Специализированные видеопроцессоры для обработки и анализа изображений -
Одно из основных направлений в развитии видеопроцессорных вычис лительных устройств — создание архитектуры двухмерной матрицы про цессорных элементов. Если формат процессорной матрицы 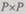 меньше
меньше
чем формат изображения  , то изображение обрабатывается поблочно. I этом случае имеют в виду локально-параллельное вычислительное устрой ство, а при
, то изображение обрабатывается поблочно. I этом случае имеют в виду локально-параллельное вычислительное устрой ство, а при  — полнопараллельное.
— полнопараллельное.
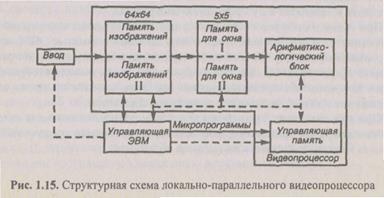
Локально-параллельные видеопроцессоры. Рассмотрим типичнун структуру локально-параллельного видеопроцессора с единичным процес сорным элементом ЭВМ (рис. 1.15), где обращаются непосредственно к на бору данных изображений в любой локальной области и к результатам ло кальных вычислений. При вычислении каждой основной функции со скоро стью 1 мкс на точку время обработки изображений 512x512 составляет I,'. с. Это вычислительное устройство имеет: двухкадровую память изображе ния (. 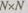 — размерность изображения), допускающую различные режимь обращения; память, содержащую два локальных окна (
— размерность изображения), допускающую различные режимь обращения; память, содержащую два локальных окна ( 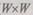 — размерност] окна).
— размерност] окна).
Например, N = 128, W = 5. Последняя память используется в качест ве высокоскоростной буферной памяти между памятью изображения i арифметико-логическим устройством. Память локальных окон допускас различные режимы адресации: линейное и полярное сканирование ш заданной траектории. При наличии динамически перестраиваемой сие темы микропрограммирования, позволяющей комбинировать основные операции, возможно выполнение широкого круга задач по предвари тельной обработке изображений, таких, как вычисление поля градиен тов, фильтрация, сжатие, оконтуривание, выделение топологически) признаков и т. д.
Полнопараллельные видеопроцессоры. В локально-параллельном видеопроцессоре процессорная матрица имела размерность значительно меньше размерности изображения (4x4 « 512x512). Полнопараллельные видеопроцессоры (ППВП) характеризуются тем, что в них размерность процессорной матрицы равна размерности изображения.
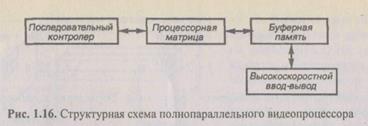
Рассмотрим типовую архитектуру ППВП (рис. 1.16), имеющую процессорную матрицу, содержащую 128x128 процессорных элементов. Последовательный контроллер — это быстродействующая последовательная ЭВМ, выполняющая арифметические и логические функции. Основная задача этой ЭВМ — хранение и чередование программ. Последовательный контроллер связан с процессорной матрицей через набор регистров обмена, которые предназначены для пересылки команд, параметров и констант в процессорную матрицу и возвращения их в последовательный контроллер. Последовательный контроллер обеспечивает связь с периферией и другими внешними ЭВМ. Процессорная матрица содержит 16384 микропроцессора, реализованных на основе технологии БИС и образующих решетку размерностью 128x128. Последовательный контроллер передает команду к процессорной матрице, которая выполняется одновременно всеми микропроцессорами. Каждый микропроцессор работает с данными, содержащимися в собственной области памяти.
Процессорная матрица и буферная память соединяются высокоскоростной шиной ввода-вывода. Буферная память выполняет функции буфера данных между процессорной матрицей и внешней средой. Она получает данные от обычной и специализированной периферии. Снабжение буферной памяти внутренним контроллером для изменения формата данных позволяет процессорной матрице обрабатывать данные более эффективно. Буферная память получает по заданному адресу набор из 16384 элементов данных и передает его в процессорную матрицу. При этом память каждого микропроцессора получает только один элемент.
Конфигурация набора данных, получаемых процессорной матрицей, определяется программно. Например, если К является адресом набора, то данные поступают из следующих ячеек буферной памяти:

Параметры (и, т) и к задаются программно. Обращение к набору данных буферной памяти, содержащему 128x128 элементов с началом в точке (х, у) изображения размерностью 512x512, иллюстрируется рис. 1.17. Системы команд ППВП делят на три группы: последовательные, параллельные и команды обмена.
Последовательные команды аналогичны командам любой последо
вательной ЭВМ — это команды загрузки, хранения, арифметических дейст
вий, логических операций, прерываний и т. д. Они выполняются только по
следовательным контроллером и используются для управления ходом про
граммы и вычисления отдельных параметров и констант, которые переда
ются процессорной матрице.
Параллельные команды также состоят из команд загрузки, хранения,
арифметических и логических операций, т. е. аналогичны последователь
ным командам, за исключением команды прерывания. Параллельные ко
манды, как и последовательные, хранятся в памяти последовательного кон
троллера, который, находя в процессе выполнения программы параллель
ную команду, передает ее через регистр обмена в процессорную матрицу,
где эта команда реализуется одновременно всеми процессорами.
Таким образом, параллельная операция ППВП функционально эквивалентна последовательной операции, выполняемой 16384 раза в последовательном аппаратном контуре. Но так как в ППВП параллельная операция выполняется за один временной такт, то процессорная матрица обрабатывает данные в 16384 раза быстрее, чем последовательная ЭВМ с тем же временным циклом. Эта фундаментальная форма параллелизма обеспечивает огромную вычислительную мощность ЭВМ этого типа «одна команда — много данных» при решении специализированных задач. Такие ЭВМ не
могут обладать параллельным прерыванием. Это обусловлено тем, что каждый процессор в процессорной матрице работает с собственным набором данных, а поэтому каждый процессор снабжается собственным регистром состояний и либо выполняет, либо игнорирует полученную команду в зависимости от состояния его собственного условного кода. Рассматриваемое свойство «непрерываемое™» существенно  упрощает программирование.
упрощает программирование.
 3. Набор команд обмена, которые управляют движением данных между параллельными и последовательными частями, имеют набор большинство ЭВМ типа «одна команда — много данных», последовательный контроллер может передавать константы и параметры каждому
3. Набор команд обмена, которые управляют движением данных между параллельными и последовательными частями, имеют набор большинство ЭВМ типа «одна команда — много данных», последовательный контроллер может передавать константы и параметры каждому 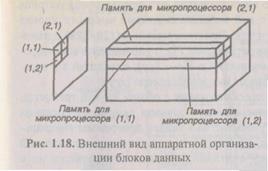 процессору в процессорной матрице с помощью специальных версий параллельных команд. Обратная пересылка осуществляется различными способами. Один из них состоит в том, что каждый процессор получает собственный идентификационный номер. Специальная команда выбирает для работы процессор с наименьшим идентификационным номером, позволяя ему сообщаться с последовательным контроллером. Эту команду объединяют с логическими операциями.
процессору в процессорной матрице с помощью специальных версий параллельных команд. Обратная пересылка осуществляется различными способами. Один из них состоит в том, что каждый процессор получает собственный идентификационный номер. Специальная команда выбирает для работы процессор с наименьшим идентификационным номером, позволяя ему сообщаться с последовательным контроллером. Эту команду объединяют с логическими операциями.
В результате обслуживаются только процессоры, удовлетворяющие заданным логическим условиям. Так как подмножество процессоров задается набором команд, то выбранные процессоры образовывают произвольную последовательность несмежных элементов.
Рассмотрим два примера реализации алгоритмов обработки и анализа изображений с помощью полнопараллельных видеопроцессоров.
Пример нелокального преобразования. При выполнении нелокальных преобразований 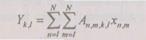
данные вводятся в процессорную матрицу таким образом, что все расчеты преобразования, связанные с одной точкой 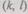 ,
,
т. е. 
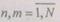 поступают в память
поступают в память
соответствующего процессора (рис. 1.18).
При такой организации за один цикл из 16384 умножений-сложений вычисляется все линейное преобразование, т. е. 16384 отсчетов:
Для реализации локальных преобразований процессорные элементы в количестве 128x128 соединяются в решетку, в которой каждый процессор  взаимодействует с че-
взаимодействует с че- 
тырьмя соседними (рис. 1.19). То обстоятельство, что процессорная матрица двухмерна, позволяет работать с ней в терминах языков высокого уровня таких, как PACKAL, FORTRAN и т. д. При этом массив /'(128x128) организуется таким образом, чтобы элемент массива Р(х, у) хранился в микропроцессоре (х, у). В результате отсчет, взятый в Р(х + 1, у), находится в микропроцессоре, расположенном справа от микропроцессора (х, у).
Для реализации локального преобразования в общем случае требуется, чтобы все микропроцессоры одновременно получали данные от соседних процессоров. Этот параллелизм указывается в записи программы специальным символом 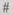 в виде
в виде  , Это соответствует тому, что каждый микропроцессор получит команду считывания данных и пересылки их к микропроцессору, расположенному на расстоянии п шагов от него. Локальное вычисление может быть записано, например, в следующем виде:
, Это соответствует тому, что каждый микропроцессор получит команду считывания данных и пересылки их к микропроцессору, расположенному на расстоянии п шагов от него. Локальное вычисление может быть записано, например, в следующем виде:
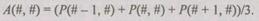
Эта запись соответствует вычислению следующего математического выражения:
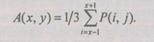
Пример типичной программы для вычисления локальной свертки:
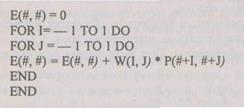
Заключение
Высокопроизводительные, полнопараллельные видеопроцессоры делают возможным создание визуальных систем, работающих в реальном масштабе времени, которые основаны на динамическом взаимодействии между интеллектуальной командной системой принимающей решения, и подсистемой, способной осуществлять анализ изменяющихся во времени изображений.
Дата добавления: 2015-10-29; просмотров: 997;