СИСТЕМЫ
10.1.Общие сведения
Мы уже отмечали, что любой разумный вид человеческой деятельности основывается на информации о свойствах состояния и поведения той части реального мира, с которой связана эта деятельность. По мере усложнения человеческого общества возрастал и объем соответствующей информации, что сделало необходимым создание систем ее сбора, хранения и обработки. ИТ существуют уже многие десятки и даже сотни лет и долгое время представляли собой различного рода картотеки или архивы бумажных документов. Появление компьютеров позволило в значительной мере автоматизировать информационную деятельность, что привело к созданию автоматизированных информационных систем (АИС).
Можно определить автоматизированную информационную систему как базирующийся на компьютерных технологиях комплекс аппаратных, программных, информационных, организационных и человеческих ресурсов, предназначенный для создания и поддержки информационной модели какой-либо части реального мира (называемой предметной областью АИС) с целью удовлетворения информационных потребностей пользователей.
Не следует думать, что любая автоматизированная информационная система носит всеохватывающий характер. Напротив, она может входить в качестве составной части в более сложную систему, такую, как система автоматизации проектирования (САПР) или система управления производством. Размер и функции АИС определяются предметной областью, для которой она спроектирована, и если, например, предметная область охватывает лишь документооборот предприятия, то незачем искать в информационной системе сведения о зарплате.
10.2. Структура АИС
В состав любой автоматизированной системы входят следующие подсистемы: техническая, программная, информационная, организационная, а также персонал.
Рассмотрим их более подробно.
Техническое и программное обеспечение.Техническое обеспечение включает в себя компьютеры, внешние устройства и средства телекоммуникации и в этом отношении не отличается от любой компьютерной системы.
Программное обеспечение включает системное программное обеспечение, типовое прикладное программное обеспечение и специализированное прикладное программное обеспечение.
В свою очередь, в состав системного программного обеспечения входят операционная система, различные операционные оболочки пользователя, служебные программы системного администратора, сетевое программное обеспечение и т.д. Используемая операционная система в значительной мере определяет требования к остальным программным составляющим, и очень часто совокупность аппаратных средств вместе с используемой операционной системой называется аппаратно-программной платформой АИС (или просто платформой).
Типовое прикладное программное обеспечение представляет собой определяемые спецификой предметной области программы , которые не разрабатываются специально для конкретной информационной системы, а предназначены для решения широкого класса задач того же типа, хотя они могут настраиваться на конкретный случай использования именно в данной системе. В качестве примера могут быть названы такие программные продукты, как офисные программы, системы управления базами данных общего назначения, Web-серверы, программы распознавания текста, типовые системы текстового поиска и т.д. Эти программы могут быть как коммерческими, так и некоммерческими. Часто наиболее важные прикладные программы общего назначения (например, системы управления базами данных) также включают в состав платформы АИС.
К категории типового прикладного программного обеспечения следует отнести также инструментальные средства, применяемые для проектирования АИС, хотя в процессе ее эксплуатации они, как правило, не используются.
Специализированное прикладное программное обеспечение создается для конкретной информационной системы и учитывает ее особенности. Оно может быть либо комплексом программ, разработанных в какой-нибудь инструментальной среде, либо представлять собой совокупность настроек типовых программных пакетов.
Информационное обеспечение.Обрабатываемые данные играют центральную роль в информационной системе. Вместе с тем наряду с информацией, непосредственно подлежащей сбору, хранению, обработке и т.д., важную роль играют сведения, описывающие эту информацию, называемые обычно метаданными, т.е. данными о
данных, а также языковые средства, используемые для описания данных и метаданных (лингвистическое обеспечение). Наличие развитой системы метаданных является главным признаком, отличающим информационную систему от простых информационных технологий. Разумеется, сведения, описывающие обрабатываемые данные, присутствуют в любой информационной технологии, однако особенностью метаданных АИС является то, что они хранятся в самой системе, являясь ее неотъемлемой частью.
Подлежащая хранению и обработке информация обычно группируется в соответствии с типовыми структурами, которые называются моделями данных. Сформированная таким образом информация называется базой данных. Еще раз подчеркнем, что база данных содержит полное описание содержащейся в ней информации, включая описание собственной структуры. Программные средства общего назначения, предназначенные для работы с базой данных, называются системой управления базой данных (СУБД). Из числа систем, предназначенных для создания АИС предприятий (корпоративных АИС) назовем Oracle, DB2, MS SQL Server.
Организационное обеспечение.Организационная составляющая является важным элементом информационной системы, хотя очень часто ей уделяется недостаточное внимание. Она включает в себя в первую очередь проектную и эксплуатационную документацию, а также типовые процедуры работы с АИС. Сюда же следует отнести систему подготовки обслуживающего персонала и конечных пользователей к эксплуатации АИС. Можно сказать, что организационная подсистема является связующим звеном между информационной системой и ее пользователями.
Обслуживающий персонал.Последним по счету (но не по важности) компонентом информационной системы являются люди, которые обеспечивают ее функционирование. Обычно их делят на разработчиков, администраторов и операторов. Не всегда между ними можно провести четкую грань, однако, не вдаваясь в подробности, можно сказать, что разработчики создают и модифицируют систему, администраторы устанавливают режим функционирования системы и организуют устранение аварийных ситуаций, операторы же осуществляют неспецифическое взаимодействие с системой (выполняют резервное копирование данных, устанавливают бумагу в принтер и т.д.).
10.3. Классификация АИС
Информационные системы классифицируются по разным признакам. Рассмотрим наиболее часто используемые способы классификации.
Классификация по масштабу.По масштабу информационные системы подразделяются на следующие типы: одиночные, групповые и корпоративные.
Одиночные информационные системы, или автоматизированные рабочие места (АРМ), реализуются, как правило, на отдельном персональном компьютере. Такая система может содержать несколько простых приложений, связанных общей тематикой и информацией, и рассчитана на работу одного пользователя или нескольких пользователей, разделяющих по времени одно рабочее место.
Групповые информационные системы (системы масштаба подразделения) ориентированы на коллективное использование информации членами одного или нескольких родственных отделов предприятия и чаще всего строятся на базе локальной вычислительной сети. При разработке таких систем используются серверы баз данных (SQL-серверы), позволяющие эффективно использовать совместные данные.
Корпоративные информационные системы (системы масштаба предприятия) являются развитием групповых систем и могут поддерживать территориально разнесенные узлы или сети. Для таких систем характерна сложная архитектура с несколькими серверами.
Для групповых и корпоративных систем существенно повышаются требования к надежности функционирования и сохранности данных, что, в частности, требует обязательного наличия одного или нескольких администраторов среди обслуживающего персонала.
Классификация по сфере применения.По сфере применения информационные системы обычно подразделяются на четыре группы:
• системы обработки транзакций;
• системы поддержки принятия решений;
• информационные-справочные системы;
• офисные информационные системы.
Системы обработки транзакций (Online Transaction Processing — OLTP) предназначены для поддержания адекватного отображения предметной области в информационной системе в любой момент времени.
Для них характерен регулярный поток довольно простых подлежащих обработке работ, например заказов, платежей, запросов от большого числа пользователей. Основными требованиями к ним являются:
• высокая производительность обработки;
• непротиворечивость и согласованность хранимой информации в любой момент времени;
• защита от несанкционированного доступа, программных и аппаратных сбоев.
Системы поддержки принятия решений (аналитические системы) представляют собой другой тип информационных систем,
которые ориентированы на выполнение более сложных запросов, требующих статистической обработки исторических (накопленных за некоторый промежуток времени) данных в различных разрезах: временных, географических и т.п., моделирования процессов предметной области, прогнозирования развития тех или иных явлений. Аналитические системы также часто включают средства обработки информации на основе методов искусственного интеллекта, средства графического представления данных. Эти системы оперируют большими объемами исторических данных, позволяя выделить из них содержательную информацию: получить знания
из данных.
Обширный класс информационных-справочных систем основан на текстовых и гипертекстовых документах и мультимедиа. Наибольшее развитие такие информационные системы получили в сети Интернет.
Класс офисных информационных систем нацелен на перевод бумажных документов в электронный вид, автоматизацию делопроизводства и управление документооборотом.
Приведенная классификация по сфере применения в достаточной степени условна. Крупные информационные системы очень часто обладают признаками всех перечисленных выше классов. Кроме того, корпоративные информационные системы масштаба предприятия обычно состоят из ряда подсистем, относящихся к различным сферам применения.
Классификация по функциональному назначению.Еще одним способом классификации информационных систем является их классификация в зависимости от предметной области. Этот способ, конечно, не может быть исчерпывающим, поскольку количество предметных областей не ограничено. Тем не менее, он позволяет достаточно точно охарактеризовать ту или иную систему. Например, в сфере управления предприятием можно выделить следующие информационные системы:
• бухгалтерского учета;
• управления складскими ресурсами, поставками и закупками;
• управления маркетингом;
• документооборота;
• оперативного управления;
• предоставления оперативной и сводной информации и др.
Классификация по виду поддерживаемых информационных ресурсов.Здесь обычно выделяются два больших класса: документо-графические и фактографические системы.
В документографических системах основной информацией являются документы на естественных языках либо другие целостные информационные объекты (аудиозаписи, видеофильмы и т.п.). Основной функцией таких систем является поиск объекта или объектов, удовлетворяющих заданным условиям, в связи с чем
класс документографических систем фактически совпадает с информационными-поисковыми.
В фактографических же системах информация хранится в структурированном виде на основе той или иной модели данных, вследствие чего такие системы называют системами с базами данных.
Другие виды классификации.Конечно же, приведенные способы классификации не исчерпывают всех возможностей классификации. Приведем еще несколько свойств информационных систем, которые могут быть положены в основу той или иной классификации:
• объем информационных ресурсов и состав системного персонала, а также возможное количество пользователей;
• среда хранения и динамика информационных ресурсов;
• архитектура и способы доступа к системе;
• ограничения доступа к системе;
• программно-аппаратная платформа.
Список характеристик АИС можно было бы продолжить, однако уже приведенного достаточно, чтобы продемонстрировать большое многообразие информационных систем.
Контрольные вопросы
1. Может ли на одном компьютере размещаться несколько АИС? А одна АИС на нескольких компьютерах?
2. В каких случаях необходимо создание АИС?
3. Как называется часть реального мира, моделируемая информационной системой?
4. Опишите составные части АИС.
5. Что такое метаданные?
6. Что означает понятие модели данных?
7. Опишите функции обслуживающего персонала АИС.
8. Назовите причины многообразия информационных систем.
ГЛАВА 11 СИСТЕМЫ, ОСНОВАННЫЕ НА ЗНАНИЯХ
11.1. Знания
Со времен изобретения компьютера человек стремился использовать его для решения все более сложных задач. Поэтому с тех самых времен возникла необходимость изложения знаний, которые он использует для решения этих задач, в форме, пригодной для обработки с помощью компьютера. Но прежде, чем говорить о способах представления знаний в памяти компьютера, необходимо пояснить, что такое знания и чем они отличаются от данных.
Данные — это отдельные факты, характеризующие конкретные объекты, процессы и явления предметной области, а также их свойства. Знания — это закономерности предметной области (принципы, связи, законы), полученные в результате практической деятельности и профессионального опыта и позволяющие специалистам решать задачи в этой области.
Поясним на примерах эти определения. Следующая запись взята из журнала, который ведется в мастерской автосервиса.
«Марка автомобиля — ВАЗ 21053; номер — А6780Р 77; контактный телефон владельца — 345-67-34; неисправность — двигатель останавливается на холостом ходу».
Эта запись содержит в лаконичной форме фрагмент описания предметной области: на ремонте в мастерской находится машина определенной марки, имеющая определенный номер, с владельцем которой можно связаться по указанному телефону и в которой имеется конкретная неисправность, требующая устранения. Таким образом, приведенная запись отражает вполне определенные фактические данные.
Следующий пример относится к той же предметной области.
«ЕСЛИ двигатель останавливается на холостом ходу и зажигание в цилиндрах двигателя выставлено правильно, ТО возможная причина неисправности — засорены жиклеры холостого хода».
Приведенная фраза описывает определенную закономерность предметной области (т.е. относящуюся ко всем автомобилям с карбюраторным двигателем) и содержит в себе знание специалиста по ремонту двигателей, приобретенное им опытным путем за время работы в автосервисе либо полученное в результате обучения, т. е.
от другого специалиста. Опытный мастер обладает большим набором утверждений подобного рода (не только по диагностике неисправностей, но и по их устранению), многие из которых имеют вид «ЕСЛИ — ТО», как приведенное ранее.
Следует отметить, что деление информации на классы «данные» и «знания» довольно условно, часто фактические данные (или просто факты) относят к знаниям специального вида, которые представляются в виде: ААВ, где А — символьная строка, указывающие на имя конкретного объекта или ситуации, В — символьная строка или число, а знак А обозначает один из математических знаков =, >, <, <, > или е.
Например, «марка = ВА321053», «неисправность = двигатель останавливается на холостом ходу», «температура <37», «цвет изделия е {черный, синий, красный}».
Первым подходом к строгому (формализованному) представлению знаний стал алгоритмический, или процедурный, подход. Развитие этого подхода было связано со значительными успехами в развитии языков программирования — от языка машинных кодов до языков высокого уровня (Фортран, Паскаль, Си, Модула и др.). Основная суть этого подхода заключается в том, что знания и процедуры их обработки выражаются в виде жесткой последовательности действий (алгоритма), предписываемых к исполнению компьютером. При таком подходе разработанная прикладная программа составляет единое целое со знаниями. Относительно быстро выяснилось, что такой подход влечет за собой следующие недостатки:
• увеличение сложности решаемых задач приводит к тому, что программы становятся все сложнее для понимания, и поэтому затрудняется их разработка;
• изменения, происходящие в предметной области, как правило, требуют корректировки алгоритма решения задачи, а это, в свою очередь, влечет повторное написание отдельных фрагментов программы, а иногда и всей программы целиком.
Необходимым условием возможности решения задачи, используя процедурный подход, является наличие четкого алгоритма. Поэтому автоматизация коснулась прежде всего так называемых формализованных задач, алгоритм решения которых-хорошо известен (например, задача расчета заработной платы).
Однако в практической деятельности человек чаще сталкивается с задачами совсем другого типа, для которых характерны следующие особенности:
• алгоритм решения задачи неизвестен или не может быть использован из-за ограниченности памяти и быстродействия компьютера;
• задача не может быть записана в числовой форме (например, задача медицинской или технической диагностики).
Такие задачи принято называть плохо формализуемыми.
Попытка устранить перечисленные выше недостатки процедурного подхода, а также попытка решения плохо формализуемых задач привели к формированию нового направления — инженерии знаний. В основе этого направления лежит идея выделения знаний из программного обеспечения компьютера и превращения их в отдельную компоненту — базу знаний. Знания, хранящиеся в базе знаний, представляются в конкретной единообразной форме, что дает возможность их легкого определения, модификации и пополнения. Решение же задач реализуется с помощью логических выводов, делаемых на основании знаний. Для этого предусмотрен отдельный модуль логического вывода, который, собственно, и составляет основную часть программного обеспечения. Системы, построенные по такому принципу, называются системами, основанными на знаниях, или интеллектуальными системами. Наиболее значительное практическое достижение в области инженерии знаний представляет специальный класс интеллектуальных систем — экспертные системы, которые предназначены для решения разнообразных задач в конкретных областях человеческой деятельности без участия квалифицированных специалистов.
Знания, относящиеся к любой предметной области, обычно существуют в двух видах: общедоступные и индивидуальные. Общедоступные знания — это факты, определения, теории, которые обычно изложены в учебниках и справочниках по данной области. Но, как правило, специалисты в данной предметной области — эксперты — обладают еще и индивидуальными знаниями, которые отсутствуют в литературе. Эти личные знания основываются на собственном опыте эксперта, накопленном в результате многолетней практики, и в значительной мере состоят из эмпирических, т.е. основанных на опыте, правил, которые принято называть эвристиками. Эвристики позволяют экспертам выдвигать разумные предположения и находить перспективные подходы к решению плохо формализуемых задач.
11.2. Модели представления знаний
Знания в базе знаний должны быть представлены в определенной форме. Форма представления знаний зависит от решаемой задачи и оказывает существенное влияние на характеристики и свойства разрабатываемой системы. Поэтому представление знаний является одной из наиболее важных проблем при разработке программных интеллектуальных систем.
Поскольку логический вывод и действия над знаниями выполняют специальные программы, знания нельзя представлять непосредственно в том виде, в котором они используются челове-
ком (например, в виде простого текста). Поэтому для представления знаний разрабатываются математически строгие модели представления знаний.
В настоящее время существуют десятки моделей представления знаний для различных предметных областей. Большинство из них сводится к следующим классам:
• продукционная модель;
• модель семантической сети;
• модель, основанная на фреймах;
• логическая модель.
Рассмотрим основные концепции, лежащие в основе этих моделей.
11.2.1. Продукционная модель
Еще в 60-е годы прошлого столетия американские исследователи в области искусственного интеллекта А. Ньюэлл и Г. Саймон показали, что во многих случаях человеческие рассуждения могут быть представлены в виде последовательности, состоящей из предложений, каждое из которых записывается:
ЕСЛИ (условие) ТО (действие),
где под «условием» понимается один или несколько фактов, соединенных логическими операторами AND (И), OR (ИЛИ), NOT (НЕ), а под «действием» — одна или несколько операций по обработке данных, выполняемых, если в рассматриваемой ситуации «условие» истинно. Предложения такого вида называются правилами продукции, а интеллектуальные системы с базами знаний, состоящими из правил, называются продукционными системами. Отметим, что при описании знаний в виде правил продукции часто используются следующие форматы записи правил:
IF (условие) THEN (действие) или (условие) -> (действие) Логический вывод в продукционных системах может выполняться в соответствии с двумя разными стратегиями, которые называются прямой и обратной цепочками рассуждений. Поясним эти стратегии вывода на следующем примере. Пусть база знаний состоит из четырех правил:
П1: IF A = a, AND В = b, THEN Z := z,;
П2: IF С = с, AND D = d, THEN В := b,;
ПЗ: IF С = Ci AND D = d2 THEN В := b2;
П4: IF A = a, THEN D := d,.
Отметим, что в этих правилах действия, т.е. THEN-части правил, являются просто операторами присваивания определенных значений переменным Z, В и т.д. Каждое такое действие можно
интерпретировать как появление нового факта. Так, например, правило П4 утверждает, что, если имеет место факт А = аь то объекту с именем D надо присвоить значение (D := d,) и, тем самым, мы получим факт D = d,. Важным понятием в продукционных системах является доска объявлений, которая представляет собой область оперативной или внешней памяти системы, куда записываются:
• факты, известные до начала вывода;
• факты, ставшие результатом исполнения правил в ходе вывода. Условие правила выполняется, если соответствующие ему факты содержатся на доске объявлений.
Пусть вначале доска объявлений содержит факты А = а, и С = С[. Мы хотим выяснить: что следует из этих фактов, т. е. какие новые факты можно получить, используя правила базы знаний. Логический вывод в соответствии с прямой цепочкой рассуждений происходит по следующей схеме. На первом шаге система просматривает все правила в базе знаний и находит первое правило, для которого условие, т.е. IF-часть является истинной при наличии фактов, выставленных на доске объявлений. В нашем случае это правило П4 — для него IF-часть истинна, т.к. на доске объявлений есть факт А = ах. Этот шаг называется согласованием. На втором шаге выполняется действие, записанное в THEN-части согласованного правила П4, и факт D = d[ помещается на доску объявлений. Этот шаг называется исполнением правила.
Далее система просматривает снова все правила, кроме исполненного П4, и находит первое правило, для которого IF-часть истинна при наличии всех фактов на уже обновленной доске объявлений. Видно, что наличие факта С = С] и появление факта D = d[ дает в результате согласование с правилом П2.
Исполнение правила П2 приводит к обновлению доски объявлений: на ней появляется новый факт В = Ь,. Далее процедура согласования и исполнения правил повторяется аналогично до тех пор, пока еще существуют правила, которые можно согласовать с фактами, помещенными на доску объявлений. Результатом логического вывода будет состояние доски объявлений в момент остановки алгоритма. Для рассматриваемого примера: это новые факты Z = zb В = bb D = d! и факты А = аь С = сь известные до начала вывода.
Понятно, почему такой вывод называется прямой цепочкой вывода — поиск новой информации происходит в направлении стрелок, разделяющих левые и правые части правил. На рис. 11.1 детально показано, как работает цепочка прямого вывода, при этом в базе знаний выделено то единственное правило, которое исполняется на данном шаге.
Необходимость в обратной цепочке рассуждений возникает в следующей ситуации. Предположим, мы хотим использовать базу
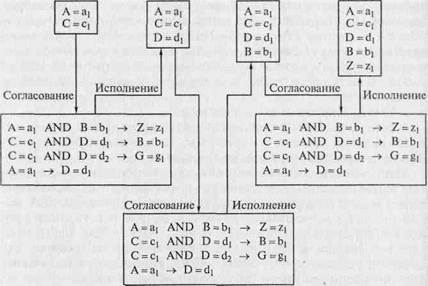
Рис. 11.1. Прямая цепочка рассуждений
знаний для того, чтобы установить конкретный факт, например Z = zb имея ту же исходную информацию, что и в предыдущем случае. Иными словами, система должна нам ответить на вопрос: верно ли что из фактов А = а, и С = с, следует факт Z = z,? Искомый факт называется целью, а переменная Z — переменной цели.
В принципе, цель можно достигнуть, если использовать прямую цепочку рассуждений. В конце работы алгоритма надо будет только просмотреть доску объявлений, чтобы выяснить: находится среди полученного множества различных фактов интересующий нас или нет. Если правил немного, такой подход вполне допустим, но, если база знаний содержит несколько сотен правил, то будет исполнено много правил, которые не имеют ничего общего с интересующим нас фактом.
Более эффективной будет стратегия вывода по обратной цепочке рассуждений. При этой стратегии система всегда начинает поиск нужного факта с просмотра доски объявлений. В нашем случае на доске объявлений выставлены только факты А = а, и С = сь а интересующего нас факта нет. Тогда система просматривает все правила, начиная с первого, чтобы найти то из них, в котором в THEN-части стоит оператор присваивания Z := z,. В данном случае это правило Ш. Найдя это правило, система решает, что ей необходимо установить факты А = а{ и В = Ьь стоящие в IF-части
правила. Система пытается установить первый факт, сначала проверяя доску объявлений. В данном случае это сразу приводит к успеху, так как факт А = а] находится на доске объявлений. Тогда система ставит перед собой промежуточную цель: установить, имеет ли место второй факт В = Ь,. Поскольку этот факт отсутствует на доске объявлений, система пытается найти правило, в THEN-части которого выполняется действие В := Ь,. Правило П2 удовлетворяет этому требованию.
На следующем шаге система пытается установить факты С = С] nD = db содержащиеся в IF-части П2. Первый факт выставлен на доску объявлений. Второй факт D = d, становится очередной промежуточной целью системы. Поскольку его нет на доске объявлений, система находит правило, у которого в правой части стоит оператор присваивания D := du Таким правилом является П4. IF-часть правила П4 выполнена, так как факт А = а, выставлен на доске объявлений.
В результате проделанных шагов сформировалась цепочка связанных между собой правил П1 — П2 —П4. Теперь система начинает проход по этой цепочке в обратном направлении:
1) из факта А = а, (он выставлен на доску объявлений) следует факт D = dj (исполняется правило П4);
2) из фактов D = d, и С = с, следует факт В = Ь, (исполняется правило П2);
3) из фактов В = b! и А = а, следует интересующий нас факт Z = z, (исполняется правило П1).
На этом процесс обработки правил базы знаний заканчивается.
При выводе по обратной цепочке рассуждений может возникнуть ситуация, когда для достижения некоторой цели (основной или промежуточной) необходимый факт не удается установить ни из правил базы знаний, ни из содержимого доски объявлений.
В этом случае интеллектуальная система, работающая в диалоговом режиме, задает соответствующий вопрос человеку, работающему с этой системой, например: «Верно, что В = Ь,?» или «Введите значение переменной В», и в зависимости от его ответа продолжает процесс вывода.
Мы рассмотрели задачу, когда требуется с помощью логического вывода установить истинность определенного факта. Однако во многих случаях требуется определить, какое именно значение примет переменная цели при условии, что известны некоторые факты, относящиеся к предметной области. Поясним сказанное на простом примере медицинской базы знаний*. Предварительно введем следующие обозначения для переменных, используемых при записи правил:
* База знаний носит условный характер.
G — уровень гемоглобина в крови, Т — температура, L — уровень лейкоцитов в крови, D — диагноз пациента.
База знаний:
Ш: IF G = «в норме» AND Т<37 AND T 36.4 THEN D := «здоров»;
П2: IF G = «низкий» AND T>37 THEN D := «болен»;
ПЗ: IF L<15 THEN G «в норме»;
П4: IF L> 15 THEN G «низкий».
Предположим мы хотим установить диагноз пациента (болен он или здоров), т.е. определить значение переменной цели D. Пусть перед началом логического вывода для диагностируемого пациента известны следующие факты: Т = 38,1, L = 18. Поместим эти факты на доску объявлений. Схема работы системы по обратной цепочке рассуждений такова.
Сначала будет найдено первое правило, в THEN-части которого переменной цели D присваивается какое-либо значение. В данном случае это правило Ш. Для того, чтобы Ш исполнилось, необходимо выполнение условия в IF-части. Для этого система пытается определить переменные G и Т. Переменная G становится временной целевой переменной, и система пытается определить ее значение из правил. Первое правило, в THEN-части которого переменной G присваивается значение, — правило ПЗ. Однако это правило не исполняется, так как его условие (L<15) не выполнено. Тогда ищется следующее правило для определения G. Правило П4 позволяет определить значение временной целевой переменной G = «низкий». Этот факт выставляется на доску объявлений. Значение второй переменной Т находится непосредственно из доски объявлений. Возвращаясь к правилу П1, система обнаруживает, что оно не исполняется, так как условие в его IF-части ложно.
Система ищет другое правило, в котором целевая переменная D принимает какое-либо значение. Это правило П2. Условие этого правила выполняется, так как из доски объявлений система получает все необходимые факты. Процесс вывода закончен, и диагноз пациента определен.
Отметим, что в реальных продукционных системах цепочка исполняемых правил, получающаяся при логическом выводе, может содержать значительное число правил (до нескольких десятков).
Представление знаний в виде правил продукции чаще всего используют в предметных областях, где знания формируются в результате опыта, накопленного за годы работы в данной области (т.е. как эвристики), и используются для получения рекомендаций, указаний или советов. Сильными сторонами продукционной модели являются:
• простота создания и понимания отдельных правил;
• простота пополнения и модификации;
• простота механизма логического вывода.
Однако у продукционной модели есть и слабые стороны:
• неясность взаимных отношений правил;
• сложность оценки целостного образа знаний, представленных правилами;
• отсутствие гибкости в логическом выводе.
Несмотря на указанные недостатки, большинство реальных экспертных систем построено на базах знаний, использующих правила продукции. Именно поэтому мы уделили продукционной модели большее внимание по сравнению с другими моделями представления знаний.
11.2.2. Семантические сети
Основная идея подхода к представлению знаний с помощью семантических сетей состоит в том, чтобы рассматривать предметную область как совокупность понятий и отношений между ними. В качестве понятийобычно выступают абстрактные или конкретные объекты, а отношения — это связи типа: «это», «имеет частью», «принадлежит» и др.
Семантическая сеть является наглядным способом представления такого рода знаний о предметной области в виде схемы, которая называется ориентированным графом с размеченными узлами и дугами. Поясним сказанное на примере. Если объект А находится в определенной связи S с объектом В, то это знание можно изобразить в виде такого элементарного графа (рис. 11.2).
Узлы, изображенные прямоугольниками, соответствуют объектам, а дуга в направлении от узла А к узлу В соответствует связи S. Например, фраза «Иванов работает в отделе сбыта» представляется в виде, показанном на рис. 11.3.
| А | S | В |
Такие элементарные подграфы являются базовыми функциональными элементами. Соединяясь между собой с помощью связей-дуг, они формируют семантическую сеть. На рис. 11.4 приведен фрагмент семантической сети, в котором представлены знания, относящиеся к сотрудникам и отделам фирмы. Видно, что в сети представлены как фактические данные (Петров работает начальником отдела сбыта, отдел сбыта находится в комнате № 7), так и знания более общего вида (любой сотрудник имеет право на парковку автомобиля).
| Иванов | работает | Отдел сбыта |
Рис. 11.2 Рис. 11.3
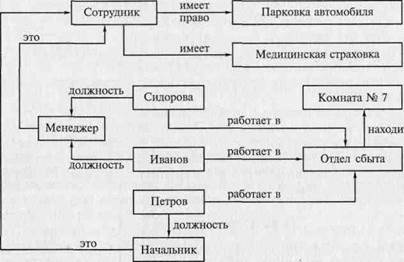
Рис. 11.4. Пример семантической сети
Наиболее часто в семантических сетях используются следующие отношения:
• связи типа «часть — целое»;
• функциональные связи (определяемые обычно глаголами «производит», «влияет», «влечет»....);
• количественные (больше, меньше, равно...);
• пространственные (далеко от, близко от, за, под, над...);
• временные (раньше, позже, в течение...);
• атрибутивные связи (иметь свойство, иметь значение...) и др.
Особая роль у связи «это». Если понятия А и В находятся в
отношении «А это В», то понятие А обладает всеми характеристиками более общего понятия В. Если при этом В находится в отношении «это» с еще более общим понятием С, то А наследует и характеристики С. Так, для семантической сети на рис. 11.4 менеджер обладает всеми свойствами и возможностями сотрудника. Поэтому для каждого менеджера фирмы не надо указывать, что он имеет право на парковку автомобиля, что у него есть медицинская страховка и т.д. Достаточно указать эти характеристики только для одного понятия — «сотрудник». Таким образом, использование отношения «это» во многих случаях позволяет компактно записывать знания.
Приведенный пример представления знаний семантической сетью ограничивался отношениями между понятиями, которые выражаются существительными и собственными именами («Иванов — менеджер», «отдел — комната» и т.д.). Однако это слишком жесткое ограничение. Необходимо уметь представлять знания,
отражающие события, т. е. действия, которые выражаются глаголами и которые могут внести изменения в предметную область. Например, может потребоваться зафиксировать утверждение:
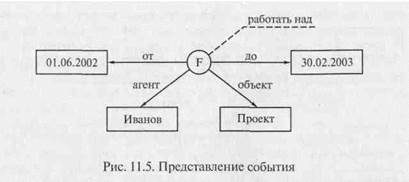
«Иванов проработал над проектом с 01.06.2002 по 30.02.2003».
Его невозможно представить с помощью до сих пор применяемых обозначений. Однако существует очень простое и вместе с тем эффективное представление этого события, показанное на рис. 11.5.
Узел, помеченный буквой F и изображаемый кружком, соответствует событию, выраженному глаголом «работал». Связь, помеченная как «агент», направлена к узлу, который соответствует исполнителю или инициатору действия (в нашем случае это Иванов). Кроме того, в событии всегда присутствует понятие, по отношению к которому направлено действие. В нашем случае таким понятием служит «проект». Событие связано с ним отношением, помечаемым как «объект».
Для того, чтобы проиллюстрировать построение семантической сети, в которой необходимо представить несколько событий разного типа, рассмотрим описание следующей ситуации на участке полностью автоматизированного производства.
«Если станок закончил обработку, робот грузит кассету с деталями на робокар, который перевозит их на склад, где штабелер помещает кассету в ячейку»*.
Выделим пять событий: станок закончил обработку (F1), робот грузит (F2), робокар перевозит (F3), кассета содержит (F4), штабелер помешает (F5). Как и в предыдущем примере, событие будем обозначать кружком, а связанные с ним понятия — прямоугольниками. Дуги пометим наименованиями отношений, которые они выражают. Схема соответствующей семантической сети приведена на рис. 11.6.
Робокар — робот-автомобиль для перевозки изделий по заданному маршруту; штабелер — автоматическое устройство (робот), которое сортирует и размещает изделия на складе.
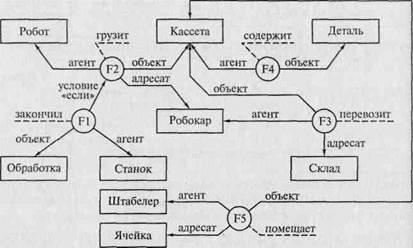
Рис. 11.6. Пример семантической сети с несколькими узлами-событиями
В системах представления знаний с помощью семантических сетей основным является информационно-поисковый режим. Запрос на получение необходимой информации представляет собой описание некоторой ситуации как набора взаимосвязанных фактов, при этом допускается использование имен неизвестных понятий и связей в виде переменных.
Запрос можно представить в виде графа, в котором метки узлов, соответствующие некоторым понятиям, не определены. Например, от оператора поступила информация, что «робокар что-то перевозит». Запрос: «что и куда перевозит робокар?» Ситуация изображается в виде графа, где событие F, выражаемое глаголом «перевозит», связано отношением «агент» с понятием «робокар», отношением «объект» с неизвестным понятием X, и, наконец,
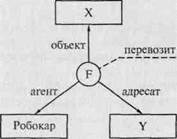
|
отношением «адресат» с неизвестным понятием Y (рис. 11.7). Ответом на запрос будут значения переменных X и Y, которые надо получить из сопоставления графа запроса с графом семантической сети, изображенной на рис. 11.6.
Сопоставление происходит сле
дующим образом. Граф запроса
вкладывается в семантическую сеть
так, что узел F совмещается с уз
лом F3, при этом одноименные дуги
Рис. 11.7. Граф запроса и узлы-прямоугольники должны со-
впасть. В результате такого совмещения узел X совпадет с узлом «кассета», а узел Y — с узлом «склад», тем самым переменные X и Y конкретизируются соответствующими значениями. Ответ будет выглядеть так: РОБОКАР ПЕРЕВОЗИТ КАССЕТУ НА СКЛАД. В настоящее время аппарат семантических сетей широко используется в системах, основанных на знаниях. Его достоинствами являются:
• большие выразительные возможности;
• естественность и наглядность представления знаний;
• близость структуры сети, представляющей систему знаний, смысловой структуре фраз естественного языка.
Для реализации семантических сетей существуют специальные языки (NET, SIMER+MIR и др.).
11.2.3. Фреймы
Термин фрейм (от англ. frame, что означает каркас или рамка) был предложен в 1974 г. американским специалистом в области интеллектуальных систем М. Минским для обозначения абстрактного образа, представляющего стереотипную ситуацию или понятие. В психологии и философии известно понятие абстрактного образа. Например, произнесение вслух слова «комната» порождает у слушающих образ комнаты: «жилое помещение с четырьмя стенами, полом, потолком, окнами и дверью, площадью 6...20 м2». Из этого описания ничего нельзя убрать (например, убрав окна, мы получим уже чулан, а не комнату), но в нем есть незаполненные части — слоты (от англ. slot, что означает отсек или щель), например, количество окон, цвет стен, высота потолка, покрытие пола и др.
В теории фреймов такой образ комнаты называется фреймом комнаты. Фреймом также называется и формализованная модель для отображения образа. Эта модель представляется в виде структуры следующего вида:
(Имя фрейма:
Имя слота 1 (значение слота 1);
Имя слота 2 (значение слота 2);
Имя слота N (значение слота N)).
Здесь слот — это именованное поле, которое содержит данные определенного типа.
Различают фреймы-образцы, или прототипы, хранящиеся в базе знаний, и фреймы- экземпляры. У фреймов-образцов слоты либо не заполнены, либо содержат ссылки на имена других фреймов. Прототипы используются для создания фреймов-экземпляров, у которых слоты, совпадающие со слотами прототипа, заполняются конкретными значениями на основе поступающих данных. На
основе одного прототипа может быть создано несколько фреймов-экземпляров, различающихся только значениями слотов.
Значением слота может быть практически что угодно: числа, формулы, имена файлов, тексты на естественном языке, правила продукции или ссылки на другие слоты данного фрейма. В качестве значения слота может выступать также имя другого фрейма, что обеспечивает связи между фреймами, их вложенность друг в друга («принцип матрешки»). Например, фрейм-экземпляр сотрудника с табельным номером 034 может выглядеть следующим образом:
(СОТРУДНИК_034: фамилия (Иванов); год рождения (1974); специальность (МЕНЕДЖЕР); стаж (6); фото (ivanov.bmp)).
В этом представлении значением слота «специальность» является фрейм МЕНЕДЖЕР.
Существует несколько способов получения слотом значений во фрейме-экземпляре:
• по умолчанию от фрейма-образца (Default-значение);
• явно из диалога с пользователем;
• по формуле, указанной в слоте;
• из базы данных.
Значения слотов могут быть вычислены с помощью соответствующих процедур, включаемых в слоты фреймов-образцов. Эти процедуры принято делить на два типа: процедуры-демоны и процедуры-слуги.
Процедуры-демоны активизируются автоматически каждый раз, когда данные попадают в соответствующий фрейм-экземпляр или удаляются из него. С помощью процедур этого типа автоматически выполняются, в частности, все рутинные операции, связанные с ведением баз данных и знаний. Пусть, например, база данных описывает транспортно-складскую систему, в которой одни и те же детали в процессе обработки меняют адреса хранения. С помощью процедур-демонов общение с системой можно организовать так, что пользователь будет сообщать лишь адрес, по которому отправляется конкретная партия деталей. Соответствующая процедура-демон активизируется автоматически, как только будет заполнен слот АДРЕС ПОЛУЧАТЕЛЯ соответствующего фрейма. В результате выполнения процедуры имя данной партии будет удалено из фрейма, описывающего предыдущее место хранения, и добавлено в фрейм нового места хранения.
Кроме указанной возможности, процедуры-демоны могут для определенных слотов проверять корректность вводимых значений.
Процедуры-слуги активизируются только по запросу. Например, если поступил запрос на просмотр фрейма, содержащего данные по конкретному сотруднику, то запускается процедура вывода на экран монитора его цифровой фотографии — растрового файла, имя которого указано в слоте ФОТО.
В заключение отметим, что основным преимуществом фреймовой модели представления знаний является то, что она отражает основы организации памяти человека, а также ее гибкость и наглядность.
Специальные языки представления знаний в сетях фреймов FRL (Frame Representation Language — язык представления фреймов), KRL (Knowledge Representation Language — язык представления знаний) и другие программные средства позволяют эффективно строить промышленные экспертные системы.
11.2.4. Логическая модель
В рамках логической модели знания представляются с помощью предикатов. Предикатом называется функция нескольких переменных р(Х, Y, ...), значениями которой могут быть логические константы ИСТИНА (TRUE) или ЛОЖЬ (FALSE) в зависимости от значений аргументов. Например, предикат родители(Х, F, М) принимает значение ИСТИНА, если для человека с именем X отцом является человек по имени F, а матерью — человек по имени М. С помощью предикатов можно представлять факты. Приведем несколько примеров такого представления:
родители{олег, иван, мария); студент(петров);
посещает(петров, лекции); процессор(Ые1 82801).
Из предикатов можно строить логические формулы с помощью операций л (И), v (ИЛИ), -, (НЕ) и —> (импликация «если — то»). Импликация играет особую роль: с ее помощью можно записывать знания общего характера (т.е. закономерности) в виде правил, например:
родители(Х, F, М) л родители^, F, М) л мужчина (Х)л
л (X Ф Y) -» брат(Х, Y).
Если у человека по имени X и человека по имени Y одни и те же родители с именами F (отец) и М (мать) соответственно, и, кроме того, X — мужчина и X не совпадает с Y, то X является братом для Y. В записи этого правила используются переменные величины X, Y, F, М, возможными значениями которых являются имена.
Обычно в логической модели вместо импликации А—>В используют эквивалентную формулу -AvB. Такая замена называется «уход от импликации». Так, вышеприведенное правило можно записать в эквивалентном виде:
-^{родители(Х, F, М) л родители^', F, М) л мужчина (Х)л
л (X ф Y)) v брат(Х, Y).
Используя законы де Моргана, эту формулу можно переписать в следующем виде:
->родители(Х, F, М) ч-лродители(У, F, M) v-i мужчина (X)
v^ (X Ф Y) v брат(Х, Y).
Рассмотрим как происходит вывод в логической модели. База знаний в этой модели состоит из набора фактов Фь Ф2, ..., Ф^. и правил Rb R2, ... Rm. Задача логического вывода формулируется следующим образом. Интересующий пользователя факт Фцель (будем называть его целевым фактом) представляется в виде соответствующего предиката. Требуется из истинности фактов и правил базы знаний вывести истинность Фиель, или, иными словами, доказать, что импликация
Ф,лФ2л ... лФ*лЫ,л ... лЯт^Фцель
принимает истинное значение.
Используя простейшие законы математической логики можно показать, что истинность этой импликации эквивалентна ложности логического произведения Ф,лФ2 л... лФ^лК,л... лРчтл-1Фцель*.
Специалистами в области математической логики был разработан алгоритм решения этой задачи, который затем был реализован в специализированном языке ПРОЛОГ (сокращение от программирование логическое).
Следует отметить, что, несмотря на строгое математическое обоснование логической модели, она практически не используется в промышленных экспертных системах. Это связано с тем, что при решении сложных задач попытка представить неформализованные знания эксперта, среди которых преобладают эвристики, в системе строгой логики наталкивается на серьезные препятствия, поскольку в отличие от строгой логики, так называемая, «человеческая логика» обладает нечеткой структурой. Поэтому большая часть достижений в области интеллектуальных систем до настоящего момента была связана с применением нелогических моделей (правила продукции, семантические сети, фреймы).
11.2.5. Представление нечетких знаний
Поскольку зачастую знания в некоторых предметных областях основываются исключительно на человеческом опыте, т.е. представляют собой эвристики, с полной определенностью никогда нельзя сказать, что они верны. Кроме того, пользователь интеллектуальной системы также не может быть полностью уверен, что факты, которые он сообщает интеллектуальной системе, абсо-
* В математике этот прием называется «доказательством от противного».
лютно корректны. Особенно часто такие ситуации возникают в задачах медицинской диагностики. Например, правило:
IF уровень гемоглобина = «в норме» AND температура < 36.9°
AND температура > 36.4° THEN диагноз := «здоров»
верно не всегда, поэтому естественно приписать ему значение некоторого коэффициента уверенности Q, который может иметь значение от 0 до 100. Чем меньше значение Q, тем меньше уверенности в том, что правило верно и, наоборот, чем больше значение Q, тем больше уверенности, что вывод, сделанный по этому правилу, верен. Значение Q, равное 100, свидетельствует об абсолютной уверенности в правильности полученного вывода, а правила, для которых значение Q равно 0 или даже меньше некоторого порогового значения (например, 20), рассматривать нет смысла. Коэффициент уверенности можно приписывать не только правилам, но и отдельным фактам.
Таким образом, возможную в продукционных системах неопределенность или нечеткость знаний можно оценивать с помощью коэффициентов уверенности. Правила в таких системах записываются в следующем модифицированном виде:
IF (условие) THEN (действие) [Q =(значение)].
Например:
П: IF уровень гемоглобина = «низкий» AND температура > 37°
THEN диагноз := «болен» [Q =90].
Правило в этом случае интерпретируется следующим образом. Если мы абсолютно уверены в фактах, входящих в условие, то полученный вывод (факт: диагноз = болен) будет иметь коэффициент уверенности Q = 90.
При таком подходе к нечетким знаниям возникает задача определения результирующего коэффициента уверенности, когда само условие правила выполняется с некоторой долей уверенности. Рассмотрим правило вида
IF A = a AND В = b THEN Z := z [Q = Qnp].
Пусть коэффициент уверенности в истинности факта А = а имеет значение QA, а коэффициент уверенности в истинности второго факта В = b — значение QB. Поскольку условие выполнено (правда, не с абсолютной уверенностью), правило будет исполнено, и мы получим новый факт Z = z. Очевидно, что результирующий коэффициент уверенности Qpe3 в истинности этого факта должен быть не больше, чем Qnp. Алгоритм вычисления Qpe3 следующий.
Вычисляется коэффициент уверенности в истинности всего условия по формуле
QycjI = min(QA, QB). Результирующий коэффициент уверенности определяется как
| Урез |
Уусл ' Упр
Пусть для приведенного выше правила П имеются такие данные:
уровень гемоглобина = «низкий» с Q = 80; температура = 37.6° с Q = 100. Условие этого правила выполнено с коэффициентом уверенности
QycJT = min(80,100) = 80.
Как результат исполнения правила П будет получен факт: диагноз = «болен» с результирующим коэффициентом уверенности:
| Qpe3 = ^T^=72. |
80-90
Если условие правила записано с использованием логической операции OR (ИЛИ), то формула для расчета Qpe3 остается той же, меняется только выражение для коэффициента уверенности самого условия — минимум заменяется на максимум. Так для правила
IF A = a OR В = b THEN Z := z [Q = Qnp]
QycjI вычисляется по формуле
QycJI = max(QA, QB).
При логическом выводе по обратной цепочке рассуждений исполнение каждого правила сопровождается расчетом коэффициента уверенности в полученном факте. Эти коэффициенты выставляются на доску объявлений вместе с самими фактами и используются при дальнейшем проходе по цепочке правил.
11.3. Экспертные системы
11.3.1. Основные понятия
В повседневной жизни мы постоянно сталкиваемся с экспертами в самых различных областях человеческой деятельности — это врачи, преподаватели, адвокаты, переводчики, секретари, программисты и т.д. Имея огромный багаж знаний, касающихся конкретной предметной области, а также довольно большой опыт в этой области, они умеют точно сформулировать и правильно решить задачу.
В течение последних десятилетий многочисленные попытки исследователей были направлены на создание систем, способных заменить специалиста в конкретной предметной области, т.е. решать задачи в отсутствие экспертов. Эти системы получили название экспертных систем (ЭС).
В ходе исследований выяснилось, что среди задач, решаемых экспертами, формализованные задачи составляют лишь малую часть, в то время как основная их масса относится к числу неформализованных. Поэтому процедурный подход к созданию экспертных систем нашел ограниченное применение, уступив место методам инженерии знаний.
Вообще надо сказать, что на сегодняшний день термины «инженерия» знаний и «экспертные системы» используются как синонимы, так же как стали фактическими синонимами термины «экспертная система» и «система, основанная на знаниях»..
Одним из наиболее популярных определений ЭС является следующее: «Под ЭС понимается система, объединяющая возможности компьютера со знаниями и опытом эксперта в такой форме, что система может предложить разумный совет или осуществить разумное решение поставленной задачи. Дополнительно желаемой характеристикой такой системы, которая многими рассматривается как основная, является способность системы пояснять по требованию ход своих рассуждений в понятной для спрашивающего форме».
Приведенное определение, а также сформулированные выше общие принципы построения систем, основанные на знаниях, позволяют выделить ряд базовых структурных элементов ЭС. Как и любая система, основанная на знаниях, ЭС обязательно содержит в своем составе базу знаний и механизм логических выводов — «мозг» ЭС. В ЭС, построенных на базе продукционной модели, зачастую для представления фактических знаний используется отдельный механизм — база данных, а в базе знаний остаются лишь правила. Кроме того, для ведения базы знаний и дополнения ее при необходимости знаниями, полученными от эксперта, требуется отдельный модуль редактирования базы знаний.
Другим важным компонентом ЭС является пользовательский интерфейс, необходимый для правильной передачи ответов пользователю в удобной для него форме. Кроме того, пользовательский интерфейс необходим и эксперту для осуществления манипуляций со знаниями.
И, наконец, в ЭС должен присутствовать модуль, который способен при помощи механизма логического вывода предложить разумный совет или осуществить разумное решение поставленной задачи, сопровождая его по требованию пользователя различными комментариями, поясняющими ход проведенных рассуждений. Модуль, реализующий эти функции, называется моду-
7 Гохберг
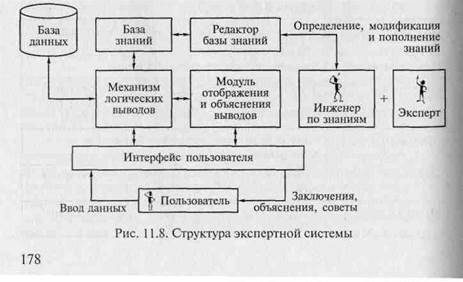
|
лем советов и объяснений. Следует отметить, что механизм объяснений играет весьма важную роль, позволяя повысить степень доверия пользователя к полученному результату. Кроме того, он важен не только для пользователя системы, но и для эксперта, который с его помощью определяет, как работает система и как используются предоставленные им знания.
Базовая структура ЭС показана на рис. 11.8. Перечисленные структурные элементы являются наиболее характерными для большинства ЭС, хотя в реальных условиях некоторые из них могут отсутствовать.
Так как терминология в области разработки ЭС постоянно модифицируется, определим основные термины, которые использованы здесь.
Пользователь — специалист предметной области, для которого предназначена система. Обычно его квалификация недостаточно высока, и поэтому он нуждается в помощи и поддержке своей деятельности со стороны ЭС.
Инженер по знаниям — специалист в области интеллектуальных систем, выступающий в роли промежуточного буфера между экспертом и базой знаний. Синонимы: когнитолог, инженер-интерпретатор, аналитик.
Интерфейс пользователя — комплекс программ, реализующих диалог пользователя с ЭС как на стадии ввода информации, так и при получении результатов.
База знаний (БЗ) — ядро ЭС, совокупность знаний предметной области, записанная на машинный носитель в форме, понятной эксперту и пользователю (обычно на некотором языке, приближенном к естественному). Параллельно «человеческому» представлению существует БЗ во внутреннем (машинном) представлении.
Модуль логического вывода — программа, моделирующая ход рассуждений эксперта на основании знаний, имеющихся в БЗ. Синонимы: дедуктивная машина, машина вывода, решатель.
Модуль объяснения выводов — программа, позволяющая пользователю получить ответы на вопросы: «Как была получена та или иная рекомендация?» и «Почему система приняла такое решение?» Ответ на вопрос «как» — это трассировка всего процесса получения решения с указанием использованных фрагментов БЗ, то есть всех шагов цепи умозаключений. Ответ на вопрос «почему» — ссылка на умозаключение, непосредственно предшествовавшее полученному решению, т. е. отход на один шаг назад. Развитые подсистемы объяснений поддерживают и другие типы вопросов.
Редактор базы знаний — программа, представляющая инженеру по знаниям возможность создавать БЗ в диалоговом режиме. Включает в себя систему вложенных меню, шаблонов языка представления знаний, подсказок («Help» — режим) и других сервисных средств, облегчающих работу с базой.
Типы экспертных систем.Одним из часто употребляемых оснований классификации экспертных систем является тип решаемых ими задач. Наиболее распространенные из них приведены в табл. 11.1.
Таблица 11.1
| Тип решаемых задач | Суть решаемых задач |
| Интерпретация | Построение описаний ситуаций по наблюдаемым данным |
| Прогноз | Вывод вероятных следствий из заданных ситуаций на основе анализа имеющихся данных |
| Диагностика | Заключение о нарушениях в системе, исходя из наблюдений |
| Проектирование | Построение конфигурации объектов при заданных ограничениях |
| Планирование | Проектирование плана действий |
| Мониторинг | Непрерывная интерпретация данных в реальном масштабе времени и сигнализация о выходе тех или иных параметров за допустимые пределы |
| Отладка | Выработка рекомендаций по устранению неисправностей |
| Обучение | Диагностика, отладка и исправление поведения ученика |
| Управление | Интерпретация, прогноз, ремонт и мониторинг поведения сложной системы |
Экспертные системы, применяемые для решения перечисленных типов задач, носят названия интерпретирующих, прогнозирующих и т. п.
Другим основанием классификации может служить тип модели предметной области. Различают статические и динамические предметные области. Предметную область называют статической, если ее модель остается неизменной за все время решения задачи, т.е. остаются неизменными набор понятий, их атрибуты, связи между ними и т.д. Если это условие не выполняется, то предметную область называют динамической. В соответствии с этим экспертные системы делятся на статические и динамические.
11.3.2. Методология разработки ЭС
По опыту известно, что большая часть знаний в конкретной предметной области остается личной собственностью эксперта. И наибольшую проблему при разработке экспертной системы представляет процедура получения знаний у эксперта и занесения их в базу знаний, называемая извлечением знаний. Это происходит не потому, что он не хочет разглашать своих секретов, а потому, что он не в состоянии сделать этого: ведь эксперт знает гораздо больше, чем сам осознает. Кроме того, обладая большими знаниями и опытом в своей предметной области, эксперт может не быть специалистом в области компьютеров и интеллектуальных систем. Поэтому для выявления знаний эксперта и их формализации на протяжении всего периода разработки системы с ним взаимодействует инженер по знаниям.
В целом процесс разработки экспертной системы носит эволюционный характер. Можно выделить следующие основных этапы эволюции экспертной системы:
• определение характеристик задачи (этап идентификации);
• поиск понятий для представления знаний (этап концептуализации);
• разработка структур для организации знаний (этап формализации);
• формулировка правил, воплощающих знания (этап реализации);
• оценка правил, в которых воплощено знание (этап испытаний).
На этапе идентификации инженер по знаниям и эксперт определяют цели и задачи построения ЭС, ее предметную область, необходимые для нее ресурсы (время, вычислительные средства). Они также указывают участников процесса создания системы (например, дополнительных экспертов).
В ходе этапа концептуализации эксперт и инженер по знаниям выявляют основные понятия, отношения и характер информаци-
онных потоков, необходимые для описания процесса решения задач в данной предметной области.
На этапе формализации инженер по знаниям производит выбор инструментального средства разработки ЭС и при помощи эксперта представляет основные понятия и отношения в рамках некоторого формализма, задаваемого выбранным средством разработки.
В ходе этапа реализации эксперт осуществляет наполнение базы знаний, а инженер по знаниям комбинирует и реорганизует формализованное знание. Результатом этого этапа является программа-прототип, которую можно выполнять и подвергать контрольным испытаниям.
Наконец, в ходе испытания проводится оценка работы программы-прототипа. Как правило, эксперт дает оценку работы программы и помогает инженеру по знаниям в последующих ее модификациях.
Иногда к рассмотренным пяти этапам добавляют шестой: этап опытной эксплуатации, в ходе которого проверяется пригодность экспертной системы для конечных пользователей.
Перечисленные этапы создания экспертной системы не являются четко очерченными, детально определенными или даже независимыми друг от друга. В лучшем случае они грубо описывают сложный процесс извлечения знаний. На каждом из них возможен откат на несколько этапов назад. Таким образом, экспертная система эволюционирует, постепенно усложняя организацию и представление знаний. Время от времени, когда появляется необходимость в новых свойствах, которых нельзя достичь, исходя из возможностей существующей системы, происходит существенная реорганизация и перестройка всей ее архитектуры.
11.3.3. Инструментальные средства разработки ЭС
Различают следующие типы инструментальных средств разработки ЭС:
• языки программирования;
• языки представления знаний (языки инженерии знаний);
• средства автоматизации разработки (проектирования);
• оболочки ЭС.
Указанные типы инструментальных средств перечислены в порядке убывания эффек
Дата добавления: 2015-01-24; просмотров: 1915;