Захист від помилок.
Під час передачі даних каналами зв’язку існує ймовірність появи помилок. Це пов’язано з тим, що канал передачі інформації зазвичай наражається на дію різних спотворень, зумовлених шумом. Шум може бути як природним, так і створюватись використовуваним устаткуванням. Захист від помилок передбачає їх виявлення і виправлення. Виявлення помилок здійснюється, як правило, внаслідок аналізу послідовності символів на приналежність її до певного класу структур. Існують два основних підходи до виправлення помилок. Перший підхід ґрунтується на використанні методів локалізації і виправлення помилок в приймальному пристрої, а другий передбачає лише визначення появи помилок, «виправлення» яких здійснюється повторною передачею повідомлення. Вибір того або іншого способу залежить від низки чинників, таких як тип каналу, швидкість передачі даних, можливість появи помилок тощо.
За відповідного кодування інформації кількість помилок може бути зменшена до потрібного рівня. Для цього пропонується використовувати поняття надлишкове кодування, суть якого полягає в тому, що вихідна послідовність символів, що називається інформаційною послідовністю, у разі застосування певних правил перетвориться у двійкову послідовність більшої довжини. Сформована таким чином послідовність символів називається кодовим словом. Наприклад, унаслідок додавання r перевірочних символів до вихідної послідовності, що складається з k символів, утвориться кодове слово завдовжки n = k + r. У загальному випадку кількість розрядів n дає можливість утворити 2n різних комбінацій двійкових послідовностей. Для зображення множини слів інформаційної послідовності достатньо 2k комбінацій; частина кодових слів, що залишилася, є надлишковою — їх поява при передачі інформації вважається за помилку. Виявлення в отриманій каналами зв’язку інформації спотворених (заборонених) послідовностей символів і лежить в основі методів виявлення і корекції помилок.
Розглянемо блоковий код, за якого неперервна послідовність інформаційних символів розбивається на блоки (повідомлення), кожен з яких містить k символів інформації. Кодове слово утворюється додаванням до блокового коду деякої кількості додаткових символів. Додаткові символи не несуть інформації і використовуються лише для виявлення і виправлення помилок. Найчастіше блоковий код позначається як (n, k)-код, де n — довжина коду, k — кількість інформаційних символів. Кількість додаткових символів, що дорівнює різниці між загальною довжиною коду і кількістю інформаційних символів, впливає на одну з найважливіших характеристик кодів — відноснушвидкістьпередачікодів каналами зв’язку, яка визначається відношенням швидкості передачі інформаційних бітів, що містяться в кодовому слові, до швидкості передачі самого кодового слова за формулою R=k/n.
Найпростіший спосіб формування блокового коду — це додавання спеціального біта парності до блоку даних. Такий код позначається як (k+1, k)-код. Прикладом може бути кодування інформації при стартостопному способі передачі, розглянутому раніше. Такий спосіб виявлення помилок, що називається контроль парності, є досить простим, але дає можливість виявити тільки парне число помилок і ефективний при аналізі коротких послідовностей бітів даних .
Для підвищення швидкості передачі, повідомлення, що передаються каналом зв’язку, розбиваються на досить великі блоки (пакети) — по 1024 байти. Це змушує відмовитись від використання контролю парності. З іншого боку, якщо блоковий код не має спеціальної структури, то кодування і декодування його за великих значень k є досить складним. У цьому разі пристрій, що кодує, має зберігати 2k кодових слова, а пристрій, що декодує, повинен вміти їх розпізнавати. Тому намагаються вибрати таку структуру кодового слова, яка забезпечила б максимальну простоту кодування і декодування. Залежно від алгоритму кодування перевірочні символи можуть розміщуватися як між інформаційними символами, так і наприкінці їх. Для більшої наочності та зручності декодування бажано, щоб кодове слово чітко ділилося на дві частини: інформаційну і перевірочну, в даному випадку кодове слово
u = ( 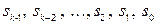 ,
, 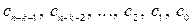 ) (2.1)
) (2.1)
складається з k символів початкового повідомлення:
s = ( ) (2.2)
і (n - k) перевірочних символів:
c = ( ) (2.3)
Як показано в теорії кодування інформації, процес кодування і декодування істотно спрощується, якщо у блоковому коді присутня властивість лінійності, тобто коли сума по модулю 2 будь-яких двох кодових слів є також кодовим словом.
Нагадаємо правила додавання по модулю 2:
1. 0 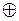 0 = 0;
0 = 0;
1 0 = 1;
0 1 = 1;
1 1 = 0.
2. При додаванні переноси відсутні.
Серед лінійних кодів є (7, 4) код, який наведено в табл. 2.2.
Легко перевірити, що при додаванні двох будь-яких кодових слів з табл.6.2 утвориться нове кодове слово з тої ж таблиці, наприклад, при додаванні 9‑го и 5‑го кодових слів утвориться 14‑те кодове слово:
1 0 0 0 1 0 1
0 1 0 1 1 0 0
 |
1 1 0 1 0 0 1
Таблиця 2.2. Лінійний код (7, 4)
| № | Повідомлення | Кодове слово | |
| 0 0 0 0 | 0 0 0 0 | 0 0 0 | |
| 0 0 0 1 | 0 0 0 1 | 0 1 1 | |
| 0 0 1 0 | 0 0 1 0 | 1 1 0 | |
| 0 0 1 1 | 0 0 1 1 | 1 0 1 | |
| 0 1 0 0 0 1 0 1 0 1 1 0 0 1 1 1 1 0 0 0 1 0 0 1 1 0 1 0 1 0 1 1 1 1 0 0 1 1 0 1 1 1 1 0 1 1 1 1 | 0 1 0 0 0 1 0 1 0 1 1 0 0 1 1 1 1 0 0 0 1 0 0 1 1 0 1 0 1 0 1 1 1 1 0 0 1 1 0 1 1 1 1 0 1 1 1 1 | 1 1 1 1 0 0 0 0 1 0 1 0 1 0 1 1 1 0 0 1 1 0 0 0 0 1 0 0 0 1 1 0 0 1 1 1 |
Ще однією властивістю кодів, яка використовується в системах кодування, є циклічність. Лінійний (n, k)-код є циклічним, якщо внаслідок циклічного зсуву деякого кодового слова u= ( 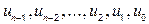 ) утворюється нове кодове слово u’= (
) утворюється нове кодове слово u’= ( 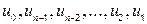 ).
).
В системах передачі даних циклічні коди часто позначаються як CRC-коди (скорочення від Cyclic Redundancy Check). Наведений в табл. 2.2 лінійний код одночасно є також і циклічним, наприклад, при зсуві 6‑го кодового слова (0101100) отримується новий код (0010110), який є 3‑ім кодовим словом у вказаній таблиці.
Властивість циклічності дає можливість досить просто реалізувати кодувальні і декодувальні пристрої на базі зсувних регістрів і схем додавання за модулем 2.
У теорії кодування циклічні коди подаються у вигляді поліномів. Наприклад, кодовому слову u=( ) відповідає такий поліном:
u(X) = 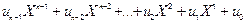 (2.4)
(2.4)
Вид полінома (2.1) залежить від конкретних значень розрядів кодового слова. Так, для кодового слова (1 1 0 1 0 0 1) кодовий поліном має такий вигляд: X6+X5+X3+1.
Розглянемо найважливіші властивості циклічних кодів. У циклічному (n, k)‑коді степінь кожного ненульового кодового полінома має бути в межах від (n–k) до (n–1). Це визначається структурою циклічних кодів, перший інформаційний символ у яких розміщується завжди ліворуч від перевірочних символів, а останній – у (n–1) позиції. Інакше кажучи, мінімальний ненульовий кодовий поліном матиме степінь 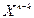 . Слід зазначити, що для будь-якого циклічного (n, k)‑коду поліном степеня (n–k) є єдиним і має такий вигляд:
. Слід зазначити, що для будь-якого циклічного (n, k)‑коду поліном степеня (n–k) є єдиним і має такий вигляд:
g(X) = 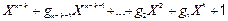 (2.5)
(2.5)
Наприклад, в табл. 2.2 мінімальним ненульовим кодовим є слово під номером два, у якого справа за першим значущим розрядом слідує три перевірочні розряди. Кодовий поліном для даного кодового слова має наступний вигляд: 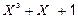 .
.
Через властивість циклічності кожний кодовий поліном цього коду має бути кратним мінімальному ненульовому кодовому поліному g(X), тобто має виконуватися умова u(X) = m(X)g(X). З іншого боку, будь-який кодовий поліном степені (n–k) може бути отриманий множенням полінома g(X) на відповідний поліном m(X).Поліном g(X) називається утворюючимполіномом. Отже, можна вважати, що будь-який циклічний (n, k)-код повністю визначається його твірним поліномом. Як утворюючий використовуються поліноми Хеммінга, до яких належить і розглянутий раніше утворюючий поліномg(X). Варто зазначити, що в системах телеобробки в якості стандартних використовуються наступні коди Хеммінга:
· CRC‑16 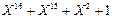 ;
;
· CRC‑CCITT 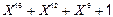 ;
;
· CRC‑12 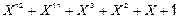 .
.
CCITT — скорочення від International Telegraph and Telephone Consultative Committee (Міжнародний консультаційний комітет по телеграфії і телефонії — МККТТ).
Останнім часом для підвищення надійності використовується поліном CRC‑32:
X32+X26+X23+X16+X12+X11+X10+X8+X7+X5+X4+X2+X+1, запропонований CCITT.
Розглянемо порядок формування кодових слів на прикладі коду, що наведений в табл. 6.2. Кожному з вихідних повідомлень відповідає визначений поліном m(X).
Наприклад, 1‑му повідомленню відповідає поліном m(X)=0, 2-му повідомленню (0 0 0 1) відповідає поліном m(X)=1, 3‑му повідомленню відповідає поліном m(X)=X, 4-му повідомленню – m(X)=(X+1) і так дальше. В результаті множення полінома m(X)=0 на утворюючий поліном формується перше кодове слово (0 0 0 0 0 0 0). Помноживши поліном m(X)=1 на утворюючий поліном g(X) = 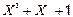 , отримаємо поліном, якому відповідає кодове слово (0 0 0 1 0 1 1). В результаті множення полінома m(X)=X, що відповідає 3‑му повідомленню (0 0 1 0), на утворюючий поліном отримуємо:
, отримаємо поліном, якому відповідає кодове слово (0 0 0 1 0 1 1). В результаті множення полінома m(X)=X, що відповідає 3‑му повідомленню (0 0 1 0), на утворюючий поліном отримуємо:
X( 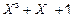 )=
)= 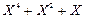 .
.
Даному поліному відповідає 3‑тє кодове слово (0 0 1 0 1 1 0). Аналогічним чином формується і решта кодових слів. У даному випадку довжина кодового слова дорівнює сумі довжин початкової контрольної послідовності.
Виявлення помилок здійснюється діленням кодового полінома на утворюючий. Якщо після передачі каналами зв’язку кодове слово не змінилося, тобто передане без помилок, то при діленні його на кодовий поліном залишку не буде. Поява залишку свідчитиме про помилку передачі даних.
На практиці при великій довжині повідомлень замість операції множення використовується операція ділення полінома на утворюючий поліном. Це дозволяє формувати більш короткі кодові слова. Нехай потрібно закодувати повідомлення
s= ( 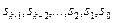 ), якому відповідає наступний поліном:
), якому відповідає наступний поліном:
s(X) = 
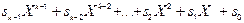 (2.6)
(2.6)
В якості утворюючого будемо використовувати деякий поліном
g(X) = 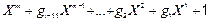 (2.7)
(2.7)
Як було сказано вище, при довжині повідомлення (k) та довжині кодового полінома (m) максимальна довжина кодового слова n = k + m. Змінимо в утворюючому поліномі (2.7) змінну m на (n-k) — отримаємо поліном, який відповідає утворюючому поліному (2.5). Далі збільшуємо довжину повідомлення на (n-k) розрядів, додаючи відповідне число нулів справа, — це відповідає множенню полінома s(X) на 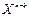 . В результаті множення формується поліном:
. В результаті множення формується поліном:
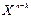 s(X) =
s(X) = 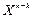 (
( 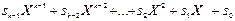 )
)
або
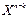 s(X) =
s(X) = 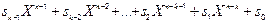 (2.8)
(2.8)
Поділивши 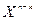 s(X) на утворюючий поліном g(X), маємо:
s(X) на утворюючий поліном g(X), маємо:
s(X) = q(X) g(X)+ r(X), (2.9)
де q(X) — ціла частина від ділення, аr(X) — залишок від ділення.
Оскільки кодоване повідомлення s(X) має будь-яку структуру і не є циклічним кодом, то, як правило, залишок r(X) не дорівнює нулю і має вигляд полінома степені (n-k-1):
r(X) = 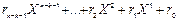 .
.
Додаємо до лівої і правої частини виразу (2.9) залишок r(X):
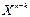 s(X) + r(X) = q(X) g(X)+ r(X) + r(X) (2.10)
s(X) + r(X) = q(X) g(X)+ r(X) + r(X) (2.10)
Враховуючи, що операції додавання виконуються по модулю 2, виконується умова r(X) + r(X) = 0. Тому вираз (2.10) приймає вигляд:
s(X) + r(X) = q(X) g(X) (2.11)
Далі, поділивши вираз (2.11) на g(X), отримаємо:
( s(X) + r(X))/ g(X)= q(X) (2.12)
Вираз ( 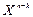 s(X) + r(X)) – кодовий поліном степені (n-1):
s(X) + r(X)) – кодовий поліном степені (n-1):
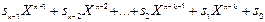 +
+
+ 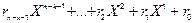 (2.13)
(2.13)
оскільки, згідно виразу (2.12), ділиться без залишку на утворюючий поліном.
Даному поліному відповідає кодове слово
( 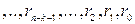 ), яке складається із залишку від ділення полінома s(X) на утворюючий поліном. Порівнюючи дане кодове слово з послідовністю (2.1), можна побачити, що залишок (
), яке складається із залишку від ділення полінома s(X) на утворюючий поліном. Порівнюючи дане кодове слово з послідовністю (2.1), можна побачити, що залишок ( 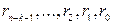 ) по своїй суті є послідовністю перевірочних символів
) по своїй суті є послідовністю перевірочних символів
( 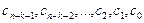 ).
).
Розглянемо процес кодування інформаційних послідовностей на прикладі виразу (1 1 0 1 0 1 1 0 1 1), якому відповідає наступний поліном:
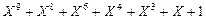 (2.14)
(2.14)
В якості твірного полінома будемо використовувати поліном третьої степені 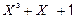 .
.
Після зсуву полінома (2.14) на три розряди вліво отримаємо наступний поліном:
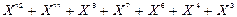 (2.15)
(2.15)
Розділимо поліном (2.15) на утворюючий поліном:
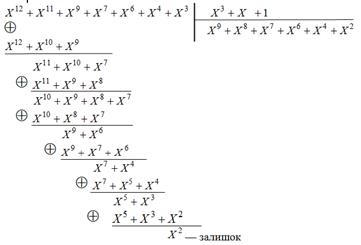
Операція ділення поліномів, що використовується вище, є звичайним діленням одного полінома на інший, за винятком того, що коефіцієнти приймають тільки двійкові значення, а арифметичні операції над коефіцієнтами виконуються по модулю два. Звернемо увагу на те, що в арифметиці по модулю два операція віднімання еквівалентна операції додавання.
Додамо до полінома (2.15) остачу ( 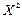 ) і отримаємо кодовий поліном:
) і отримаємо кодовий поліном:
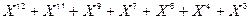 +
+ 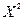 , (2.16)
, (2.16)
Якому відповідає кодове слово: (1 1 0 1 0 1 1 0 1 1 1 0 0).
Розділимо кодовий поліном (2.16) на утворюючий поліном:
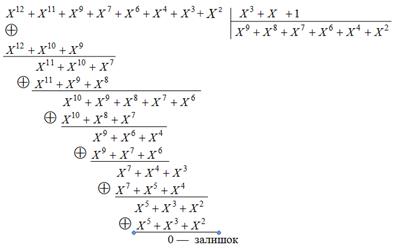
Можна запропонувати наступний алгоритм формування кодових слів:
1. Помножити поліном (2.6) початкової інформаційної послідовності на .
2. Отримати залишок (перевірочні символи) від ділення s(X) на утворюючий поліном g(X).
3. Об’єднати s(X) і r(X) у кодовий поліном (2.13).
На практиці операції над поліномами заміняються еквівалентними операціями зсуву і ділення початкової послідовності символів на послідовність символів утворюючого полінома. Як і при діленні поліномів, операції віднімання заміняємо операціями додавання по модулю два.
У нашому випадку маємо:

Таким чином, алгоритм кодування можна реалізувати, використовуючи схему ділення, що є регістром зсуву R(  ), в якому ланцюги оберненого зв’язку замкнені у відповідності з твірним поліномом g(X), як показано на рис. 2.13
), в якому ланцюги оберненого зв’язку замкнені у відповідності з твірним поліномом g(X), як показано на рис. 2.13
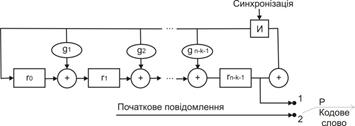
Рис. 2.13. Схема кодування для циклічного (n,k) коду, де: Р – перемикач
В якості прикладу на рис. 2.14 наведена схема кодування при утворюючому поліномі g(X) = 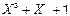 .
.
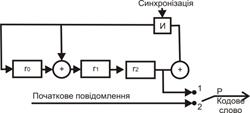
Рис. 2.14. Схема пристрою кодування для циклічного коду
з породжуючим поліномом g(x)=x3+х+1, де: Р – перемикач
Коротко зупинимося на роботі пристрою кодування. Спочатку перемикач Р перебуває в першому положенні, що забезпечує передачу вихідного повідомлення на вихід схеми кодування і на схему формування залишку, причому в останньому реалізується операція ділення вихідного повідомлення на утворюючий поліном. Після надходження останнього розряду повідомлення перемикач Р переводиться в друге положення, що забезпечує додавання залишку до вихідного повідомлення на виході схеми кодування. Сформоване у такий спосіб кодове слово надходить каналами зв’язку до приймального пристрою, де перевіряється правильність передачі даних шляхом ділення кодового слова на утворюючий поліном. Якщо залишок від ділення дорівнює нулю, то отриманий каналами зв’язку поліном є кодовим, а передана інформація не містить помилкових символів. Пристрій, що здійснює кодування інформації, називається кодером, відповідно декодуючий пристрій називається декодером. Кодер і декодер є основними елементами пристрою захисту від помилок. Окрім них, до його складу (рис. 2.15) входять: блоки перетворення інформації, буферні накопичувачі, пристрій керування, блок аварійної сигналізації й індикації.
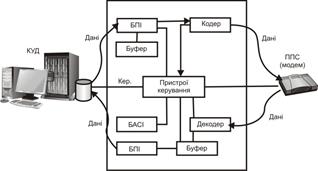
Рис. 2.15. Пристрій захисту від помилок, де:
КУД – кінцеве устаткування даних; ППС – пристрій перетворення сигналів;
БПІ – блок перетворення інформації; БАСІ – блок аварійної сигналізації та індикації;
До основних функцій блоків перетворення інформації належать прийом даних з боку пристрою перетворення сигналів чи кінцевого устаткування даних і перетворення їх до вигляду, зручного для кодування (декодування) і подальшої передачі. Буферні накопичувачі застосовуються для збереження інформації під час її обробки. Пристрій керування керує роботою блоків пристрою захисту від помилок, реалізуючи певний алгоритм кодування і декодування інформації. Функції фіксації і візуального відображення стану виконуються блоком аварійної сигналізації й індикації. Пристрій захисту від помилок здійснює такі дії: початкова установка блоків пристрою; прийом, перетворення і контроль інформації, що надходить через пристрій перетворення сигналів з каналу передачі даних, і передача її у кінцеве устаткування даних; формування керуючих сигналів, що передаються в пристрої перетворення сигналів і кінцеве устаткування даних. Крім того, більшість сучасних пристроїв захисту від помилок організують, згідно з певними алгоритмами, повторну передачу помилково прийнятих блоків даних.
Дата добавления: 2015-08-11; просмотров: 1486;