Фонетическая и просодическая структуры речи. Распознавание речи
Фонема – минимальная смысловая единица речи. В русском языке 42 фонемы: 6 гласных и 36 согласных; в английском – 20 гласных и 24 согласных; во французском – 16 гласных и 20 согласных.
Аллофоны – оттенки фонем, появление которых обусловлено влиянием соседних фонем. Количество аллофонов гласных – 480, согласных – 8800.
Просодия речи – лингвистическое понятие, отображающее интонацию и ударение системы речевого общения. Она позволяет:
o определять коммуникативную направленность высказывания;
o определять логический смысл;
o выделять главное и общее;
o вычленять семантически связанные отрезки речи.
Интонация и ударение физически реализуются совокупностью акустических средств – просодических характеристик речи, к которым относятся:
o мелодика – изменение частоты основного тона голоса;
o ритмика – текущее изменение длительности звуков и пауз;
o энергетика – текущее изменение интенсивности звука.
Процесс чтения текста предполагает наличие процедуры формирования основного тона, интенсивности звука, длительности звуков и пауз на основе анализа входного текста. Преобразование текста в последовательность фонем должно сопровождаться выделением информации, необходимой для задания просодических характеристик речи.
Речевой аппарат человека представляется в виде двух параллельных каналов – ротового и носового, образующих единую акустическую систему, возбуждаемую периодическими колебаниями голосовых связок, либо турбулентным шумом. Распространение акустических волн в такой системе описывается уравнением Вебстера:
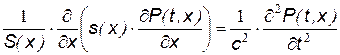 ,
,
где 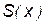 – функция площади сечения тракта вдоль оси
– функция площади сечения тракта вдоль оси 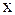 распространения волн,
распространения волн, 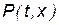 – акустическое давление, с – скорость звука, t – время.
– акустическое давление, с – скорость звука, t – время.
В результате решения уравнения получается аналитическое выражение для передаточной функции речевого тракта:
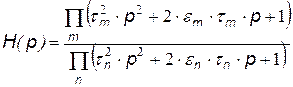 ,
,
где р – комплексная переменная, 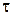 - постоянная времени,
- постоянная времени, 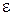 - коэффициент затухания. Такая формула соответствует произведению резонансных звеньев, каждое из которых соответствует определенной n-ной форманте и m-ной антиформанте речевого сигнала. Анализ передаточных функций речевого тракта показал, что достаточно полно описать акустические характеристики можно используя формантную модель, показанную на рис.29.1.
- коэффициент затухания. Такая формула соответствует произведению резонансных звеньев, каждое из которых соответствует определенной n-ной форманте и m-ной антиформанте речевого сигнала. Анализ передаточных функций речевого тракта показал, что достаточно полно описать акустические характеристики можно используя формантную модель, показанную на рис.29.1.
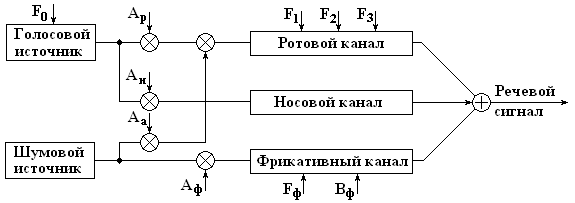
Рис.29.1. Формантная модель акустики речевого тракта
Основные параметры формантной модели:
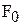 - частота основного тона,
- частота основного тона, 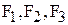 - частоты 1,2,3-й формант,
- частоты 1,2,3-й формант,
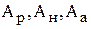 - амплитуды ротовых и носовых формант голосового возбуждения, амплитуда аспиративного возбуждения,
- амплитуды ротовых и носовых формант голосового возбуждения, амплитуда аспиративного возбуждения, 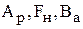 - амплитуда, частота и полоса пропускания фрикативных (губных) формант.
- амплитуда, частота и полоса пропускания фрикативных (губных) формант.
Приведенная модель используется в системах синтеза речи.
Трудности в распознавании речевых образов связаны с чрезвычайной изменчивостью основных характеристик речевого сигнала. Информационная структура речевого сигнала складывается из следующих групп элементов:
o элементы информационной структуры – смысловое содержание, физическое и эмоциональное состояние, индивидуальность голоса, характеристики среды;
o элементы слухового восприятия – фонемный состав, интонация, тембр, громкость, тон, темп;
o виды модуляции – спектральная, амплитудная, частотная, фазовая, широтная модуляция, манипуляция переносчиками;
o типы переносчиков – тональный, импульсный, шумовой.
Процесс передачи информации о фонемном составе связан с постоянной сменой комбинаций включения переносчиков, с изменением частоты основного тона на смычках звонких взрывных звуков.
Свойства речевой системы связи:
o В процессе речевого общения осуществляется параллельная передача различных видов информации.
o Для передачи каждого вида одновременно используется несколько видов модуляции.
o Все виды модуляции участвуют в процессе передачи информации.
Распознавание речевых сигналов требует применения разнообразных методов. Достаточно устойчивые образы слов позволяет получать частотно-временной алгоритм, пример работы которого представлен на рис.29.2.
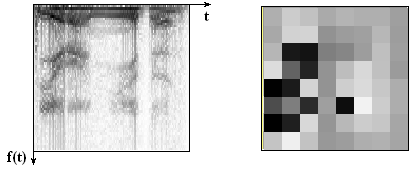
Рис.29.2. Частотно-временные образы слова «пирамида»
Алгоритм частотно-временного преобразования слов состоит из следующих этапов:
· Фонограмма равномерно разбивается на участки, имеющие одинаковую продолжительность, и которые могут перекрываться. Длина участков составляет 50-150 отсчетов фонограммы.
· На основе дискретного преобразования Фурье для каждого участка вычисляется спектр. Множество дискретных спектров образует матрицу, номера строк которой соответствуют номеру гармоники (частоте), а номер столбика – номеру отсчета (времени).
· Матрица разбивается на 64 (8х8) одинаковых квадратов. Внутри каждого квадрата значения гармоник усредняются, в результате чего формируется частотно-временной образ слова.
Частотно-временные образы не зависят от продолжительности и громкости произнесения слова, что делает их дикторо-независимыми объектами, из которых составляется база данных систем, способных устойчиво распознавать человеческую речь. Недостатком данного метода распознавания является обязательность раздельного произношения слов, что не всегда выполняется в «живой» речи.
Дата добавления: 2016-02-16; просмотров: 981;