КОРРЕЛЯЦИОННЫЕ АЛГОРИТМЫ РАСПОЗНАВАНИЯ
Корреляционные алгоритмы рассмотрим на примере распознавания символов печатного текста. Работы в области распознавания рукописных символов, плохо пропечатанных документов, надписей на изделиях, восприятия смыслового содержания сообщений с целью корректировки результатов распознавания ведутся сегодня многими коллективами.
Последовательность процедур распознавания печатного текста в ряде алгоритмов включает бинаризацию исходного изображения, определение межстрочечного интервала, сегментацию изображения, формирование эталонных образов символов, формирование признаков и т. п. Все процедуры могут проводиться как с локализацией положения распознаваемого символа, так и при пошаговом движении по всему изображению.
Рекомендуемая последовательность работы над распознаваемым текстом:
· ввести изображение текста низкого качества и сформировать его фрагмент (фрагмент следует выбрать размером не более 100 000 пикселей, это обеспечит приемлемые временные затраты на расчеты);
· выбрать один или несколько различных символов, они представят распознаваемые классы;
· уточнить признаковое описание каждого класса;
· пронормировать эталонный образ;
· сформулировать бегущий сегмент рабочего образа;
· пронормировать данные рабочего сегмента;
· вычислить корреляционное соотношение между признаковым описанием рабочего и эталонного сегмента;
· задав рабочий уровень доверия dr, определить принадлежности рассматриваемого сегмента к одному из классов;
· проанализировать результаты процедур распознавания, определив проценты ошибок и наметить пути совершенствования использованных алгоритмов.
На рис 3.14 приведен выбранный с общего изображения фрагмент текста и выбранный класс символ – с, т. е. распознаются два класса символ – с и не символ – с. Каждый класс представлен 5× 6 пикселями т. е. 30 признаками. При работе над эталонным образом можно использовать два варианта:
· эталонный образ формируется в полуавтоматическом режиме с ручной корректировкой описания символа;
· эталонный образ формируется автоматически, путем отбора описаний пикселей в обучающей последовательности, отбор может идти по мажоритарному алгоритму или через параметры гистограмм.
Учитывая временные ограничения, рекомендуется сформировать эталонный образ в полуавтоматическом режиме. Следует помнить, класс искомого символа только в упрощенном варианте представлен одним эталоном. В реальных задачах описание класса задается несколькими эталонными образами.
Нормировка эталонного образа устраняет влияние таких параметров, как средний уровень фона, освещенность символа и т. п. В простейшем случае нормировка выполняется через вычитание среднего и масштабирование по уровню сигнала, обеспечивающее заданное максимальное значение параметра доверия dm. Ниже приведены рекомендуемые формулы расчета bn - нормированного массива признаков:
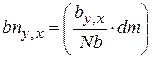 ;
;
где 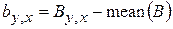 новый промежуточный массив с устранением среднего, а
новый промежуточный массив с устранением среднего, а 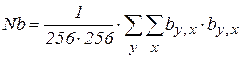 значение автокорреляционной функции, вычисленной с учетом диапазона задания описания пикселя.
значение автокорреляционной функции, вычисленной с учетом диапазона задания описания пикселя.

|
|
Рис.3.14. Фрагмент распознаваемого текста и выбранный эталонный символ
При формировании бегущего сегмента рабочего образа шаг смещения по y, x следует выбирать равным единице, а размеры рабочего сегмента равными размерам эталонного. Операции при нормировке также рекомендуется проводить аналогично расчетам по эталонному образу.
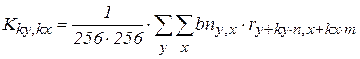 ;
;
где r рабочий движущийся сегмент.
Рабочий уровень доверия dr сложный параметр, задающий процент ошибок первого и второго рода, возникающих при распознавании. В лабораторной работе рекомендуется задать этот параметр вручную, как процент от dm. Массив указателей Kd на обнаруженные символы можно вычислить по формуле:
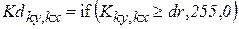 .
.
На рис. 3.15 приведены результаты поиска символа c на изображении. Малая величина рабочего уровня доверия(dr<560, dm=1000) привела к тому, что ошибочно включены в перечень найденных символов две буквы е и буква о (рис. 3.10 а, там же показана маска на текст для уровня dr равного 520). Правильно выбранный уровень доверия (569<dr<598) указал на все буквы с в тексте (рис. 3.10 б, там же изображение текста). При уровне dr>599 программа не обнаруживает все искомые буквы (рис. 3.10 в).
Автоматическое определение оптимальной величины dr и уточнение описаний признаков эталонных образов, осуществляется в процессе обучения и функционирования системы по информации об ошибках.
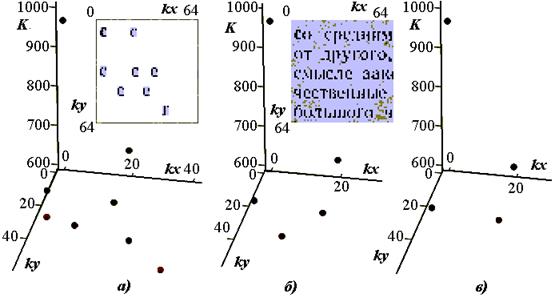
Рис. 3.15. Отобранные символы при различных значениях уровня доверия
а) – dr = 520 б) – dr = 570-598 с) – dr = 600
Следующим этапом уточнения выводов распознавания является восприятие смыслового содержания сообщений, как это обычно делает человек, но эти задачи выходят за рамки данной работы.
Дата добавления: 2015-03-23; просмотров: 1323;