Кодирование информации, помехоустойчивое кодирование, коды Хэмминга и Хаффмана
Код — это набор условных обозначений (или сигналов) для записи (или передачи) некоторых заранее определенных понятий.
Кодирование информации – это процесс формирования определенного представления информации. В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
Обычно каждый образ при кодировании (иногда говорят — шифровке) представлен отдельным знаком.
Знак - это элемент конечного множества отличных друг от друга элементов.
В более узком смысле под термином "кодирование" часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
Как правило, все числа в компьютере представляются с помощью нулей и единиц (а не десяти цифр, как это привычно для людей). Иными словами, компьютеры обычно работают в двоичной системе счисления, поскольку при этом устройства для их обработки получаются значительно более простыми. Ввод чисел в компьютер и вывод их для чтения человеком может осуществляться в привычной десятичной форме, а все необходимые преобразования выполняют программы, работающие на компьютере.
Одна и та же информация может быть представлена (закодирована) в нескольких формах. C появлением компьютеров возникла необходимость кодирования всех видов информации, с которыми имеет дело и отдельный человек, и человечество в целом. Но решать задачу кодирования информации человечество начало задолго до появления компьютеров. Грандиозные достижения человечества - письменность и арифметика - есть не что иное, как система кодирования речи и числовой информации. Информация никогда не появляется в чистом виде, она всегда как-то представлена, как-то закодирована.
Двоичное кодирование.
Один из распространенных способов представления информации. В вычислительных машинах, в роботах и станках с числовым программным управлением, как правило, вся информация, с которой имеет дело устройство, кодируется в виде слов двоичного алфавита только двумя знаками 0 и 1 (то есть все информация в памяти компьютера хранится и обрабатывается в виде последовательности нулей и единиц).
Избыточное кодирование - вид кодирования, использующий избыточное количество информации с целью последующего контроля целостности данных при записи/воспроизведении информации или при её передаче по линиям связи.
Кодирование Хэмминга
Кодирование Хэмминга предусматривает как возможность обнаружения ошибки, так и возможность её исправления. Рассмотрим простой пример - закодируем четыре бита: a,b,c,d.Полученный код будет иметь длину 8 бит и выглядеть следующим образом: 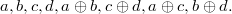 Рассмотрим табличную визуализацию кода:
Рассмотрим табличную визуализацию кода:

| 
| 
|

| 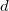
| 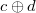
|
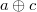
| 
|
Как видно из таблицы, даже если один из битов 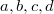 передался с ошибкой, содержащие его
передался с ошибкой, содержащие его 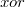 -суммы не сойдутся. Итого, зная строку и столбец в проиллюстрированной таблице можно точно исправить ошибочный бит.
-суммы не сойдутся. Итого, зная строку и столбец в проиллюстрированной таблице можно точно исправить ошибочный бит.
По аналогичному принципу можно закодировать любое число бит. Пусть мы имеем исходную строку длиной в 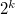 бит. Для получения её кода добавим к ней
бит. Для получения её кода добавим к ней  пар бит по следующему принципу:
пар бит по следующему принципу:
§ Первая пара: сумма четных бит и сумма нечетных бит
§ Вторая пара: сумма тех бит, в чьем номере второй бит с конца ноль и сумма тех бит, в чьем номере второй бит с конца единица
...
§ -тая пара: сумма тех бит, в чьем номере -тый бит с конца ноль и сумма тех бит, в чьем номере -тый бит с конца единица.
Легко понять, что если в одном бите из строки допущена ошибка, то с помощью дописанных пар бит можно точно определить, какой именно бит ошибочный. Это объясняется тем, что каждая пара определяет один бит номера ошибочного бита в строке. Всего пар , следовательно мы имеем бит номера ошибочного бита, что вполне достаточно: общее число бит строки не превосходит .
Теперь заметим, что в случае наличия ошибки в исходной строке, ровно один бит в каждой паре будет равен единице. Тогда можно оставить только один бит из пары. Однако этого будет недостаточно, поскольку если только один добавленный бит не соответствует строке, то нельзя понять, ошибка в нём или в строке. На этот случай можно добавить ещё один контрольный бит - всех битов строки.
Итого, увеличивая код длиной 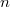 на
на  , можно обнаружить и исправить одну ошибку.
, можно обнаружить и исправить одну ошибку.
Корректирующиекоды, помехоустойчивые коды, коды обнаружения и исправления ошибки, коды, позволяющие по имеющейся в кодовой комбинации избыточности обнаруживать и исправлять определённые ошибки, появление которых приводит к образованию ошибочных или запрещенных комбинаций. Применяются при передаче и обработке информации в вычислительной технике, телеграфии, телемеханике и технике связи, где возможны искажения сигнала в результате действия различного рода помех. Кодовые слова К. к. содержат информационные и проверочные разряды (символы). В процессе кодирования при передаче информации из информационных разрядов в соответствии с определёнными для каждого К. к. правилами формируются дополнительные символы — проверочные разряды. При декодировании из принятых кодовых слов по тем же правилам вновь формируют проверочные разряды и сравнивают их с принятыми; если они не совпадают, значит при передаче произошла ошибка. Существуют коды, обнаруживающие факт искажения сообщения, и коды, исправляющие ошибки, т. е. такие, с помощью которых можно восстановить первичную информацию.
Алгоритм Хаффмана — адаптивный простой алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью. Был разработан в 1952 году аспирантом Массачусетского технологического института Дэвидом Хаффманом при написании им курсовой работы. В настоящее время используется во многих программах сжатия данных.
В отличие от алгоритма Шеннона — Фано, алгоритм Хаффмана остаётся всегда оптимальным и для вторичных алфавитов m2 с более чем двумя символами.
Этот метод кодирования состоит из двух основных этапов:
· Построение оптимального кодового дерева.
· Построение отображения код-символ на основе построенного дерева.
·
Тема 3
Дата добавления: 2014-12-06; просмотров: 2997;