При объединении в одну систему двух зависимых систем Х и У энтропия
этой системы: НDхDу(Х,У) = НDх(Х) + НDуDх(У/Х) (1 – 14)
При объединении двух независимых систем энтропия имеет вид:
НDхDу(Х,У) = НDх(Х) + НDу(У) (1 – 15)
Выражение полной взаимной информации, содержащейся в непрерывных
системах Х и У, имеет вид, аналогичный виду для дискретных систем. В этом
случае вероятности заменяются законами распределения, а суммы – интегра-
лами: Iу«х = - 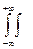 f(х,у) log f(х,у) / f1(х)f2(у) dxdу (1 – 16)
f(х,у) log f(х,у) / f1(х)f2(у) dxdу (1 – 16)
Следовательно, полная взаимная информация обращается в нуль, если сис-
темы Х и У независимы.
С помощью полной (средней) условной энтропии можно производить оцен-
ку количества информации при воздействии помех. Условная энтропия равна в этом случае количеству потери информации вследствие помех.
Использование информационных критериев обеспечивают возможность
анализировать и оценивать вероятностными методами погрешности измере-
ний в статических и динамических режимах, качество многоканальных изме-
рительных систем, надежность измерительных устройств, решать задачи по
поиску неисправности в них, а также ряд других вопросов, связанных с вос-
приятием, преобразованием и выдачей измерительной информации примени-
тельно к измерительному устройству или системе любого вида.
1.2. Виды информации.
Классификация (систематизация) информации, циркулирующей в любом
технологическом объекте, необходима для организации единой системы хра-
нения, накопления, отображения и управления.
Всю сформированную информацию можно разделить на входную, выход-
ную и промежуточную.
Входная информация представляет собой совокупность исходных данных,
необходимых для решения задач управления. К ним относятся все первичные
(априорные) данные, нормативно-справочная информация, а также промежу-
точные данные, полученные в результате решения других задач.
К выходной информации относится информация, получаемая как результат
решения задач управления, предназначенная для непосредственного исполь-
зования в формировании управляющего воздействия.
Промежуточная информация содержит результаты решения промежуточных
задач (например, результаты состояния полуфабрикатов), используемые в ка-
честве исходных данных при решении задач управления.
По способу обработки данных информация подразделяется на текстовую, алфавитную, цифровую, алфавитно-цифровую и графическую. Большое зна-
чение при машинной обработке информации имеет ее разделение по стабиль-
ности на переменную и постоянную.
Переменная информация отображает количественные и качественные харак-
теристики производственных процессов и событий. Переменная информация для каждого фиксируемого технологического процесса может изменяться как
по значениям данных, так и по их количественной величине. Переменная ин-
формация, как правило, участвует в одном цикле обработки сырья, поэтому
ее называют разовой.
Постоянная информация остается неизменной в течение длительного перио-
да и многократно используется в операциях.
В условиях функционирования систем управления постоянная информация должна быть записана на машинном носители. Это позволит создавать посто-
янно действующие массивы (банк) данных, участвующие в решении многих
задач управления.
Из всей совокупности информации, используемой при автоматизированной обработке данных, особенно выделяются нормативно-справочные данные (например, пищевая и энергетическая ценность сырья и продукта), которые в течение длительного времени остаются постоянными и многократно исполь-
зуются при решении различных задач управления.
Нормативно-справочная информация состоит из нормативных и справоч-
ных данных.
Нормативная информация характеризует удельные нормы и нормативы затрат материальных и трудовых ресурсов в единицу времени, на единицу
продукции, на определенный технологический процесс и т.п..
Материальные нормативы определяют расход сырья и материалов на изготовление изделия, трудовые нормативы-затраты труда (времени) на вы-
полнение определенной технологической операции (норма выработки на од-
ного работающего). Нормативная информация включает в себя: норму смен-
ности, запасов сырья и готовой продукции, нормативы незавершенного про-
изводства, оборотных средств и т.п..
Нормативная информация является базой для определения многих расчетов. В процессе развития производства (внедрение новой техники, новых техно-
логий производства) нормативные показатели не меняются. Однако в течение
длительного времени нормативная информация остается неизменной, что по-
зволяет, перенеся ее на машинные носители, многократно использовать ее при проведении различных расчетов.
Справочная информация характеризует отдельные параметры объектов уп-
равления, элементов материально-технической структуры производства и предметов труда.
При обработке на компьютерах нормативно-справочной информации необ-
ходимо, чтобы в различных формах документов повторяемость одних и тех же данных была минимальной, зафиксированные данные были удобно распо-
ложены для последующей машинной обработки; кроме данных для машин-
ной обработки содержалась дополнительная информация, необходимая для
осуществления управления технологическим процессом.
Различные виды информации можно разделить на две группы: статическую
и динамическую.
Так, числовая, логическая и символьная информация является статической – значение не связано со временем.
Вся аудиоинформация имеет динамический характер. Она существует толь-
ко в режиме реального времени, ее нельзя остановить. Если изменить масштаб времени, то аудиоинформация искажается.
Видеоинформация может быть как статической, так динамической.
Статическая информация включает тесты, рисунки, графики, чертежи, табли-
цы и др. Рисунки подразделяются на плоские – двухмерные и объемные – трехмерные.
Динамическая информация – это видео-, мульт-, и слайд- фильмы. В их осно-
ве лежит последовательное экспонирование на экране в реальном масштабе времени отдельных кадров в соответствии со сценарием. Динамическая ви-
деоинформация используется либо для передачи движущихся изображений
(анимация), либо для последовательной демонстрации отдельных кадров вы-
вода (слайд-фильмы). В современных высококачественных мониторах и в те-
левизорах с цифровым управлением электронно-лучевой трубкой кадры сменяются до 70 раз в секунду, что обеспечивает высококачественную пере-
дачу движения объектов.
1.3. Системы счисления информации.
Наименьшей единицей измерения информации является бит – двоичная еди-
ница информации, равная количеству информации, содержащемуся в элемен-
тарном сообщении, полученном в результате выбора одного из двух незави-
симых и равновероятных состояний при основании логарифма а = 2.
Адресуемой единицей информации является байт, которая содержит восемь
битов, что соответствует необходимому объему памяти компьютера для за-
писи одного десятичного числа или буквы слова в двоичной системе.
В практике находят применение производные единицы количества инфор-
мации: килобайт (1Кбайт = 103 байт); мегабайт (1Мбайт = 106 байт); гигабайт
(1Гбайт = 109 байт) и т.д., а также условная единица количества информации-
машинное слово – упорядоченная совокупность информации (сигналов, сим-
волов) с ограничениями в начале и конце слова. Оно имеет фиксированную
длину, но в разных случаях различную.
В компьютерных системах используют двоичную, восьмеричную, десятич-
ную, шестнадцатеричную и другие позиционные системы счисления. Обще-
принятая система счисления для современных компьютеров – двоичная.
Система счисления – способ изображения чисел с помощью ограниченного
набора символов, имеющих определенные количественные значения. Ее об-
разуют совокупностью правил и приемов представления чисел с помощью набора знаков (цифр).
Различают позиционные и непозиционные системы счисления. В позицио-
нных системах каждая цифра имеет определенный вес, зависящий от пози-
ции цифры в последовательности, изображающей число. Позиция цифры на-
зывается разрядом .
В позиционной системе счисления любое число можно представить в виде:
Аn = 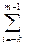 аi × Ni (1 – 17)
аi × Ni (1 – 17)
где: аi – i-я цифра числа; k – количество цифр в дробной части числа; m – ко-
личество цифр в целой части числа; N – основание системы счисления.
Основание системы счисления N показывает, во сколько раз “вес” i-го раз-
ряда больше (i – 1) разряда.
Во всех современных компьютерах для представления числовой информа-
ции используется двоичная система счисления.
При N=2 число различных цифр, используемых для записи чисел, ограни-
чено множеством из двух цифр (нуль и единица). Кроме двоичной системы
счисления широкое распространение получили и производные системы:
- двоичная - {0,1};
- десятичная, точнее двоично-десятичное представление десятичных
чисел, - {0,1,……, 9);
- шестнадцатеричная - {0,1,2,….., 9, А, В, С, Д, Е, F}. В ней цифра А обозна-
чает число 10, В – число 11,……., и F – число 15.
- восьмеричная - {0,1,2,3,4,5,6,7},
Восьмеричная и шестнадцатеричная системы счисления являются производ-
ными от двоичной, так как 16 = 24 и 8 = 23. Они используются в основном для
более компактного изображения двоичной информации, так как запись значе-
ния чисел производится существенно меньшим числом знаков.
В практике двоичная система является наиболее удобной формулой пред-
ставления информации в компьютерных системах. Один двоичный разряд ра-
вен одному биту. Для преобразования в двоичную систему любого числа в десятичную систему, то следует последовательно делить число в десятичной системе на основание новой системы, т.е. на 2, и выписать остатки, которые и составляют число в двоичной системе.
Представление чисел в различных системах счисления допускает однозна-
чное преобразование их из одной системы в другую. В компьютерах перевод из одной системы счисления в другую осуществляется автоматически по спе-
циальным программам.
1.4. Способы представления информации.
Для однозначного описания данных и обеспечения эффективного поиска и
идентификации в памяти компьютера используют соответствующие средства
классификации и кодирования.
Система классификации – совокупность правил и результат разделения за-
данного множества на подмножества (ГОСТ 17369-78).
Классификация – разделение заданного множества на подмножества согла- сно с принятыми методами классификации.
Подмножества, полученные в результате разделения заданного множества
по одному или нескольким признакам классификации, называют классифика-
ционными группировками. Классификационным группировкам в разных сис-
темах классификации присваивают различные наименования: классы, под-
классы; группы, подгруппы; виды, подвиды; роды, семейства, классы.
Признаком классификации называют признак, по которому делят заданное
множество на подмножества.
Ступень классификации – этап разделения заданного множества на подмно-
жества. Число ступеней классификации называют глубиной классификации.
После завершения классификации производят кодирование – образование
и присвоение обозначения объекту классификации, признаку классификации
и классификационной группировке. Это условное кодовое обозначение назы-
вают сокращенно кодом. Количество знаков в кодовом обозначении называ-
вают длиной кода.
Кодирование информации предусматривает: приведение к единообразию в
обозначениях признаков, характеристик и объектов в целом; упорядочение,
классификацию и группировку всех номенклатур по определенным сходным признакам; выбор системы кодирования и присвоение кодов; приведение ин-
формации к форме, удобной для обработки с помощью технических средств.
Коды и классификаторы должны удовлетворять двум взаимоисключающим условиям: с одной стороны, они должны обеспечивать реализацию всех задач
АСУ, быть общепринятыми и доступными, иметь необходимую резервную емкость на случай увеличения кодируемой информации; с другой стороны, кодовое обозначение должно иметь минимальную длину для снижения зат- рат машинного времени на передачу и переработку информации. При этом системы классификации и кодирования обычно дополняют системой защиты кодов, обеспечивающей контроль достоверности на входе и выходе инфор- мации. От рационального построения кодов и правильного составления клас- сификаторов в значительной степени зависит эффективность применения микропроцессорной техники. Выбор системы классификации и кодирования должен обеспечивать сопоставимость информации и совместимость АСУ.
Поддержание классификатора в выверенном состоянии, с учетом постоянно возникающих изменений и дополнений, называют ведением классификатора.
Системы классификации и кодирования информации разрабатывают в следу-
ющей последовательности: определяют полный перечень всех необходимых классификаторов; анализируют перечень классификаторов с точки зрения во-
зможности и необходимости применения в АСУ; устанавливают четкие гра- ницы каждого классификатора и полный перечень подлежащих классифика- ции объектов; определяют признаки классификации для разделения всего множества объектов на соответствующие группировки; проводят четкую систематизацию внутри каждого классифицируемого множества объектов; выбирают и определяют структуру кодов; осуществляют кодирование исход- ной информации; оформляют результаты кодирования, вносят необходимые исправления и изменения, устанавливают системы внесения изменений и до- полнений; разрабатывают инструкции по использованию полученных мате- риалов.
При разработке классификаторов и систем кодирования следует соблюдать
следующие основные требования:
1.Выбор кодов минимальной длины. Уменьшение длины кодов, особенно для часто используемых кодов, приводит к уменьшению количества ошибок при переносе информации на машинные носители и сокращению трудоемкости обработки;
2.Логичность и запоминаемость кодов. Удовлетворение данного требования помогает при освоении кодов, облегчает кодирование и уменьшает число до-
пускаемых ошибок;
3.Учет особенностей решаемых задач. Например, коды технологических опе-
раций должны содержать в явном виде порядок выполнения операций, ре-
жим работы, тип оборудования и другие технологические характеристики,
т.е. быть максимально информативными;
4.Учет существующей системы кодирования и общепринятых обозначений. Это требование позволяет облегчить разработку новой системы кодирования
информации АСУ и облегчить ее стыковку с существующей системой коди- дирования;
5.Учет перспектив развития. При разработке классификаторов и систем коди-
рования, коды должны составляться таким образом, чтобы обеспечить возмо-
жности изменения и резерв на случай появления новых объектов в системе.
6.Необходимость информационной стыковки с системами кодирования взаи-
модействующих АСУ, так как это важно для обеспечения информационного единства АСУ данного объекта с АСУ вышестоящего уровня и возможности межмашинного обмена информацией.
При разработке АСУ используют отраслевые, специальные, локальные клас-
сификаторы и другие отечественного и зарубежного производства. В этих случаях для представления информации в другие АСУ и организации необ- ходимо перекодирование данных, осуществляемое по перекодировочной таблице взаимного соответствия кодовых обозначений одноименных объектов и классификационных группировок в разных классификаторах.
При построении классификаторов используют иерархический или фасет-
ный методы классификации.
Иерархический метод классификации заключается в последовательном де- лении заданного множества на подчиненные подмножества, каждое в свою
очередь делится на подчиненные ему подмножества и т.д..
Фасетный метод классификации заключается в делении заданного множес-
тва на группировки независимо согласно различным признакам классификации.
Рассмотрим наиболее распространенные методы кодирования.
Порядковый метод кодирования – простейший метод кодирования, при ко-
тором кодовыми являются числа натурального ряда. Этот метод кодирования неудобен при ведении классификатора, когда необходимо вносить измене-
ния и исключения.
Серийно-порядковый метод кодирования, в котором кодовыми обозначени-
ями служат числа натурального ряда с закреплением отдельных диапазонов (серий) этих чисел за объектами классификации с одинаковыми признаками.
При этом новые кодовые обозначения можно вводить в те серии, которые со- ответствуют признакам вновь кодируемых объектов. Следует правильно оп-
ределить необходимую резервную емкость каждой серии, чтобы при ведении
классификатора не возникла необходимость изменения размеров серий.
При одновременном использовании нескольких признаков классификации применяют последовательный или параллельный метод кодирования.
Последовательный метод кодирования заключается в поочередном указа-
нии в кодовом обозначении независимых признаков классификации.
При использовании цифрового алфавита кодовое обозначение часто имеет
вид нескольких десятичных разрядов. Тогда при последовательном методе
кодирования старшие разряды предназначены для указания высших призна-
ков, а последующие – для независимых. Например, при порядковом методе подсистемы СУ кодируют двумя старшими десятичными разрядами, а реша-
емые в них задачи – двумя младшими разрядами. Это значит, что кодовое обозначение 0516 означает шестнадцатую задачу пятой подсистемы.
Параллельный метод кодирования заключается в указании в кодовом обоз-
начении независимых признаков классификации. Это кодирование, при кото-
ром каждому признаку классификации выделяют серии чисел натурального
ряда, кратные десяти, называют десятичным кодом.
Десятичный код широко используют для кодирования самых различных объектов благодаря его достоинствам – простоты кодирования, запоминаний
значений разрядов, сортировки, разделения на группы и другие. Недостаток –
значительная избыточная емкость, снижающая эффективность использова-
ния таких кодов в компьютерных системах.
Смешанный (комбинированный) метод кодирования заключается в однов-
ременном использовании нескольких различных методов кодирования. Его
применяют для многопризначных номенклатур, причем каждый из признаков
кодирования каким-либо одним методом. Достоинство этого метода состоит в том, что при кодировании больших номенклатур можно использовать срав-
нительно небольшое число знаков и преимущества различных кодов.
Способы представления информации в ЭВМ, кодирование и преобразование кодов в значительной степени зависят от принципа действия устройств, в ко-
торых эта информация формируется, накапливается, обрабатывается и отоб-
ражается.
Для кодирования символьной и текстовой информации применяются различ-
ные системы: при вводе информации с клавиатуры кодирование происходит
при нажатии клавиши, на которой изображен требуемый символ, при этом в
клавиатуре вырабатывается так называемый scan-код, представляющий собой
двоичное число, равное порядковому номеру клавиши.
Номер нажатой клавиши никак не связан с формой символа, нанесенного на
клавише. Опознание символа и присвоение ему внутреннего кода ЭВМ про-
изводится специальной программой по специальным таблицам, например,
Д КОП, КОП-7, ASCII (Американский стандартный код передачи информа-
ции). С помощью таблицы кодирования ASCII можно закодировать 256 раз-
личных символов.
Дисплей по каждому коду символа должен вывести на экран изображение символа – не просто цифровой код, а соответствующему ему картинку, так как каждый символ имеет свою форму. Описание формы каждого символа
хранится в специальной памяти дисплея – знакогенераторе.
Высвечивание символа на экране дисплея IBM PC осуществляется с помо-
щью точек (пиксел), образующих символьную матрицу. Каждый пиксел в
такой матрице является элементом изображения и может быть ярким или темным. Темная точка кодируется цифрой 0, а светлая (яркая) – 1. Если изоб-
ражать в матричном поле знака темные пикселы точкой, а светлые – звездоч-
кой, то можно графически изображать форму символа.
Кодирование аудиоинформации – процесс сложный. Аудиоинформация яв-
ляется аналоговой. Для преобразования ее в цифровую форму используют аппаратные средства: аналого-цифровые преобразователи (АЦП), в результа-
те работы которых аналоговый сигнал оцифровывается – представляется в виде числовой последовательности. Для вывода оцифрованного звука на аудиоустройства необходимо проводить обратное преобразование, которое
осуществляется с помощью цифро-аналоговых преобразователей (ЦАП).
1.5. Обработка информации.
Любая информация, обрабатываемая в компьютере, должна быть представ-
лена двоичными цифрами {0,1}, т.е. должна быть закодирована комбинацией
комбинацией этих цифр. Различные виды информации (числа, тексты, графи-
ка, звук) имеют свои правила кодирования. Коды отдельных значений, отно-
сящихся к различным видам информации, могут совпадать. Поэтому расши-
фровка кодированных данных осуществляется по контексту при выполнении
команд программ.
При построении систем управления циркулирующую на предприятии ин-
формацию необходимо рассмотреть, во-первых, с точки зрения ее практичес-
кой полезности и ценности для пользователей информации и АСУ с целью принятия решения и, во-вторых, с точки зрения смысловой взаимосвязи меж-
ду информационными процессами.
Первое позволяет установить необходимую и достаточную для пользовате-
лей информацию и на этой основе решить технические вопросы – осущест-
вить выбор необходимых вычислительных средств по переработке, хране-
нию, передаче информации в каналы связи систем управления для выработки
управляющих воздействий по обеспечению производства качественной про-
дукции.
Второе позволяет раскрыть содержание информации, отражающее состоя-
ние объекта, вскрыть отношение между знаками и символами, их предмет-
ными смысловыми значениями и выбрать смысловые единицы измерения
(критерии) информации, провести классификацию показателей объектов,
создать систему взаимосвязанных кодов, обеспечивающих эффективную ра-
боту систем управления производственными процессами. Смысловой аспект информации способствует наиболее полному выяснению, изучению состоя-
ния производственных процессов, явлений и данных с целью обоснованного
принятия, выработки управляющих решений и воздействий для обеспечения
производства продукции стандартного качества.
Основным видом информации о состоянии объекта управления в АСУ явля-
ются текущие значения технологических параметров, которые преобразуют-
ся автоматическими измерительными устройствами в сигналы измеритель-
ной информации. После приведения к стандартной форме эти сигналы вводя-
тся в программно-технический комплекс (ПТК) и представляют в нем значе-
ния соответствующих параметров в данный момент времени.
Сформированный таким образом массив исходной информации не пригоден для непосредственного использования при решении задач управления, так как требуется его предварительная обработка, которую называют первичной. Для этого необходимо рассмотреть последовательность необходимых преоб-
разований, которым подвергается измерительная величина в типовом устрой-
стве связи с объектом (УСО), его схема приведена на рис.1.1.
 z(t) e (t)
z(t) e (t)
X(t) Y(t) g(t) t0 g(jt0) g*(jt0)
1 2 3
Рис.1.1. Схема УСО
где 1 – первичный преобразователь (датчик); 2 – коммутатор; 3 – аналого-
цифровой преобразователь (АЦП).
Измеряемая величина х(t), которая обычно является стационарной случай-
ной функцией времени, воздействует на вход измерительного преобразовате-
ля (ИП), на выходе которого формируется сигнал измерительной информа-
ции у(t). Принцип действия большинства ИП таков, что их выходной сигнал
зависит не только от значения измеряемой величины, но и от ряда других величин zj которые являются влияющими.
Например, термоэлектрический преобразователь температуры (ТПП) пре-
образует измеряемую величину – температуру – в сигнал измерительной ин-
формацц – э.д.с.. Однако этот сигнал зависит не только от величины измеря-
емой температуры, которая воспринимается рабочим спаем, но и от темпера-
туры свободных спаев, которая в этом случае является влияющей величиной.
В общем случае без учета динамической характеристики ИП связь между
сигналами на его входе и выходе описывается статической характеристикой
вида: у = f(х, z) , (1 – 18)
где f – непрерывная и дифференцируемая по всем аргументам; z – вектор
влияющих величин.
Однозначное соответствие между сигналами измерительной информации и
измеряемой величиной обеспечивается только при постоянных значениях влияющих величин. Для каждого ИП эти номинальные значения zoj указыва-
ют в его паспорте. Подставив их в уравнение (1-18), получим номинальную
(паспортную) статическую характеристику ИП:
у = f(x, zo) = fo(x) (1-19)
Можно считать, что в процессе работы ИП значения влияющих величин
соответствуют номинальным; следовательно, преобразование значений из-
меряемой величины в сигнал измерительной информации выполняется в
соответствии с паспортной статической характеристикой (1-19). Однако и
при выполнении этого условия всякий реальный ИП вносит в результаты не-
которую погрешность.
На схеме (1-1) погрешность представлена в виде случайной функции време-
ни е(t), которая накладывается на полезный сигнал у(t) измерительной инфо-
рмации. Помеха е(t) моделирует не только случайную погрешность ИП, но и
электрические наводки в соединительных проводах, обусловленные магнит-
ными полями электросилового оборудования; влияние пульсации давления и расхода в технологических трубопроводах вследствие работы насосов и ком-
прессоров и другие факторы. На вход ПТК поступает суммарный сигнал:
g(t) = у(t) + e(t) (1 – 20)
Так как АСУ имеет некоторое множество УСО, их обслуживание разделено во времени, каждый канал периодически с периодом to подключается на не-
которое время ко входу ПТК. В результате непрерывная функция g(t) преоб-
разуется в последовательность импульсов, модулированных по амплитуде функций g(t). На схеме УСО (см. рис. 1.1) функцию квантования сигнала g(t)
по времени выполняет коммутатор (2), условно обозначенный в виде ключа,
замыкаемого с периодом to. На выходе коммутатора образуется решетчатая
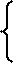 функция: g(t) при t = jto , j = 0,1,2 ….
функция: g(t) при t = jto , j = 0,1,2 ….
g(jto) =
0 при t≠ jto
Следующим видом преобразования, которому подвергается сигнал измери-
тельной информации в УСО, является квантование по уровню, выполняемое
АЦП. При этом амплитуды импульсов g(jto) преобразуется в числа g*(jto). вы-
раженные в коде, с которыми в дальнейшем оперирует ЭВМ. Современные
компьютеры, как правило, используют двоичный код и оперируют с числами,
имеющими 16, 32 и 64. Операция квантования дискретной величины g*(lto) по уровню можно описать следующим выражением:
g*(jto) = Int [g(jto)/Dg] Dg , (1 – 21)
где Int(r) – функция “целая часть от r”; Dg – шаг квантования по уровню, т.е.
цена младшего разряда в двоичном коде числа g*(jto).
Число g*(jto), полученное в результате выполнения всех преобразований из-
меряемой величины в УСО, вводится в ПТК и в дальнейшем представляет в нем значение измеряемой величины х(t) в момент времени t = jto.
Согласно вышеизложенному решаются следующие основные задачи пер-
вичной обработки информации в АСУ:
1) фильтрация сигнала измерительной информации от случайной помехи
(погрешности) е(t);
2) восстановление значения измеряемой величины х(t) по сигналу измерите-
льной информации у(t);
3) коррекция восстановленных значений измеряемой величины с учетом отк-
лонения условий измерения от номинальных;
4) восстановление значений измеряемой величины х(t) при jto < t < (j + 1)to,
т.е. интерполяция и экстраполяция.
1.6. Алгоритмы обработки информации и ее оценивание.
Процесс управления обусловлен сбором и проверкой достоверности ин-формации о текущих значениях технологических параметров, характеризу- ющих состояние объекта управления (технологический процесс).
Первичная обработка информации состоит из операций сбора, линеариза-
ции и приведения сигналов к виду удобному для использования в вычислите-
льном устройстве.
Алгоритмы сбора информации определяют последовательность и периодич-
ность опроса первичных преобразователей (датчиков). Они подразделяются
на алгоритмы адресного, программного, циклического, адаптивного опросов.
Алгоритмы адресного опроса обеспечивают опрос датчиков по заданным адресам.
Алгоритмы программного и циклического опроса осуществляют опрос дат-
чиков согласно заданной последовательности.
Алгоритмы адаптивного опроса организуют опрос датчиков в зависимости от состояния объекта управления: расположенности к аварийному состоя-
нию, скорости изменений параметров заданных уровней, его значимости.
Исходными данными алгоритмов опроса датчиков являются: число прону-
мерованных датчиков (хi), массивы верхних и нижних пределов допустимых значений (норм) показаний датчиков (хi), время при котором произошло отк-
лонение от нормы (ti) и порядковый номер датчика (i). После опроса всех дат- чиков, результаты выводятся на принтер или вводятся в микропроцессорную
систему (МПС) для контроля и формирования управляющих воздействий.
Алгоритм линеаризации применяют в случаях, когда зависимость показаний
датчика не линейна (непропорциональна) значениям измеряемой величины.
Эти алгоритмы выполняют определенную нелинейную операцию, чтобы ре-
зультат измерений линейно зависел от измеряемой переменной.
Алгоритмы приведения информации к виду, удобному для использования в
управляющем устройстве, применяют для согласования пределов измерений
с выходными сигналами компьютера и приведения информации к стандарт-
ному виду.
Алгоритмы оценивания (алгоритмы вторичной обработки информации) при-
меняют для снижения инструментальных и методических погрешностей из-
мерений, повышения достоверности информации, преобразования результа-
тов косвенных измерений. Они реализуются алгоритмами интерполяции, экс-раполяции и фильтрации.
Алгоритмы интерполяции используются для восстановления значения пере-
менной в промежутке между дискретными изменениями ее. При этом приме-
няется линейная интерполяция, посредством кусочно-линейной аппроксима-
ции исследуемой функции.
Алгоритмы экстраполяции (прогнозирования) обеспечивают запоминание
результата измерения до момента следующего измерения. При наличии ма-
тематической модели (ММ), имея дискретное измерение переменной, ее зна-
чение принимают за начальное условие для решения модели процесса. Резу-
льтат решения является экстраполированной оценкой до следующего диск-
ретного изменения. Если измеряемая переменная описывает случайный про-
цесс, то в качестве начального условия принимается математическое ожида-
ние контролируемого параметра. Однако, экстраполяция по математическому
ожиданию на малых интервалах проигрывает то точности экстраполяции, а при больших интервалах экстраполяции алгоритмы экстраполяции по мате-
матическому ожиданию является более точным.
Алгоритмы фильтрации предназначеныдля получения оценок результата в
текущий момент. В практике получили применение алгоритмы фильтрации
(фильтры), которые реализуются аналоговыми средствами (аппаратурно) или
программно. Распространение получили экспоненциальный фильтр, фильтр скользящего среднего и статистические фильтры.
Тестирование.Выбери правильный ответ.
а) Cовокупность методов, определяюших объект.
1.Что такое инфор- б) Философская категория познания мира.
мация? в) Совокупность принципов определяющих мир.
а) Процесс применения технологий и ЭВМ.
2.Компьютеризация б) Процесс применения человека и ЭВМ.
общества? в) Процесс применения информации и ЭВМ.
а) Мера неопределенности объекта управления.
3.Энтропия? б) Мера неопределенности данной ситуации.
в) Мера неопределенности состояния человека.
а) Автоматическая система управления
4. Что такое АСУ? б) Автоматизированная система управления.
в) Автономная система управления.
5.Информационное а) Совокупность технологий и алгоритмов описания
обеспечение АСУ. АСУ.
б) Совокупность технологий, данных и алгоритмов
описания АСУ.
в) Совокупность данных и алгоритмов описания АСУ.
Вопросы для самоконтроля.
1. Информационные технологии, их суть.
2. Количество информации.
3. Энтропия информации, ее суть.
4. Виды информации.
5. Системы счисления информации.
6. Способы представления информации.
7. Системы классификации информации.
8. Кодирование информации.
9. Обработка информации.
10.Алгоритмы обработки информации.
Дата добавления: 2016-01-03; просмотров: 835;