Алгоритм на псевдокоде
Адаптивный код Хаффмана
Обозначим
w – окно
mas – массив вероятностей символов и кодовых слов
DO (i=1,…n) w[i]:=a[i] OD (заполняем окно символами алфавита)
DO (not EOF) (пока не конец входного файла)
DO (i=1,…,n) mas[i].p:=0 OD
DO (i=1,…,n) mas[w[i]].p:= mas[w[i]].p +1 OD (частоты встречи
символов в окне)
DO (i=1,…,n) mas[w[i]].p:= mas[w[i]].p/n OD (вероятности символов
в окне)
Сортировка(mas)
DO (i=1,…,n) (определяем количество
IF (mas[i].p=0) OD ненулевых вероятностей)
OD
Huffman(i,P) (строим код Хаффмана)
C:=Read( ) (читаем следующий символ из файла)
Write(mas[C].code) (код символа – в выходной файл)
DO (i=1,…,n-1) w[i]:= w[i+1] OD
w[n]:=C (включаем в окно текущий символ)
OD
6.2 Код «Стопка книг»
Этот метод был предложен Б. Я. Рябко в 1980 году. Название метод получил по аналогии со стопкой книг, лежащей на столе. Обычно сверху стопки находятся книги, которые недавно использовались, а внизу стопки – книги, которые использовались давно, и после каждого обращения к стопке использованная книга кладется сверху стопки.
До начала кодирования буквы исходного алфавита упорядочены произвольным образом и каждой позиции в стопке присвоено свое кодовое слово, причем первой позиции стопки соответствует самое короткое кодовое слово, а последней позиции - самое длинное кодовое слово. Очередной символ кодируется кодовым словом, соответствующим номеру его позиции в стопке, и переставляется на первую позицию в стопке.
Пример. Приведем описание кода на примере алфавита A={a1,a2,a3,a4}. Пусть кодируется сообщение а3а3а4а4а3…
· Символ а3находится в третьей позиции стопки, кодируется кодовым словом 110 и перемещается на первую позицию в стопке, при этом символы а1и а2 смещаются на одну позицию вниз.
· Следующий символ а3 уже находится в первой позиции стопки, кодируется кодовым словом 0 и стопка не изменяется.
· Символ а4 находится в последней позиции стопки, кодируется кодовым словом 111 и перемещается на первую позицию в стопке, при этом символы а1, а2, а3 смещаются на одну позицию вниз.
· Следующий символ а4 уже находится в первой позиции стопки, кодируется кодовым словом 0 и стопка не изменяется.
· Символ а3 находится во второй позиции стопки, кодируется кодовым словом 10 и перемещается на первую позицию в стопке, при этом символ а4 смещается на одну позицию вниз.
| № | Кодовое слово | Начальная «стопка» | Преобразования «стопки» | ||||
| а1 |  а3 а3
|   а3 а3
|  а4 а4
|   А4 А4
| а3 | ||
 а2 а2
| а1
|  а1 а1
| а3
| А3 | а4 | ||
| а3 |  а2 а2
|  а2 а2
|  а1 а1
|  А1 А1
| а1 | ||
 4 4
|  а4 а4
|  а4 а4
| а4 |  а2 а2
|  А2 А2
|  а2 а2
|
Рисунок 11 Кодирование методом «стопка книг»
Таким образом, закодированное сообщение имеет следующий вид:
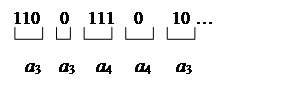
Рассмотренный метод сжимает сообщение за счет того, что часто встречающиеся символы будут находиться в верхних позициях «стопки книг» и кодироваться более короткими кодовыми словами. Эффективность метода особенно заметна при кодировании серий одинаковых символов. В этом случае все символы серии, начиная со второго, будут кодироваться самым коротким кодовым словом, соответствующим первой позиции «стопки книг».
При декодировании используется такая же «стопка книг», находящаяся первоначально в том же состоянии. Над «стопкой» проводятся такие же преобразования, что и при кодировании. Это гарантирует однозначное восстановление исходной последовательности.
Приведение описание данного алгоритма на псевдокоде.
Дата добавления: 2019-02-07; просмотров: 298;