Первичные коды и эффективное кодирование
Первичные коды – специальный класс кодов, которые учитывают исключение избыточности информации из передаваемых сообщений с целью увеличения скорости передачи информации.
Статистическое кодирование информации (кодирование источника сообщений или сжатие информации) связано с преобразованием выходной информации дискретного источника в последовательность букв заданного кодового алфавита. Естественно, что правила кодирования следует выбирать таким образом, чтобы с высокой вероятностью последовательность на выходе источника могла быть восстановлена по закодированной последовательности, а также, чтобы число букв кода, требуемых на одну букву источника, было по возможности меньшим. В теории информации показывается, что минимальное число двоичных букв кода на одну букву источника, требуемых для представления выхода источника, задается энтропией источника.
Энтропия Н(А) источника сообщений А определяется как математическое ожидание количества информации:
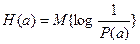 , (1)
, (1)
где Р(а) – вероятность того, что источник превышает сообщение “а” из ансамбля А. Здесь математическое ожидание обозначает усреднение по всему ансамблю сообщений. При этом должны учитываться все вероятностные связи между различными сообщениями.
Чем больше энтропия источника, тем больше степень неожиданности передаваемых им сообщений в среднем, т.е. тем более неопределенным является ожидаемое сообщение. Поэтому энтропию часто называют мерой неопределенности сообщения. Можно характеризовать энтропию так же, как меру разнообразия выдаваемых источником сообщений. Если ансамбль содержит К различных сообщений, то Н(а)≤logK, причем равенство имеет место только тогда, когда все сообщения передаются равновероятно и независимо. Число К называется объемом алфавита источника.
Для двоичного источника, когда К=2, энтропия максимальна при Р(а1)=Р(а2) 0,5 и равна 1оg 2=1 бит. Энтропия источника зависимых сообщений всегда меньше энтропии источника независимых сообщений при том же объеме алфавита и тех же безусловных вероятностях сообщений. Для источника с объемом алфавита К=32, когда буквы выбираются равновероятно и независимо друг от друга, энтропия источника Н(А)=logК=5бит. Таким источником, например, является пишущая машинка русского алфавита при хаотическом порядке нажатии клавиш. Если же буквы передаются не хаотически, а составляют связный русский текст, то они оказываются неравновероятными (буква А передается чаще, чем буква Ф, и т.п.) и зависимыми (после гласных не может появиться знак "ь"; мала вероятность сочетания более трех гласных подряд и т.п.). Анализ ансамблей текстов русской художественной прозы показывает, что в этом случае энтропия менее 1,5 бит на букву. Еще меньше, около 1 бит на букву, энтропия ансамбля поэтических произведений, так как в них имеются дополнительные вероятностные связи, обусловленные ритмом и рифмами. Если же рассматривать в качестве источника сообщений поток телеграмм, то его энтропия обычно не превышает 0,8 бит на букву, поскольку тексты довольно однообразны.
Избыточность источника æ 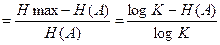 (2)
(2)
показывает, какая доля максимально возможной при этом алфавите энтропии не используется источником.
Среднее число кодовых символов на одну букву источника (средняя длина сообщения):
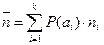 , где (4)
, где (4)
P(ai) – вероятность сообщения ai,
ni – количество двоичных символов в сообщении.
Коэффициент сжатия для первичного кода 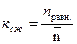 ,
,
где nравн.= log2К – количество двоичных символов в кодовом слове при равномерном кодировании сообщений (К – количество сообщений).
Префиксные коды
Однозначность декодирования можно обеспечить, не вводя разделительного символа, если строить код так, чтобы он удовлетворял условию, известному под названием "свойство префикса". Оно заключается в том, что ни одна комбинация более кратного кода не должна совпадать с началом ("префиксом") другого кодового слова. Коды, удовлетворяющие этому условию, называют префиксными кодами. Эти коды обеспечивают однозначное декодирование принятых кодовых слов без введения дополнительной информации для их разделения, т. е. всякая последовательность кодовых символов должна быть единственным образом разделена на кодовые слова. Коды, в которых это требование выполнимо, называются однозначно декодируемыми, или кодами без запятой.
Если код префиксный, то, читая принятую последовательность подряд с начала до конца, можно установить, где кончается одно кодовое слово и начинается следующее. Например, если код префиксный и в последовательности встретился код 110, то, очевидно, в коде не должно содержаться слов (1), (11). Закодировано префиксным кодом с а1 = (00), а2 = (01), а3 = (101), а4 = (100). На рис. 1 представлен граф (кодовое дерево) префиксного кода с сообщением а1 = (0), а2 = (1), а3 = (11), а4 = (111). Из рис. 1 следует, что если свойство префикса не выполняется, то некоторые промежуточные вершины дерева могут соответствовать кодовым словам.
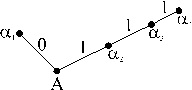
Рис. Кодовое слово непрефиксного кода
Дата добавления: 2019-04-03; просмотров: 1269;