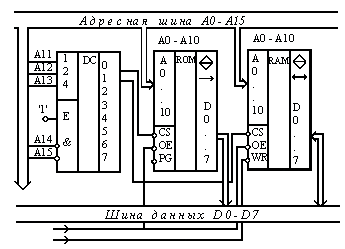
Рис. 4.11. Микросхемы ОЗУ (К573РУ9) и ППЗУ (К573РФ5) в составе микропроцессорной системы.
На рис. 4.11 представлено взаимодействие К573РФ2(5) и К573РУ9, имеющих одинаковую организацию 2Кx8, с системной магистралью. Байт данных с шины данных (линии D0-D7) считывается (или записывается) по адресу, выставленному на шине адреса (линии A0-A10). Естественно, число адресуемых ячеек составляет 211=800h=2048. Микросхема-дешифратор К555ИД7 посредством сигнала CS# (выбор кристалла) позволяет выбрать положение ИМС ЗУ в адресном пространстве. Для данного случая это адреса 0000h-07FFh для ПЗУ(ROM) и 0800h-0FFFh для ОЗУ(RAM). Низкий уровень сигналов управления MEMW# и MEMR# активизирует процесс записи и чтения, соответственно. Напомним, что запись информации в данную ИМС ППЗУ возможен только вне микропроцессорной системы в специальном программаторе после УФ стирания путем подачи достаточно высокого напряжения на вход PG.
Аналогично можно проследить и взаимодействие программируемых ИМС параллельного интерфейса и программируемого таймера, служащих для взаимодействия МП с внешними устройствами. На рис. 4.12 они обозначены как PI и T. Регистры этих микросхем также доступны пользователю для чтения/записи, как и ячейки основной памяти. Однако их активизируют другие сигналы управления IOR# и IOW# (запись в порты ввода/вывода).
Микросхема КР580ВВ55А (аналог Intel 8255А) позволяет переключать шину данных компьютера на один из трех 8-битных портов (регистров) A, B или C. Направление передачи данных и режим работы (0-2) определяются программным способом. Чаще других используется режим 0: простой ввод-вывод. Состояние адресных линий А0 и А1 позволяет выбрать для обмена информацией регистры A, B, C или регистр управления. Режим работы параллельного интерфейса КР580ВВ55А определяется байтом, записанным в регистр управления. При работе на вывод порты A, B, C действуют как регистры, т.е. сохраняют информацию до следующей записи; при работе на ввод информация теряется. Порт С, в отличие от портов A и B, разбит на полубайты и может программироваться раздельно, т.е. мы имеем группы A и B.
В дополнение к основным режимам работы микросхема КР580ВВ55А обеспечивает возможность программной независимой установки/сброса любого бита (порт С), в этом случае старший бит в регистре управления должен быть 0.
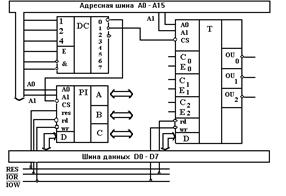
Рис. 4.12. Пример взаимодействия программируемых ИМС параллельного порта (PI) КР580ВВ55А и таймера (T) КР580ВИ53 с системной магистралью компьютера; DC - дешифратор К555ИД7.
Интегральная схема КР580ВИ53 создана по n-МОП технологии, Uпит=+5 В, U1>2.4 В, U0<0.45 В, P=1 Вт, fтакт <2 МГц, 24 вывода, максимальное значение счета: 216 - в двоичном коде и 104 - в двоично-десятичном. Программируемый таймер КР580ВИ53 реализован в виде трех независимых 16-разрядных вычитающих счетчиков (каналов) с общей схемой управления. Каждый канал может работать в шести режимах. Программирование режимов работы каналов осуществляется индивидуально и в произвольном порядке путем ввода управляющих слов в регистры режимов каналов, а в счетчики - некоторого числа байт. На рис. 4.12 можно видеть, что таймер обменивается информацией с 8-битной шиной данных микропроцессорной системы через вход D, а также он связан с адресной шиной двумя линиями А0-А1, обеспечивающими выбор одного из четырех регистров (3 канала и управляющее слово). Сигналы шины управления IOR# и IOW# (чтение/запись из/во внешнее устройство) определяют направление потока информации от процессора к таймеру и наоборот. С0, С1, С2 - тактовые входы, сигналы на Е0, Е1, Е2 - разрешают или запрещают работу соответствующего канала, OU0, OU1, OU2 - выходы.
Буферная память
В вычислительных системах используются подсистемы с различным быстродействием, и, в частности, с различной скоростью передачи данных (рис. 4.13). Обычно обмен данными между такими подсистемами реализуется с использованием прерываний или канала прямого доступа к памяти. В первую очередь подсистема 1 формирует запрос на обслуживание по мере готовности данных к обмену. Однако обслуживание прерываний связано с непроизводительными потерями времени и при пакетном обмене производительность подсистемы 2 заметно уменьшается. При обмене данными с использованием канала прямого доступа к памяти подсистема 1 передает данные в память подсистемы 2. Данный способ обмена достаточно эффективен с точки зрения быстродействия, но для его реализации необходим довольно сложный контроллер прямого доступа к памяти.
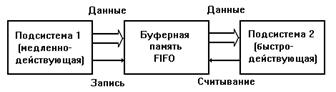
Рис. 4.13. Применение буферной памяти.
Наиболее эффективно обмен данными между подсистемами с различным быстродействием реализуется при наличии между ними специальной буферной памяти. Данные от подсистемы 1 временно запоминаются в буферной памяти до готовности подсистемы 2 принять их. Емкость буферной памяти должна быть достаточной для хранения тех блоков данных, которые подсистема 1 формирует между считываниями их подсистемой 2. Отличительной особенностью буферной памяти является запись данных с быстродействием и под управлением подсистемы 1, а считывание - с быстродействием и под управлением подсистемы 2 ("эластичная память"). В общем случае память должна выполнять операции записи и считывания совершенно независимо и даже одновременно, что устраняет необходимость синхронизации подсистем. Буферная память должна сохранять порядок поступления данных от подсистемы 1, т.е. работать по принципу "первое записанное слово считывается первым" (First Input First Output - FIFO). Таким образом, под буферной памятью типа FIFO понимается ЗУПВ, которое автоматически следит за порядком поступления данных и выдает их в том же порядке, допуская выполнение независимых и одновременных операций записи и считывания. На рис. 4.14 приведена структурная схема буферной памяти типа FIFO емкостью 64x4.
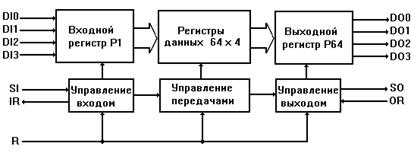
Рис. 4.14. Структурная схема буфера 64x4.
На кристалле размещены 64 4-битных регистра с независимыми цепями сдвига, организованных в 4 последовательных 64-битных регистра данных, 64-битный управляющий регистр, а также схема управления. Входные данные поступают на линии DI0-DI3, а вывод данных осуществляется через контакты DO0-DO3. Ввод (запись) данных производится управляющим сигналом SI (shift in), а вывод (считывание) - сигналом вывода SO (shift out). Ввод данных осуществляется только при наличии сигнала готовности ввода IR (input ready), а вывод - при наличии сигнала готовности вывода OR (output ready). Управляющий сигнал R (reset) производит сброс содержимого буфера.
При вводе 4-битного слова под действием сигнала SI оно автоматически передвигается в ближайший к выходу свободный регистр. Состояние регистра данных отображается в соответствующем ему управляющем триггере, совокупность триггеров образует 64-битный управляющий регистр. Если регистр содержит данные, то управляющий триггер находится в состоянии 1, а если регистр не содержит данных, то триггер находится в состоянии 0. Как только управляющий бит соседнего справа регистра изменяется на 0, слово данных автоматически сдвигается к выходу. Перед началом работы в буфер подается сигнал сброса R и все управляющие триггеры переводятся в состояние 0 (все регистры буфера свободны). На выводе IR формируется логическая 1, т.е. буфер готов воспринимать входные данные. При действии сигнала ввода SI входное слово загружается в регистр P1, а управляющий триггер этого регистра устанавливается в состояние 1: на входе IR формируется логический 0. Связи между регистрами организованы таким образом, что поступившее в P1 слово "спонтанно" копируется во всех регистрах данных FIFO и появляется на выходных линиях DO0-DO3. Теперь все 64 регистра буфера содержат одинаковые слова, управляющий триггер последнего регистра P64 находится в состоянии 1, а остальные управляющие триггеры сброшены при передаче данных в соседние справа регистры. Состояние управляющего триггера P64 выведено на линию готовности выхода OR; OR принимает значение 1, когда в триггер записывается 1. Процесс ввода может продолжаться до полного заполнения буфера; в этом случае все управляющие триггеры находятся в состоянии 1 и на линии IR сохраняется логический 0.
При подаче сигнала SO производится восприятие слова с линий DO0-DO3, управляющий триггер P64 переводится в состояние 1, на линии OR появляется логическая 1, а управляющий триггер P64 сбрасывается в 0. Затем этот процесс повторяется для остальных регистров и нуль в управляющем регистре перемещается ко входу по мере сдвига данных вправо.
В некоторых кристаллах буфера FIFO имеется дополнительная выходная линия флажка заполнения наполовину. На ней формируется сигнал 1, если число слов составляет более половины емкости буфера.
Рассмотренный принцип организации FIFO допускает выполнение записи и считывания данных независимо и одновременно. Скорость ввода определяется временным интервалом, необходимым для передачи данных из P1, а выводить данные можно с такой же скоростью. Единственным ограничением является время распространения данных через FIFO, равное времени передачи входного слова на выход незаполненного буфера FIFO. Оно равняется произведению времени внутреннего сдвига и числа регистра данных. В буферах FIFO, выполненных по МОП-технологии и имеющих емкость 64 слова, время распространения составляет примерно 30 мкс, а в биполярных FIFO такой же емкости - примерно 2 мкс.
Буферы можно наращивать как по числу слов, так и по их длине.
Стековая память
Стековой называют память, доступ к которой организован по принципу: "последним записан - первым считан" (Last Input First Output - LIFO). Использование принципа доступа к памяти на основе механизма LIFO началось с больших ЭВМ. Применение стековой памяти оказалось очень эффективным при построении компилирующих и интерпретирующих программ, при вычислении арифметических выражений с использованием польской инверсной записи. В малых ЭВМ она стала широко использоваться в связи с удобствами реализации процедур вызова подпрограмм и при обработке прерываний.
Принцип работы стековой памяти состоит в следующем (см. рис. 4.15). Когда слово А помещается в стек, оно располагается в первой свободной ячейке памяти. Следующее записываемое слово перемещает предыдущее на одну ячейку вверх и занимает его место и т.д. Запись 8-го кода, после H, приводит к переполнению стека и потере кода A. Считывание слов из стека осуществляется в обратном порядке, начиная с кода H, который был записан последним. Заметим, что выборка, например, кода E невозможна до выборки кода F, что определяется механизмом обращения при записи и чтении типа LIFO. Для фиксации переполнения стека желательно формировать признак переполнения.
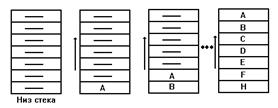
Рис. 4.15. Принцип работы стековой памяти.
Перемещение данных при записи и считывании информации в стековой памяти подобно тому, как это имеет место в сдвигающих регистрах. С точки зрения реализации механизма доступа к стековой памяти выделяют аппаратный и аппаратно-программный (внешний) стеки.
Аппаратный стек представляет собой совокупность регистров, связи между которыми организованы таким образом, что при записи и считывании данных содержимое стека автоматически сдвигается. Обычно емкость аппаратного стека ограничена диапазоном от нескольких регистров до нескольких десятков регистров, поэтому в большинстве МП такой стек используется для хранения содержимого программного счетчика и его называют стеком команд. Основное достоинство аппаратного стека - высокое быстродействие, а недостаток - ограниченная емкость.
Наиболее распространенным в настоящее время и, возможно, лучшим вариантом организации стека в ЭВМ является использование области памяти. Для адресации стека используется указатель стека, который предварительно загружается в регистр и определяет адрес последней занятой ячейки. Помимо команд CALL и RET, по которым записывается в стек и восстанавливается содержимое программного счетчика, имеются команды PUSH и POP, которые используются для временного запоминания в стеке содержимого регистров и их восстановления, соответственно. В некоторых МП содержимое основных регистров запоминается в стеке автоматически при прерывании программ. Содержимое регистра указателя стека при записи уменьшается, а при считывании увеличивается на 1 при выполнении команд PUSH и POP, соответственно.
Иерархия ЗУ
К числу основных требований, предъявляемых к ЗУ стационарных ЭВМ, относятся: большая емкость, рассчитанная на хранение десятков миллионов чисел и команд; высокое быстродействие, соответствующее скорости работы арифметическо- логического блока ЭВМ; приемлемые стоимость, габариты, масса, потребляемая мощность.
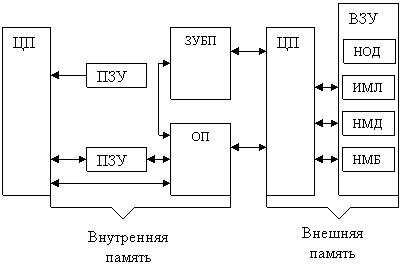 Техническая реализация этих требований возможна путем организации иерархической структуры памяти ЭВМ, объединяющей ЗУ различных типов, отличающихся по быстродействие и емкости.
Техническая реализация этих требований возможна путем организации иерархической структуры памяти ЭВМ, объединяющей ЗУ различных типов, отличающихся по быстродействие и емкости.
В структурном отношении память ЭВМ прежде всего делится на внутреннюю и внешнюю. Принадлежность ЗУ к внутренней или внешней памяти определяет способ обращения программ пользователей к этим ЗУ, а не технику их соединения между собой и с центральным процессором (ЦП). Например, накопитель на магнитных дисках (НМД), подсоединенный через канал, в одной ЭВМ будет выполнять функцию внутреннего, а в другой внешнего ЗУ.
Внутренняя память – совокупность ЗУ, к которым обращение программ пользователя производится непосредственно. К такми ЗУ относятся оперативные, сверхоперативные и постоянные ЗУ, а также локальная память.
Оперативные ЗУ (ОЗУ) служат для хранения операндов, программ, промежуточных и конечных результатов обработки информации, непосредственно используемых в процессе выполнения операций центральным процессором.
Дата добавления: 2016-02-20; просмотров: 1738;