Эконометрические выводы: оценки и проверка гипотез
Эконометирческие выводы - это заключения о генеральной совокупности на основе выборки, случайно отобранной из генеральной совокупности. Например, анализируется такой показатель как доход (Х) населения некоторого достаточно большого города. Этот анализ может быть осуществлен на основе выборки определенного объема (пусть n=1000). Для выборочных данных определяем средний доход 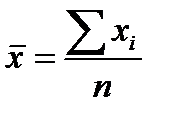 и разброс
и разброс
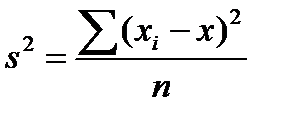 . Далее возникает естественный вопрос: можно ли ожидать, что аналогичные значения будут такими же для всего города? То есть можно ли обобщить результаты, полученные по выборке, на генеральную совокупность. В этом и суть статистических выводов.
. Далее возникает естественный вопрос: можно ли ожидать, что аналогичные значения будут такими же для всего города? То есть можно ли обобщить результаты, полученные по выборке, на генеральную совокупность. В этом и суть статистических выводов.
На основе выборки можно получить лишь оценки параметров генеральной совокупности, так как оценки эти строятся на основе ограниченного набора данных. Естественно, значения оценок могут, изменяется от выборки к выборке. Процесс нахождения оценок по определенному правилу называется оцениванием.
Выделяют два типа оценивания: оценивание вида распределения и оценивание параметров распределения.
В качестве оценки вида распределения можно взять выборочное распределение, а в качестве оценок параметров распределения генеральной совокупности берутся их выборочные оценки.
Различают два вида оценок – точечные и интервальные.
После определения оценок обычно встает вопрос об их качестве и статистической значимости.
Пусть рассматривается генеральная совокупность наблюдаемой СВ Х.
Для оценки ее параметра Θ из генеральной совокупности извлекается выборка объема n: x1,x2,…,xn. На основе этой выборки может быть найдена оценка Θ* параметра Θ.
Точечной оценкой Θ* параметра Θ называется числовое значение этого параметра, полученное по выборке объема n. Например, для нормального распределения параметрами являются математическое ожидание m и среднее квадратическое отклонение σ.
Оценками m и σ могут быть  и
и 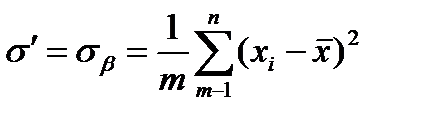 соответственно.
соответственно.
Очевидно, что оценка Θ* является функцией от выборки, то есть Θ* = Θ* (х1,х2,…,хп). А так как выборка носит случайный характер, то оценка Θ* является СВ, принимающей различные значения для различных выборок . Любую оценку Θ* = Θ* (х1,х2,…,хп) называют статистической оценкой параметра Θ.
65а. Система эконометрических уравнений
Сложные экономические процессы описывают с помощью системы взаимосвязанных уравнений. Различают несколько видов систем уравнений: 1. Система независимых уравнений - когда каждая зависимая переменная у рассматривается как функция одного и того же набора факторов х:
y1=a11*x1+a12*x2+…+a1m*xm+e1 Для решения этой системы и нахождения ее параметров
yn=an1*x1+an2*x2+…+anm*xm+en используется МНК.
2.Система рекурсивных уравнений – когда зависимая переменная у одного уравнения выступает в виде фактора х в другом уравнении:
y1=a11*x1+a12*x2+…+a1m*xm+e1
y2=b21*y1+a21*x1+a22*x2+…+a2m*xm+e2
y3=b31*y1+b32*y2+a31*x1+a32*x2+…+a3m*xm+e3
yn=bn1*y1+bn2*y2+…+bnn-1*yn-1+an1*x1+an2*x2+…+anm*xm+en
Для решения этой системы и нахождения ее параметров используется МНК.
3 Система взаимосвязанных уравнений – когда одни и те же зависимые переменные в одних уравнениях входят в левую часть, а в других – в правую.
y1=b12*y2+b13*y3+…+b1n*yn+a11*x1+a12*x2+…+a1m*xm+e1
y2=b21*y1+b23*y3+…+b2n*yn+a21*x1+a22*x2+…+a2m*xm+e2
yn=bn1*y1+bn2*y2+…+bnn-1*yn-1+an1*x1+an2*x2+…+anm*xm+en
Такая система уравнений называется структурной формой модели. Эндогенные переменные – взаимосвязанные переменные, которые определяются внутри модели (системы) у. Экзогенные переменные – независимые переменные, которые определяются вне системы х. Предопределенные переменные – экзогенные и лаговые (за предыдущие моменты времени) эндогенные переменные системы. Коэффициенты a и b при переменных – структурные коэффициенты модели. Система линейных функций эндогенных переменных от всех предопределенных переменных системы - приведенная форма модели.
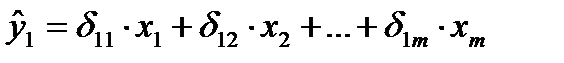
где 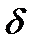 - коэффициенты приведенной формы модели.
- коэффициенты приведенной формы модели.
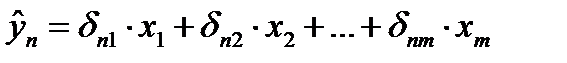
Необходимое условие идентификации – выполнение счетного правила:
D+1=H –уравнение идентифицируемо;
D+1<H – уравнение неидентифицируемо;
D+1>H – уравнение сверхидентифицируемо.
Где Н – число эндогенных переменных в уравнении, D – число предопределенных переменных, отсутствующих в уравнении, но присутствующих в системе.
Достаточное условие идентификации- определитель матрицы, составленной из коэффициентов при переменных, отсутствующих в исследуемом уравнении на равен нулю и ранг этой матрицы не менее эндогенных переменных без единицы. Для решения идентифицируемого уравнения применяется КМНК, для решения сверхидентифицируемых - двухшаговый МНК.
66. Проблема идентифицируемости модели
Представим теперь модель с большим числом эндогенных и экзогенных переменных, с лагами и сложной внутренней структурой. Вообще говоря, ниоткуда не следует, что существует хотя бы одно решение у такой системы. Поэтому возникает не одна, а две проблемы. Есть ли хоть одно решение (проблема идентифицируемости)? Если да, то как найти наилучшее решение из возможных? (Это - проблема статистической оценки параметров.)
И первая, и вторая задача достаточно сложны. Для решения обоих задач разработано множество методов, обычно достаточно сложных (см. список литературы), лишь часть из которых имеет научное обоснование. В частности, достаточно часто пользуются статистическими оценками, не являющимися состоятельными (строго говоря, их даже нельзя назвать оценками).
Коротко опишем некоторые распространенные приемы при работе с системами линейных эконометрических уравнений.
Система линейных одновременных эконометрических уравнений. Чисто формально можно все переменные выразить через переменные, зависящие только от текущего момента времени. Например, достаточно положить
H(t) = I(t- 1), G(t) = S (t - 4).
Тогда уравнение пример вид
I(t) = сH(t) + a + b G(t) + e. (81.1)
Отметим здесь же возможность использования регрессионных моделей с переменной структурой путем введения фиктивных переменных. Эти переменные при одних значениях времени (скажем, начальных) принимают заметные значения, а при других - сходят на нет (становятся фактически равными 0). В результате формально (математически) одна и та же модель описывает совсем разные зависимости.
Косвенный, двухшаговый и трехшаговый методы наименьших квадратов. Как уже отмечалось, разработана масса методов эвристического анализа систем эконометрических уравнений. Они предназначены для решения тех или иных проблем, возникающих при попытках найти численные решения систем уравнений.
Одна из проблем связана с наличием априорных ограничений на оцениваемые параметры. Например, доход домохозяйства может быть потрачен либо на потребление, либо на сбережение. Значит, сумма долей этих двух видов трат априори равна 1. А в системе эконометрических уравнений эти доли могут участвовать независимо. Возникает мысль оценить их методом наименьших квадратов, не обращая внимания на априорное ограничение, а потом подкорректировать. Такой подход называют косвенным методом наименьших квадратов.
Двухшаговый метод наименьших квадратов состоит в том, что оценивают параметры отдельного уравнения системы, а не рассматривают систему в целом. В то же время трехшаговый метод наименьших квадратов применяется для оценки параметров системы одновременных уравнений в целом. Сначала к каждому уравнению применяется двухшаговый метод с целью оценить коэффициенты и погрешности каждого уравнения, а затем построить оценку для ковариационной матрицы погрешностей, После этого для оценивания коэффициентов всей системы применяется обобщенный метод наименьших квадратов (см. выше).
Менеджеру и экономисту не следует становиться специалистом по составлению и решению систем эконометрических уравнений, даже с помощью тех или иных программных систем, но он должен быть осведомлен о возможностях этого направления эконометрики, чтобы в случае производственной необходимости квалифицированно сформулировать задание для специалистов-эконометриков.
От оценивания тренда (основной тенденции) перейдем ко второй основной задаче эконометрики временных рядов - оцениванию периода (цикла).
67. Идентификация моделей
Под идентификацией моделей обычно понимают выявление их структуры и оценивание параметров. Поскольку структура - это тоже параметр, хотя и нечисловой (см. главу 8), то речь идет об одной из типовых задач эконометрики - оценивании параметров.
Проще всего задача оценивания решается для линейных (по параметрам) моделей с гомоскедастичными независимыми остатками. Восстановление зависимостей во временных рядах может быть проведено на основе методов наименьших квадратов и наименьших модулей, рассмотренных в главе 5 моделей линейной (по параметрам) регрессии. На случай временных рядов переносятся результаты, связанные с оцениванием необходимого набора регрессоров, в частности, легко получить предельное геометрическое распределение оценки степени тригонометрического полинома.
Однако на более общую ситуацию такого простого переноса сделать нельзя. Так, например, в случае временного ряда с гетероскедастичными и автокоррелированными остатками снова можно воспользоваться общим подходом метода наименьших квадратов, однако система уравнений метода наименьших квадратов и, естественно, ее решение будут иными. Формулы в терминах матричной алгебры, о которых упоминалось в главе 5, будут отличаться. Поэтому рассматриваемый метод называется "обобщенный метод наименьших квадратов (ОМНК)".
Замечание. Как уже отмечалось в главе 5, простейшая модель метода наименьших квадратов допускает весьма далекие обобщения, особенно в области системам одновременных эконометрических уравнений для временных рядов. Для понимания соответствующей теории и алгоритмов необходимо профессиональное владение матричной алгеброй. Поэтому мы отсылаем тех, кому это интересно, к литературе по системам эконометрических уравнений [4-9] и непосредственно по временным рядам, в которой особенно много интересуются спектральной теорией, т.е. выделением сигнала из шума и разложением его на гармоники. Подчеркнем в очередной раз, что за каждой главой настоящей книги стоит большая область научных и прикладных исследований, вполне достойная того, чтобы посвятить ей много усилий. Однако из-за ограниченности объема книги мы вынуждены изложение сделать конспективным.
68. Косвенный метод наименьших квадратов (КМНК)
КМНК. Применяется в случае точно идентифицируемой модели. Процедура применения КМНК предполагает выполнение следующих этапов: 1. Составляют приведенную форму модели и определяют численные значения параметров для каждого ее уравнения обычным МНК. 2. путем алгебраических преобразований переходят от приведенной формы к уравнениям структурной формы модели, получая тем самым численные оценки структурных параметров.
Эконометрические методы следует использовать как составную часть научного инструментария практически любого технико-экономического исследования. Оценка точности и стабильности технологических процессов, разработка адекватных методов статистического приемочного контроля и статистического контроля технологических процессов, оптимизация выхода полезного продукта методами планирования экстремального эксперимента в химико-технологических системах, повышение качества и надежности изделий, сертификация продукции, диагностика материалов, изучение предпочтений потребителей в маркетинговых исследованиях, применение современных методов экспертных оценок в задачах принятия решений, в частности, в стратегическом, инновационном, инвестиционном менеджменте, при прогнозировании - везде полезна эконометрика.
69. Двухшаговый метод наименьших квадратов (ДМНК)
ДВУХШАГОВЫЙ МНК. (ДМНК)
Основная идея ДМНК — на основе приведенной формы модели получить для сверхидентифицируемого уравнения теоретические значения эндогенных переменных, содержащихся в правой части уравнения. Далее, подставив их вместо фактических значений, можно применить обычный МНК к структурной форме сверхидентифицируемого уравнения. Метод получил название двухшагового МНК, ибо дважды используется МНК: на первом шаге при определении приведенной формы модели и нахождении на ее основе оценок теоретических значений эндогенной переменной 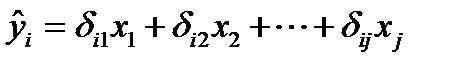 (85.1)
(85.1)
и на втором шаге применительно к структурному сверхидентифицируемому уравнению при определении структурных коэффициентов модели по данным теоретических (расчетных) значений эндогенных переменных.
Сверхидентифицируемая структурная модель может быть двух типов:
• все уравнения системы сверхидентифицируемы;
• система содержит наряду со сверхидентифицируемыми точно
идентифицируемые уравнения.
Если все уравнения системы сверхидентифицируемые, то для оценки структурных коэффициентов каждого уравнения используется ДМНК. Если в системе есть точно идентифицируемые уравнения, то структурные коэффициенты по ним находятся из системы приведенных уравнений.
Применим ДМНК к простейшей сверхидентифицируемой
модели:
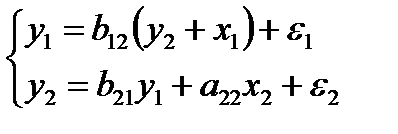 (85.2)
(85.2)
Данная модель может быть получена из предыдущей идентифицируемой модели:
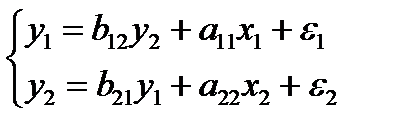 (85.3)
(85.3)
если наложить ограничения на ее параметры, а именно: b12 =a11
В результате первое уравнение стало сверхидентифицируемым: Н=1 (у1),
D=1(х2) и D+1 > Н. Второе уравнение не изменилось и является точно идентифицируемым: Н = 2 и D=1
На первом шаге найдем приведенную форму модели, а
именно:
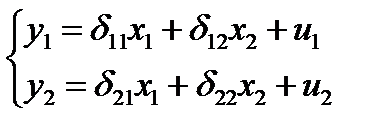 (85.4)
(85.4)
ДМНК является наиболее общим и широко распространенным методом решения системы одновременных уравнений.
Несмотря на важность системы эконометрических уравнений, на практике часто не принимают во внимание некоторые взаимосвязи, применение традиционного МНК к одному или нескольким уравнениям также широко распространено в эконометрике. В частности, при построении производственных функций анализ спроса можно вести, используя обычный МНК.
70. Основные результаты в вероятностной модели
В классической вероятностной модели имеют элементы исходной выборки x1, x2, ..., xnрассматриваются как независимые одинаково распределенные случайные величины. Как правило, существует некоторая константа C > 0 такая, что в смысле сходимости по вероятности
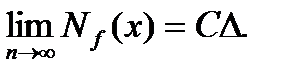 (86.1)
(86.1)
Соотношение (86.1) доказывается отдельно для каждой конкретной задачи.
При использовании классических эконометрических методов в большинстве случаев используемая статистика f (x) является асимптотически нормальной. Это означает, что существуют константы а и 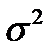 такие, что
такие, что
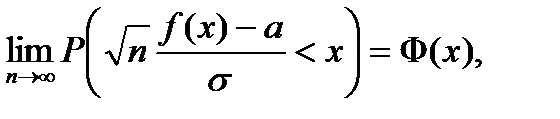
где 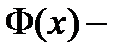 функция стандартного нормального распределения с математическим ожиданием 0 и дисперсией 1. При этом обычно оказывается, что
функция стандартного нормального распределения с математическим ожиданием 0 и дисперсией 1. При этом обычно оказывается, что
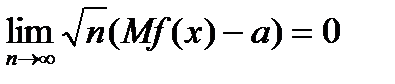
и
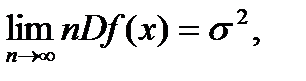
а потому в классической эконометрике средний квадрат ошибки статистической оценки равен

с точностью до членов более высокого порядка.
В статистике интервальных данных ситуация совсем иная - обычно можно доказать, что средний квадрат ошибки равен
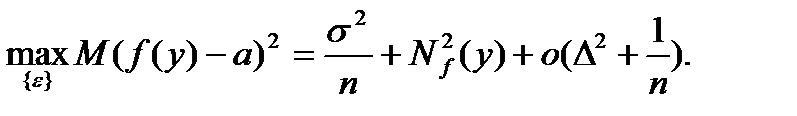 (86.2)
(86.2)
Из соотношения (86.2) можно сделать ряд важных следствий. Прежде всего отметим, что правая часть этого равенства, в отличие от правой части соответствующего классического равенства, не стремится к 0 при безграничном возрастании объема выборки. Она остается больше некоторого положительного числа, а именно, квадрат нотны. Следовательно, статистика f(x) не является состоятельной оценкой параметра a. Более того, состоятельных оценок вообще не существует.
Пусть доверительным интервалом для параметра a, соответствующим заданной доверительной вероятности 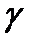 , в классической математической статистике является интервал
, в классической математической статистике является интервал 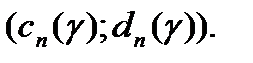 В статистике интервальных данных аналогичный доверительный интервал является более широким. Он имеет вид
В статистике интервальных данных аналогичный доверительный интервал является более широким. Он имеет вид 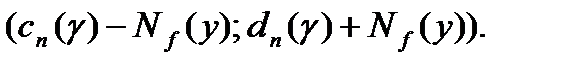 Таким образом, его длина увеличивается на две нотны. Следовательно, при увеличении объема выборки длина доверительного интервала не может стать меньше, чем
Таким образом, его длина увеличивается на две нотны. Следовательно, при увеличении объема выборки длина доверительного интервала не может стать меньше, чем 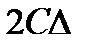 (см. формулу (86.1)).
(см. формулу (86.1)).
В статистике интервальных данных методы оценивания параметров имеют другие свойства по сравнению с классической математической статистикой. Так, при больших объемах выборок метод моментов может быть заметно лучше, чем метод максимального правдоподобия (т.е. иметь меньший средний квадрат ошибки - см. формулу (86.2)), в то время как в классической математической статистике второй из названных методов всегда не хуже первого.
71. Модели авторегрессии
Если на величину зависимой переменной текущего периода (уt) оказывают влияние ее значения в прошлые моменты времени (yt-1, yt-2,…), то эти процессы обычно описываются с помощью моделей авторегрессии. Например,
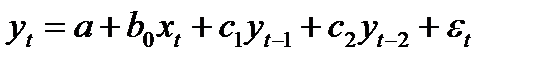 (87.1)
(87.1)
Построение моделей с распределенным лагом и моделей авторегрессии имеет свою специфику:
оценка параметров моделей авторегрессии, а в большинстве случаев и моделей с распределенным лагом не может быть произведена с помощью обычного МНК и требует специальных статистических методов;
приходится решать проблему выбора оптимальной величины лага и определения его структуры;
между моделями с распределенным лагом и моделями авторегрессии существует определенная взаимосвязь, и в некоторых случаях необходимо осуществлять переход от одного типа моделей к другому.
Рассмотрим модель с распределенным лагом в ее общем виде:
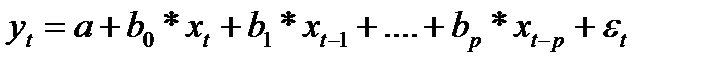
 (87.2)
(87.2)
Коэффициент 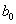 характеризует среднее абсолютное изменение уt при изменении хt на единицу в момент времени t, без учета воздействия лаговых значений фактора х. Этот коэффициент называют краткосрочным мультипликатором.
характеризует среднее абсолютное изменение уt при изменении хt на единицу в момент времени t, без учета воздействия лаговых значений фактора х. Этот коэффициент называют краткосрочным мультипликатором.
В момент (t+1) совокупное воздействие факторной переменной х 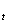 на результат y составит (b0 + b1) условных единиц, в момент (t+2) это воздействие можно охарактеризовать суммой (b0 + b1 + b2) и т. д.. Полученные таким образом новые коэффициенты называют промежуточными мультипликаторами.
на результат y составит (b0 + b1) условных единиц, в момент (t+2) это воздействие можно охарактеризовать суммой (b0 + b1 + b2) и т. д.. Полученные таким образом новые коэффициенты называют промежуточными мультипликаторами.
Введем обозначение: b0 + b1+….+ bl = b (87.3)
Величину b называют долгосрочным мультипликатором. Он показывает абсолютное изменение в долгосрочном периоде t+  результата у под влиянием изменения на единицу фактора х.
результата у под влиянием изменения на единицу фактора х.
Положим 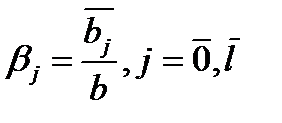 . (87.4)
. (87.4)
Полученные величины называются относительными коэффициентами модели с распределенным лагом.
Очевидно, что если 0< βj<1 и 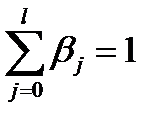
В этом случае относительные коэффициенты βj являются весами для соответствующих коэффициентов. Каждый из них изменяет долю общего изменения результативного признака в момент времени (t+j). На основе величин βj можно определить две важные характеристики модели множественной регрессии: величину среднего и медианного лага.
Средний лаг определяется по формуле 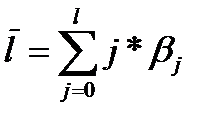 и представляет собой средний период, в течение которого будет происходить изменение результата под воздействием изменения фактора в момент времени t. Небольшая величина среднего лага свидетельствует об относительно быстром реагировании результата на изменение фактора, высокое его значение о том, что воздействие фактора на результат будет сказываться в течение длительного периода времени.
и представляет собой средний период, в течение которого будет происходить изменение результата под воздействием изменения фактора в момент времени t. Небольшая величина среднего лага свидетельствует об относительно быстром реагировании результата на изменение фактора, высокое его значение о том, что воздействие фактора на результат будет сказываться в течение длительного периода времени.
Медианный лаг - это величина лага, для которого .
Это тот период времени, в течение которого будет реализована половина общего воздействия фактора на результат.
Рассмотрим теперь модель авторегрессии:
yt =a + b0*xt +c1 *et-1 +εt (87.5)
Параметров b 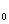 имеет тот же смысл, что и в модели с распределенным лагом (1).Общее абсолютное изменение результата в момент (t+1) составит , в момент времени (t+2) абсолютное изменение результата составит:
имеет тот же смысл, что и в модели с распределенным лагом (1).Общее абсолютное изменение результата в момент (t+1) составит , в момент времени (t+2) абсолютное изменение результата составит:
b0* c12 единиц и т.д.
Долгосрочный мультипликатор в модели авторегрессии рассчитывается как сумма как сумма краткосрочного и промежуточных мультипликаторов: b = b0 + b0c1 + b0c12 + b0c13+…. (87.6)
Обычно во всех моделях авторегрессии вводится условие стабильности, состоящее в том, что коэффициент регрессии при переменной по абсолютной величине меньше единицы.
72. Рациональный объем выборки.
Анализ формулы (3) показывает, что в отличие от классической математической статистики нецелесообразно безгранично увеличивать объем выборки, поскольку средний квадрат ошибки остается всегда большим квадрата нотны. Поэтому представляется полезным ввести понятие "рационального объема выборки" nrat, при достижении которого продолжать наблюдения нецелесообразно.
Как установить "рациональный объем выборки"? Можно воспользоваться идеей "принципа уравнивания погрешностей", выдвинутой в монографии [8]. Речь идет о том, что вклад погрешностей различной природы в общую погрешность должен быть примерно одинаков. Этот принцип дает возможность выбирать необходимую точность оценивания тех или иных характеристик в тех случаях, когда это зависит от исследователя. В статистике интервальных данных в соответствии с "принципом уравнивания погрешностей" предлагается определять рациональный объем выборки nrat из условия равенства двух величин - метрологической составляющей, связанной с нотной, и статистической составляющей - в среднем квадрате ошибки (3), т.е. из условия
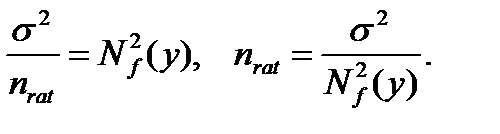
Для практического использования выражения для рационального объема выборки неизвестные теоретические характеристики необходимо заменить их оценками. Это делается в каждой конкретной задаче по-своему.
Исследовательскую программу в области статистики интервальных данных можно "в двух словах" сформулировать так: для любого эконометрического алгоритма анализа данных (алгоритма прикладной статистики) необходимо вычислить нотну и рациональный объем выборки (или иные величины из того же понятийного ряда, возникающие в многомерном случае, при наличии нескольких выборок и при иных обобщениях описываемой здесь простейшей схемы). Затем проследить влияние погрешностей исходных данных на точность оценивания, доверительные интервалы, значения статистик критериев при проверке гипотез, уровни значимости и другие характеристики статистических выводов. Очевидно, классическая математическая статистика является частью статистики интервальных данных, выделяемой условием  = 0.
= 0.
Дата добавления: 2015-05-21; просмотров: 1550;