Методы выделения дискового пространства
Ключевой вопрос реализации способ связывания файлов с блоками диска. В ОС используется несколько методов выделения файлу дискового пространства. Для каждого метода сведения о локализации блоков данных файла можно извлечь из записи в директории, соответствующей символьному имени файла.
Выделение непрерывной последовательностью блоков
Простейший способ - хранить каждый файл, как непрерывную последовательность блоков диска. При непрерывном расположении файл характеризуется адресом и длиной (в блоках). Файл, стартующий с блока b, занимает затем блоки b+1, b+2, ... b+n-1.
Эта схема имеет два преимущества. Во-первых, ее легко реализовать, т.к. выяснение местонахождения файла сводится к вопросу, где находится первый блок. Во-вторых, она обеспечивает хорошую производительность, т.к. целый файл может быть считан за одну дисковую операцию.
Непрерывное выделение используется в ОС IBM/CMS, в ОС RSX-11 (для выполняемых файлов) и в ряде других.
Основная проблема, вследствие чего этот способ мало распространен - трудно найти место для нового файла. В процессе эксплуатации диск представляет собой некоторую совокупность свободных и занятых фрагментов. Проблема непрерывного расположения может рассматриваться как частный случай более общей проблемы выделения n блоков из списка свободных дыр. Наиболее распространенные стратегии решения этой проблемы - first fit, best fit и worst fit (ср. с проблемой выделения памяти). Таким образом, метод страдает от внешней фрагментации, в зависимости от размера диска и среднего размера файла, в большей или меньшей степени.
Кроме того, непрерывное распределение внешней памяти не применимо до тех пор, пока не известен максимальный размер файла. Иногда размер выходного файла оценить легко (при копировании). Чаще, однако, это трудно сделать. Если места не хватило, то пользовательская программа может быть приостановлена, предполагая выделение дополнительного места для файла при последующем рестарте. Некоторые ОС используют модифицированный вариант непрерывного выделения основные блоки файла + резервные блоки. Однако с выделением блоков из резерва возникают те же проблемы, так как возникает задача выделения непрерывной последовательности блоков диска теперь уже из совокупности резервных блоков.
Связный список
Метод распределения блоков в виде связного списка решает основную проблему непрерывного выделения, то есть устраняет внешнюю фрагментацию. Каждый файл - связный список блоков диска. Запись в директории содержит указатель на первый и последний блоки файла. Каждый блок содержит указатель на следующий блок.
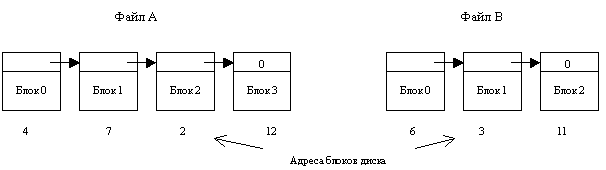
Рис. 12.2 Хранение файла в виде связного списка дисковых блоков
Внешняя фрагментация для данного метода отсутствует. Любой свободный блок может быть использован для удовлетворения запроса. Заметим, что нет необходимости декларировать размер файла в момент создания. Файл может неограниченно расти.
Связное выделение имеет, однако, несколько существенных недостатков.
Во-первых, при прямом доступе к файлу для поиска i-го блока нужно осуществить несколько обращений к диску, последовательно считывая блоки от 1 до i-1, то есть выборка логически смежных записей, которые занимают физически несмежные секторы, может требовать много времени.
Прямым следствием этого является низкая надежность. Наличие дефектного блока в списке приводит к потере информации в остаточной части файла и, потенциально, к потере дискового пространства отведенного под этот файл.
Наконец, для указателя на следующий блок внутри блока нужно выделить место. Емкость блока, традиционно являющаяся степенью двойки (многие программы читают и пишут блоками по степеням двойки), таким образом, перестает быть степенью двойки, т.к. указатель отбирает несколько байтов.
Поэтому метод связного списка обычно не используется в чистом виде.
Связный список с использованием индекса
Недостатки предыдущего способа могут быть устранены путем изъятия указателя из каждого дискового блока и помещения его в индексную таблицу в памяти, которая называется FAT (file allocation table). Этой схемы придерживаются многие ОС (MS-DOS, OS/2, MS Windows и др.)
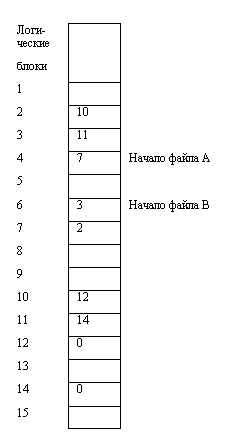
Рис. 12.3. Метод связного списка, с использованием таблицы в оперативной памяти
По-прежнему, существенно, что запись в директории содержит только ссылку на первый блок и т.о. можно локализовать файл независимо от его размера.
Минусом этой схемы может быть необходимость поддержки в памяти этой довольно большой таблицы.
Индексные узлы
Четвертый и последний метод выяснения принадлежности блока к файлу - связать с каждым файлом маленькую таблицу, называемую индексным узлом (i-node), которая перечисляет атрибуты и дисковые адреса блоков файла (см. рис 12.4).
Каждый файл имеет свой собственный индексный блок, который содержит адреса блоков данных. Запись в директории, относящаяся к файлу, содержит адрес индексного блока. По мере заполнения файла указатели на блоки диска в индексном узле принимают осмысленные значения.
Индексирование поддерживает прямой доступ к файлу, без ущерба от внешней фрагментации.
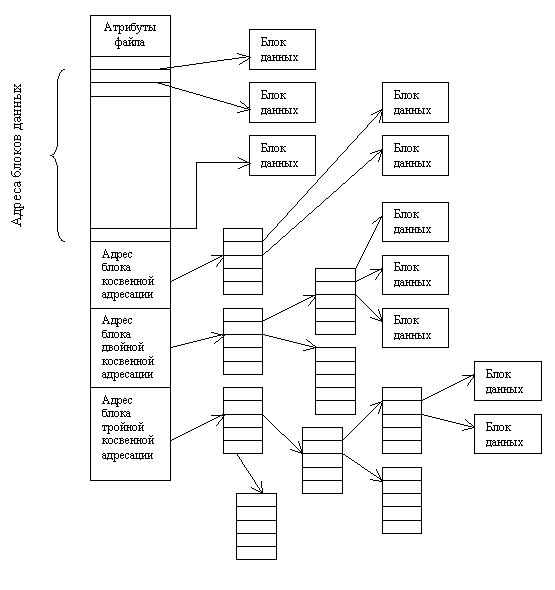
Рис. 12.4 Структура индексного узла
Первые несколько адресов блоков файла хранятся непосредственно в индексном узле, т.о. для маленьких файлов индексный узел хранит всю необходимую информацию, которая копируется с диска в память, в момент открытия файла. Для больших файлов один из адресов индексного узла указывает на блок косвенной адресации. Этот блок содержит адреса дополнительных блоков диска. Если этого недостаточно используется блок двойной косвенной адресации, который содержит адреса блоков косвенной адресации. Если и этого недостаточно используют блок тройной косвенной адресации.
Эту схему использует Unix (а также файловые системы HPFS, NTFS и др.). Такой подход позволяет при фиксированном, относительно небольшом размере индексного узла, поддерживать работу с файлами, размер которых может меняться от нескольких байт до нескольких гигабайт. Существенно, что для маленьких файлов используется только прямая адресация, обеспечивающая максимальную производительность.
Дата добавления: 2015-07-24; просмотров: 1110;