Использование безразмерной величины . 4 страница
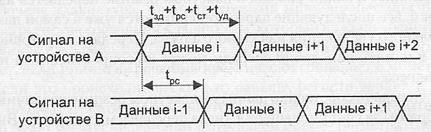
Рис. 4.20. Конвейеризация транзакций чтения
Данные на шине должны оставаться стабильными в течение времени tСТ + tУД. Только после этого возможна смена элемента данных. Максимальная скорость передачи при конвейеризации определяется выражением 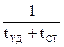 .
.
Протокол с расщеплением транзакций
Для увеличения эффективной полосы пропускания шины во многих современных шинах используется протокол с расщеплением транзакций (split transaction), известный также как протокол соединения/разъединения (connect/disconnect)или протокол с коммутацией пакетов (packet-switched). Этот протокол обычно обеспечивает преимущество на транзакциях чтения.
В классическом варианте любая транзакция на шине неразрывна, то есть новая транзакция может начаться только после завершения предыдущей, причем в течение всего периода транзакции шина остается занятой. Протокол с расщеплением транзакций допускает совмещение во времени сразу нескольких транзакций.
В шине с расщеплением транзакций линии адреса и данных обязаны быть независимыми. Каждая транзакция чтения разделяется на две части: адресную транзакцию и транзакцию данных. Считывание данных из памяти начинается с адресной транзакции: выставления ведущим на адресную шину адреса ячейки. С приходом адреса память приступает к относительно длительному процессу поиска и извлечения затребованных данных. По завершении чтения память становится ведущим устройством, запрашивает доступ к шине и направляет считанные данные по шине данных. Фактически от момента поступления запроса до момента формирования отклика шина остается незанятой и может быть востребована для выполнения других транзакций. В этом и состоит главная идея протокола расщепления транзакций.
Таким образом, на шине с расщеплением транзакции имеют место поток запросов и поток откликов. Часто в системах с расщеплением транзакций контроллер памяти проектируется так, чтобы обеспечить буферизацию множественных запросов.
Случай, когда затребованные данные возвращаются в той же последовательности, в которой поступали запросы, в сущности, представляет собой рассмотренную выше конвейеризацию. Шина с расщеплением транзакций зачастую может вариант, при котором ответы на запросы поступают в произвольной последовательности (рис. 4.21). Чтобы не спутать, какому из запросов соответствует информация на шине данных, ее необходимо снабдить признаком (тегом).

Рис. 4.21. Расщепление транзакций
Хота протокол с расщеплением транзакций и позволяет более эффективно использовать полосу пропускания шины по сравнению с протоколами, удерживающими шину в течение всей транзакции, он обычно вносит дополнительную задержку из-за необходимости получать два подтверждения — при запросе и при отклике. Кроме того, реализация протокола связана с дополнительными затратами, так как требует, чтобы транзакции были тегированы и отслеживались каждым устройством.
Для любой шины с расщеплением транзакций существует предельное значение числа одновременно обслуживаемых запросов.
Увеличение полосы пропускания шины
Среди приемов, способствующих расширению полосы пропускания шины, основными, пожалуй, можно считать следующие:
§ отказ от мультиплексирования шин адреса и данных;
§ увеличение ширины шины данных;
§ повышение тактовой частоты шины;
§ использование блочных транзакций.
Замена мультиплексируемой шины адреса/данных и переход к выделенным шинам адреса и данных делают возможной одновременную пересылку как адреса, так и данных, то есть позволяют реализовать более эффективные варианты транзакций. Такое решение, однако, является более дорогостоящим из-за необходимости иметь большее число сигнальных линий.
Полоса пропускания шины по своему определению непосредственно зависит от количества параллельно пересылаемой информации — практически прямо пропорциональна ширине шины данных. Несмотря на то что данный способ требует увеличения числа сигнальных линий, многие разработчики ВМ используют в своих машинах достаточно широкие шины данных. Например, в рабочей станции SPARCstation 20 ширина шины составляет 128 бит.
Наращивание тактовой частоты — еще один очевидный способ увеличения полосы пропускания, и проектировщики широко им пользуются.
О том, как на полосу пропускания шины влияют пакетные или блочные транзакции, было сказано выше. Данный способ требует некоторого усложнения аппаратуры, но одновременно позволяет сократить время обслуживания запроса.
Ускорение транзакций
Для сокращения времени транзакций проектировщики обычно прибегают к следующим приемам:
§ арбитражу с перекрытием;
§ арбитражу с удержанием шины;
§ расщеплению транзакций.
Сущность расщепления транзакций была рассмотрена ранее. Кратко поясним остальные два метода.
Арбитраж с перекрытием (overlapped arbitration) заключается в том, что одновременно с выполнением текущей транзакции производится арбитраж следующей транзакции.
При арбитраже с удержанием шины (bus parking) ведущий может удерживать шину и выполнять множество транзакций, пока отсутствуют запросы от других потенциальных ведущих.
В современных шинах обычно сочетаются все вышеперечисленные ускорения транзакций.
Повышение эффективности шин с множеством ведущих
Любая система шин характеризуется пределом пропускной способности, зависящим от их ширины, скорости и протокола. Имеются также издержки, такие как арбитраж, если только он не проводится параллельно с выполнением предшествующей транзакции. Даже простой микропроцессор способен практически монополизировать производительность объединительной шины при выборке инструкций и данных, но без блочных пересылок.
При проектировании мультипроцессорных систем целесообразно рассматривать системную шину как коммуникационный тракт между разными процессорами и нескольким контроллерами ввода/вывода и снабдить каждый процессор локальной памятью для команд и большей части данных. Это существенно снижает нагрузку на системную шину. Если процессоры используют шину в первую очередь для ввода/вывода и пересылки сообщений, большая часть трафика может быть реализована в виде блочных пересылок, что ведет практически к удвоению пропускной способности. Однако, в зависимости от числа процессоров и природы приложения, шина может стать и «узким местом». Фактически, если шина в течение значительной части времени не свободна, процессоры могут значительную долю времени провести в состоянии ожидания. Система с пересылкой сообщений начинает функционировать скорее как сеть, чем как простая шина ввода/вывода.
Одно из решений проблемы пропускной способности — увеличение количества шин с несколькими процессорами на каждой. Этот подход применен в шине Fastbus, где общее адресное пространство совместно используется нескольким отдельными шинами, называемыми сегментами. Сегменты функционируют независимо, но автоматически объединяются нужным образом, если ведущий из одного сегмента обращается к ведомому из другого сегмента. Это автоматическое объединение выражается во вмешательстве в трафик всех промежуточных сегментов, поэтому, чтобы не возникало заторов, применяться оно должно осторожно. Разумное использование узлов с промежуточным хранением совместно с сетевым протоколом передачи сообщений могут еще более сократить перегрузку путем сглаживания нагрузки, разрешая одновременное объединение как двух, так и нескольких сегментов.
Надежность и отказоустойчивость
Надежность и отказоустойчивость — важнейшие аспекты проектирования шин. Основные надежды здесь обычно возлагают на корректирующие коды, которые позволяют обнаружить отказ одиночного элемента или шумовой выброс и автоматически парировать ошибку. Подобный подход, широко практикуемый в системах памяти, применительно к шинам порождает специфические проблемы.
В шинах отдельные функциональные группы сигналов (сигналы адреса, данных, управления, состояния и арбитража) предполагают независимые контроль и коррекцию. При наличии множества небольших групп сигналов метод корректирующих кодов становится малоэффективным из-за необходимости включения в шину большого числа контрольных линий. Кроме того, в шинах весьма вероятно одновременное возникновение ошибок сразу в нескольких сигналах. Для учета такой ситуации необходимо увеличивать разрядность корректирующего кода, то есть вводить в шину дополнительные сигнальные линии. Достаточно неясным остается вопрос защиты одиночных сигналов, в частности сигналов тактирования и синхронизации.
Вычисление корректирующих кодов и коррекция ошибок требуют дополнительного времени, что замедляет шину.
Усложнение аппаратуры, обусловленное использованием корректирующих кодов, ведет к снижению общей надежности шины, в результате чего суммарный выигрыш может оказаться меньше ожидаемого. В силу приведенных соображений становится ясным, почему проектировщики постоянно ищут альтернативные способы обеспечения надежности и отказоустойчивости шин.
Достаточно хорошие результаты дают так называемые «высокоуровневые» подходы. Здесь вместо отслеживания каждого цикла шины производятся контроль и коррекция более крупных единиц, например целых блоков данных или законченной программной операции.
При наличии в системе избыточных процессоров и шин возможен перекрестный контроль, причем программное обеспечение может производить изменения в конфигурации системы и предупреждать оператора о необходимости замены определенных блоков. Даже если шина имеет встроенные средства коррекции ошибок, желательно дополнять их некоторым дополнительным уровнем «разумности» для предотвращения такой постепенной деградации системы, компенсировать которую имеющийся механизм коррекции будет уже не в состоянии.
При разработке аппаратуры необходимо обязательно учитывать определенные требования, связанные с обеспечением отказоустойчивости. Так, если обнаружена ошибка, то для ее коррекции должна быть предусмотрена возможность повторной передачи данных. Это предполагает, что оригинальная передача не должна приводить к необратимым побочным эффектам. Например, если операция чтения с периферийного устройства вызывает стирание исходных данных или сбрасывает флаги состояния, успешное повторное чтение становится невозможным. Другой пример: работа с буферной памятью типа FIFO (First In First Out), работающей по принципу «первым прибыл, первым обслужен», где ошибочные данные внутри очереди недоступны и поэтому не могут быть откорректированы.
Чтобы учесть подобные ситуации, при разработке адресуемой памяти необходимо предусмотреть буферы, а очистка ячеек и сброс флагов должны быть не побочными эффектами, а выполняться только явно с помощью определенных команд. Память типа FIFO может быть снабжена адресуемыми буферами, предназначенными для хранения данных вплоть до завершения передачи.
Стандартизация шин
Стандартизация шин позволяет разработчикам различных устройств вычислительных машин работать независимо, а пользователям — самостоятельно сформировать нужную конфигурацию ВМ. Появление стандартов зависит от разных обстоятельств. Часто стандарты разрабатываются специализированными организациями. Так, общепризнанными авторитетами в области стандартизации являются IEEE (Institute of Electrical and Electronics Engineers) - Институт инженеров по электротехнике и электронике) и ANSI (AmericanNational Standards Institute) - Национальный институт стандартизации США. Многие стандарты становятся итогом кооперации усилий производителей оборудования для вычислительных машин. Иногда в силу популярности конкретных машин реализованные в них решения становятся де-факто, однако успех таких стандартов во многом определяется их принятием и утверждением в IEEE и ANSI.
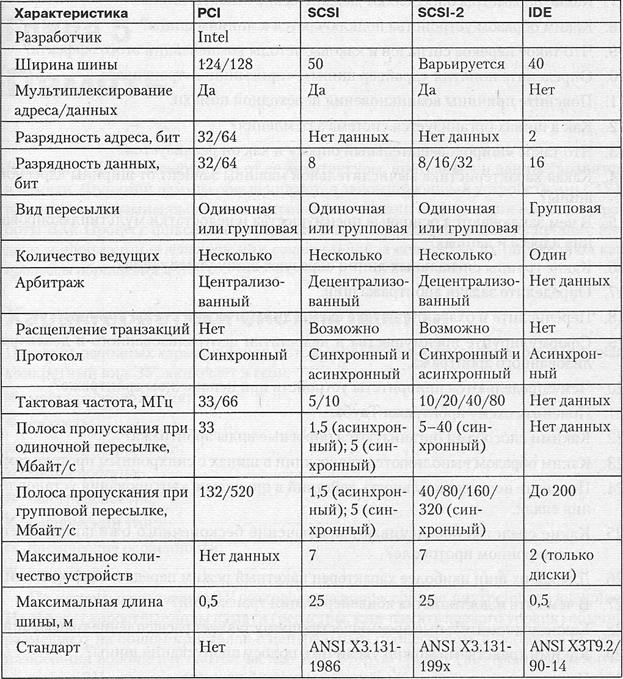
В табл. 4.2-4.5 приведены основные характеристики некоторых распространенный шин, как стандартных, так и претендующих на роль таковых.
Таблица 4.2. Стандартные системные шины общего применения

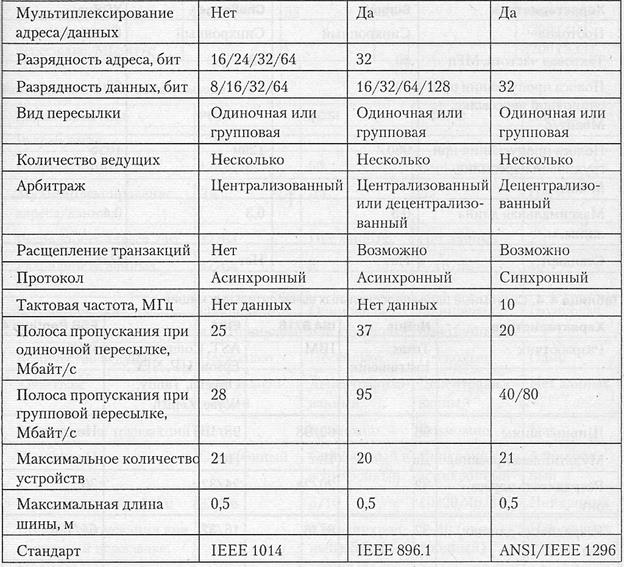
Таблица 4.4. Системные шины высокопроизводительных серверов
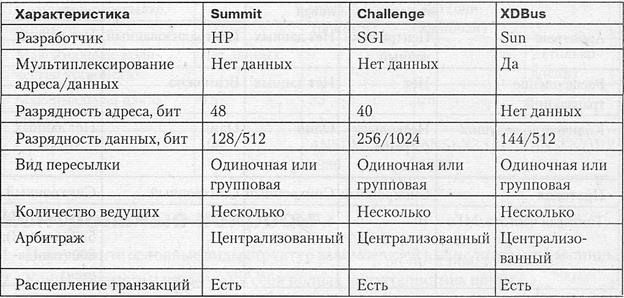
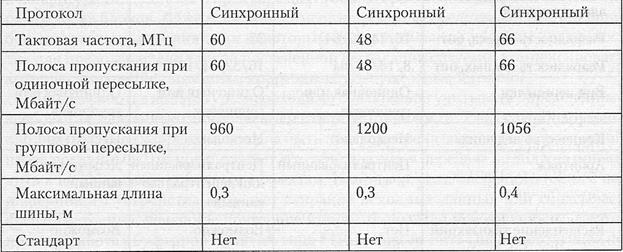
Таблица 4.4. Системные шины персональных вычислительных машин
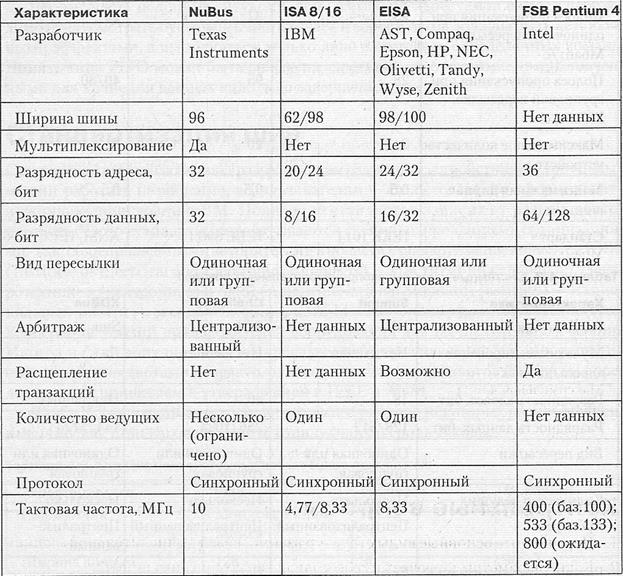

Таблица 4.5.Шины ввода/вывода
Контрольные вопросы
1. Перечислите основные виды структур взаимосвязей вычислительной машины.
2. Какие параметры включает в себя полная характеристика шины?
3. Что такое транзакция, из каких этапов она состоит?
4. В чем заключается основное различие между ведущими и ведомыми устройствами?
5. Что такое широковещательный режим записи?
6. Какие шины в составе ВМ образуют иерархию шин?
7. Какие параметры определяют механические аспекты шины?
8. Каким образом устройства подключаются к линиям шины?
9. Что такое перекос сигналов и каковы методы компенсации этого эффекта?
10. Определите понятия «драйвер шины», «приемник», «трансивер».
11. Поясните причины возникновения переходной помехи.
12. Как в шинах организуется система заземления?
13. Что такое «широковещательный опрос» и как он реализуется?
14. Какая характеристика вычислительной машины зависит от ширины адресной шины?
15. В чем заключаются основные преимущества и недостатки мультиплексирования адреса и данных?
16. Какие группы сигнальных линий образуют шину управления?
17. Определите задачи арбитража шин.
18. Перечислите и охарактеризуйте схемы динамической смены приоритетов.
19. Сформулируйте преимущества и недостатки централизованного и децентрализованного арбитража.
20. Чем определяются приоритеты устройств при цепочечном арбитраже?
21. Поясните схему арбитража Тауба.
22. Какими способами организуются опросные виды арбитража?
23. Каким образом выполняются транзакции в шинах с синхронным протоколом?
24. Поясните последовательность действий в процедуре квитирования установления связи.
25. Какие средства обеспечивают исключение бесконечного ожидания ответа в асинхронном протоколе?
26. Для каких шин наиболее характерен пакетный режим передачи информации?
27. В чем суть и достоинства конвейеризации транзакций?
28. Какие дополнительные преимущества предоставляет расщепление транзакций?
29. Какими средствами можно увеличить полосу пропускания шины?
30. Перечислите способы ускорения транзакций на шине.
31. Какие приемы обеспечивают повышение эффективности шин с множеством ведущих?
32. Охарактеризуйте средства повышения надежности шин.
Глава 5
Память
В любой ВМ, вне зависимости от ее архитектуры, программы и данные хранятся в памяти. Функции памяти обеспечиваются запоминающими устройствами (ЗУ), предназначенными для фиксации, хранения и выдачи информации в процессе работы ВМ. Процесс фиксации информации в ЗУ называется записью, процесс выдачи информации — чтением или считыванием, а совместно их определяют как процессы обращения к ЗУ.
Характеристики систем памяти
Перечень основных характеристик, которые необходимо учитывать, рассматривая конкретный вид ЗУ, включает в себя:
§ место расположения;
§ емкость;
§ единицу пересылки;
§ метод доступа;
§ быстродействие;
§ физический тип;
§ физические особенности;
§ стоимость.
По месту расположения ЗУ разделяют на процессорные, внутренние и внешние. Наиболее скоростные виды памяти (регистры, кэш-память первого уровня) обычно размещают на общем кристалле с центральным процессором, а регистры общего назначения вообще считаются частью ЦП. Вторую группу (внутреннюю память) образуют ЗУ, расположенные на системной плате. К внутренней памяти относят основную память, а также кэш-память второго и последующих уровней (кэш-память второго уровня может также размещаться на кристалле процессора). Медленные ЗУ большой емкости (магнитные и оптические диски, магнитные ленты) называют внешней памятью, поскольку к ядру ВМ они подключаются аналогично устройствам ввода/вывода.
Емкость ЗУ характеризуют числом битов либо байтов, которое может храниться в запоминающем устройстве. На практике применяются более крупные единицы, а для их обозначения к словам «бит» или «байт» добавляют приставки: кило, мега, гига, тера, пета, экза (kilo, mega, giga, tera, peta, exa). Стандартно эти приставки означают умножение основной единицы измерений на 103, 106, 109, 1012, 1015 и 1018 соответственно. В вычислительной технике, ориентированной на двоичную систему счисления, они соответствуют значениям достаточно близким к стандартным, но представляющим собой целую степень числа 2, то есть 210, 220, 230, 240, 250, 260. Во избежание разночтений, в последнее время ведущие международные организации по стандартизации, например IEEE (Institute of Electrical and Electronics Engineers), предлагают ввести новые обозначения, добавив к основной приставке слово binary (бинарный): kilobinary, megabinary, gigabinary, terabinary, petabinary, exabinary. В результате вместо термина «килобайт» предлагается термин байт», вместо «мегабайт» – «мебибайт» и т. д. Для обозначения новых единиц предлагаются сокращения: Ki, Mi, Gi, Ti, Pi и Ei [133].
Важной характеристикой ЗУ является единица пересылки. Для основной памяти (ОП) единица пересылки определяется шириной шины данных, то есть количеством битов, передаваемых по линиям шины параллельно. Обычно единица пересылки равна длине слова, но не обязательно. Применительно к внешней памяти данные часто передаются единицами, превышающими размер слова, и такие единицы называются блоками.
При оценке быстродействия необходимо учитывать применяемый в данном типе ЗУ метод доступа к данным. Различают четыре основных метода доступа:
§ Последовательный доступ. ЗУ с последовательным доступом ориентировано на хранение информации в виде последовательности блоков данных, называемых записями. Для доступа к нужному элементу (слову или байту) необходимо прочитать все предшествующие ему данные. Время доступа зависит от положения требуемой записи в последовательности записей на носителе информации и позиции элемента внутри данной записи. Примером может служить ЗУ на магнитной ленте.
§ Прямой доступ. Каждая запись имеет уникальный адрес, отражающий ее физическое размещение на носителе информации. Обращение осуществляется как адресный доступ к началу записи, с последующим последовательным доступом к определенной единице информации внутри записи. В результате время доступа к определенной позиции является величиной переменной. Такой режим характерен для магнитных дисков.
§ Произвольный доступ. Каждая ячейка памяти имеет уникальный физический адрес. Обращение к любой ячейке занимает одно и то же время и может производиться в произвольной очередности. Примером могут служить запоминающие устройства основной памяти.
§ Ассоциативный доступ. Этот вид доступа позволяет выполнять поиск ячеек, содержащих такую информацию, в которой значение отдельных битов совпадает с состоянием одноименных битов в заданном образце. Сравнение осуществляется параллельно для всех ячеек памяти, независимо от ее емкости. По ассоциативному принципу построены некоторые блоки кэш-памяти.
Быстродействие ЗУ является одним из важнейших его показателей. Для количественной оценки быстродействия обычно используют три параметра:
§ Время доступа (ТД). Для памяти с произвольным доступом оно соответствует интервалу времени от момента поступления адреса до момента, когда данные заносятся в память или становятся доступными. В ЗУ с подвижным носителем информации — это время, затрачиваемое на установку головки записи/считывания (или носителя) в нужную позицию.
§ Длительность цикла памяти или период обращения (ТЦ). Понятие применяется к памяти с произвольным доступом, для которой оно означает минимальное время между двумя последовательными обращениями к памяти. Период обращения включает в себя время доступа плюс некоторое дополнительное время. Дополнительное время может требоваться для затухания сигналов на линиях, а в некоторых типах ЗУ, где считывание информации приводит к ее разрушению, — для восстановления считанной информации.
§ Скорость передачи. Это скорость, с которой данные могут передаваться в память или из нее. Для памяти с произвольным доступом она равна 1/ТЦ. Для других видов памяти скорость передачи определяется соотношением:
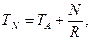
где TN — среднее время считывания или записи N битов; ТА — среднее время доступа; R — скорость пересылки в битах в секунду.
Говоря о физическом типе запоминающего устройства, необходимо упомянуть три наиболее распространенных технологии ЗУ — это полупроводниковая память, память с магнитным носителем информации, используемая в магнитных дисках и лентах, и память с оптическим носителем — оптические диски.
В зависимости от примененной технологии следует учитывать и ряд физических особенностей ЗУ, например энергозависимость. В энергозависимой памяти информация может быть искажена или потеряна при отключении источника питания. В энергонезависимых ЗУ записанная информация сохраняется и при отключении питающего напряжения. Магнитная и оптическая память — энергонезависимы. Полупроводниковая память может быть как энергозависимой, так и нет, в зависимости от ее типа. Помимо энергозависимости нужно учитывать, приводит ли считывание информации к ее разрушению.
Стоимость ЗУ принято оценивать отношением общей стоимости ЗУ к его емкости в битах, то есть стоимостью хранения одного бита информации.
Иерархия запоминающих устройств
Память часто называют «узким местом» фон-неймановских ВМ из-за ее серьезного отставания по быстродействию от процессоров, причем разрыв этот неуклонно увеличивается. Так, если производительность процессоров ежегодно возрастает вдвое примерно каждые 1,5 года, то для микросхем памяти прирост быстродействия не превышает 9% в год (удвоение за 10 лет), что выражается в увеличении разрыва в быстродействии между процессором и памятью приблизительно на 50% в год.
Если проанализировать используемые в настоящее время типы ЗУ, выявляется следующая закономерность:
§ чем меньше время доступа, тем выше стоимость хранения бита;
§ чем больше емкость, тем ниже стоимость хранения бита, но больше время доступа.
При создании системы памяти постоянно приходится решать задачу обеспечения требуемой емкости и высокого быстродействия за приемлемую цену. Наиболее распространенным подходом здесь является построение системы памяти ВМ по иерархическому принципу. Иерархическая память состоит из ЗУ различных типов (рис. 5.1), которые, в зависимости от характеристик, относят к определенному уровню иерархии. Более высокий уровень меньше по емкости, быстрее и имеет большую стоимость в пересчете на бит, чем более низкий уровень. Уровни иерархии взаимосвязаны: все данные на одном уровне могут быть также найдены на более низком уровне, и все данные на этом более низком уровне могут быть найдены на следующем нижележащем уровне и т. д.
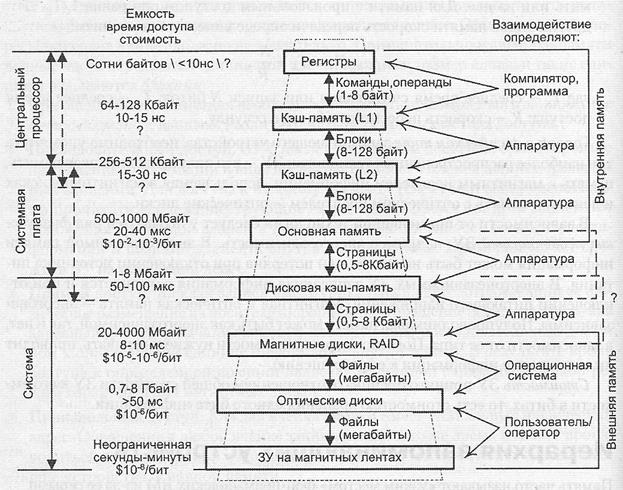
Рис. 5.1. Иерархия запоминающих устройств
Четыре верхних уровня иерархии образуют внутреннюю память ВМ, а все нижние уровни — это внешняя или вторичная память.
По мере движения вниз по иерархической структуре:
1. Уменьшается соотношение «стоимость/бит».
2. Возрастает емкость.
3. Растет время доступа.
4. Уменьшается частота обращения к памяти со стороны центрального процессора.
Если память организована в соответствии с пунктами 1-3, а характер размещения в ней данных и команд удовлетворяет пункту 4, иерархическая организация ведет к уменьшению общей стоимости при заданном уровне производительности.
Справедливость этого утверждения вытекает из принципа локальности по обращению [87]. Если рассмотреть процесс выполнения большинства программ, то можно заметить, что с очень высокой вероятностью адрес очередной команды программы либо следует непосредственно за адресом, по которому была считана текущая команда, либо расположен вблизи него. Такое расположение адресов называется пространственной локальностью программы. Обрабатываемые данные, как правило, структурированы, и такие структуры обычно хранятся в последовательных ячейках памяти. Данная особенность программ называется пространственной локальностью данных. Кроме того, программы содержат множество небольших циклов и подпрограмм. Это означает, что небольшие наборы команд могут многократно повторяться в течение некоторого интервала времени, то есть имеет место временная локальность. Все три вида локальности объединяет понятие локальность по обращению. Принцип локальности часто облекают в численную форму и представляют в виде так называемого правила «90/10»: 90% времени работы программы связано с доступом к 10% адресного пространства этой программы.
Из свойства локальности вытекает, что программу разумно представить в виде последовательно обрабатываемых фрагментов — компактных групп команд и данных. Помещая такие фрагменты в более быструю память, можно существенно снизить общие задержки на обращение, поскольку команды и данные, будучи один раз переданы из медленного ЗУ в быстрое, затем могут использоваться многократно, и среднее время доступа к ним в этом случае определяется уже более быстрым ЗУ. Это позволяет хранить большие программы и массивы данных на медленных, емких, но дешевых ЗУ, а в процессе обработки активно использовать сравнительно небольшую быструю память, увеличение емкости которой сопряжено с высокими затратами.
На каждом уровне иерархии информация разбивается на блоки, выступающие в качестве наименьшей информационной единицы, пересылаемой между двумя соседними уровнями иерархии. Размер блоков может быть фиксированным либо переменным. При фиксированном размере блока емкость памяти обычно кратна его размеру. Размер блоков на каждом уровне иерархии чаще всего различен и увеличивается от верхних уровней к нижним.
При доступе к командам и данным, например, для их считывания, сначала производится поиск в памяти верхнего уровня. Факт обнаружения нужной информации называют попаданием (hit), в противном случае говорят о промахе (miss). При промахе производится поиск в ЗУ следующего более низкого уровня, где также возможны попадание или промах. После обнаружении необходимой информации выполняется последовательная пересылка блока, содержащего искомую информацию, с нижних уровней на верхние. Следует отметить, что независимо от числа уровней иерархии пересылка информации может осуществляться только между двумя соседними уровнями.
При оценке эффективности подобной организации памяти обычно используют следующие характеристики:
§ коэффициент попаданий (hit rate) – отношение числа обращений к памяти, при которых произошло попадание, к общему числу обращений к ЗУ данного уровня иерархии;
§ коэффициент промахов (miss rate) – отношение числа обращений к памяти, при которых имел место промах, к общему числу обращений к ЗУ данного уровня иерархии;
§ время обращения при попадании (hit time) – время, необходимое для поиска нужной информации в памяти верхнего уровня (включая выяснение, является ли обращение попаданием), плюс время на фактическое считывание данных;
§ потери на промах (miss penalty) – время, требуемое для замены блока в памяти более высокого уровня на блок с нужными данными, расположенный в ЗУ следующего (более низкого) уровня. Потери на промах включают в себя: время доступа (access time) – время обращения к первому слову блока при промахе и время пересылки (transfer time) – дополнительное время для пересылки оставшихся слов блока. Время доступа обусловлено задержкой памяти более низкого уровня, в то время как время пересылки связано с полосой пропускания канала между ЗУ двух смежных уровней.
Описание некоторого уровня иерархии ЗУ предполагает конкретизацию четырех моментов:
§ размещения блока – допустимого места расположения блока на примыкающем сверху уровне иерархии;
Дата добавления: 2019-04-03; просмотров: 547;