Алгоритм на псевдокоде
Построение кода Гилберта-Мура
Обозначим
n – количество символов исходного алфавита
P – массив вероятностей символов
Q – массив для величин Qi
L – массив длин кодовых слов
C – матрица элементарных кодов
pr:=0
DO (i=1,…,n)
Q [i]:= pr+ P[i] /2
pr:=pr+ P[i]
L [i]:= - élog2P[i] ù +1 (использовать соотношение из п. 6.1)
OD
DO (i=1,…,n)
DO (j=1,…,L[i])
Q [i]:=Q [i] *2 (формирование кодового слова
C [i,j]:= ëQ [i]û в двоичном виде)
IF (Q [i] >1) Q [i]:=Q [i] - 1 FI
OD
OD
5. арифметический код
Идея арифметического кодирования была впервые предложена П. Элиасом. В арифметическом коде кодируемое сообщение разбивается на блоки постоянной длины, которые затем кодируются отдельно. При этом при увеличении длины блока средняя длина кодового слова стремится к энтропии, однако возрастает сложность реализации алгоритма и уменьшается скорость кодирования и декодирования. Таким образом, арифметическое кодирование позволяет получить произвольно малую избыточность при кодировании достаточно больших блоков входного сообщения.
Рассмотрим общую идею арифметического кодирования. Пусть дан источник, порождающий буквы из алфавита А={a1,a2,…,an} с вероятностями pi=P(ai), 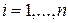 . Необходимо закодировать последовательность символов данного источника Х=х1х2х3х4.
. Необходимо закодировать последовательность символов данного источника Х=х1х2х3х4.
1) Вычислим кумулятивные вероятности Q0 ,Q1,…,Qn:
Q0=0
Q1=p1
Q2=p1+p2
Q3=p1+p2+p3
...
Qn=p1+p2+…+pn=1
2) Разобьем интервал [Q0,Qn) (т.е. интервал [0,1)) так, чтобы каждой букве исходного алфавита соответствовал свой интервал, равный ее вероятности (см. рис. 7):
a1[Q0,Q1)
a2 [Q1,Q2)
a3 [Q2,Q3)
a4[Q3,Q4)
...
an [Qn-1,Qn)
3) В процессе кодирования будем выбирать интервал, соответствующий текущей букве исходного сообщения, и снова разбивать его пропорционально вероятностям исходных букв алфавита. Постепенно происходит сужение интервала до тех пор, пока не будет закодирован последний символ кодируемого сообщения. Двоичное представление любой точки, расположенной внутри интервала, и будет кодом исходного сообщения.
На рисунке 7 показан этот процесс для кодирования последовательности а3а2а3…
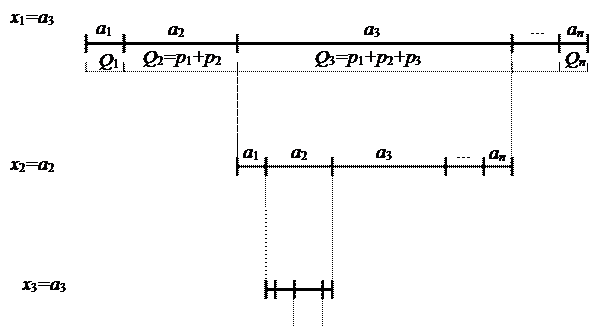 |
Рисунок 7 Схема арифметического кодирования
Для удобства вычислений введем следующие обозначения:
li - нижняя граница отрезка, соответствующего i-той букве исходного сообщения;
hi - верхняя граница этого отрезка;
ri - длина отрезка [li, hi), т.е. ri = hi - li.
Возьмем начальные значения этих величин
l0 = Q0=0, h0 = Qk=1, r0 = h0 - l0=1
и далее будем вычислять границы интервала, соответствующего кодируемой букве по формулам:
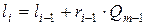 ,
, 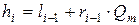 ,
,
где m - порядковый номер кодируемой буквы в алфавите источника, m=1,...,n.
Таким образом, окончательная длина интервала равна произведению вероятностей всех встретившихся символов, а начало интервала зависит от порядка расположения символов в кодируемой последовательности.
Для однозначного декодирования исходной последовательности достаточно взять 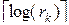 разрядов двоичной записи любой точки из интервала [li,hi), где rk - длина интервала после кодирования k символов источника.
разрядов двоичной записи любой точки из интервала [li,hi), где rk - длина интервала после кодирования k символов источника.
Пример. Рассмотрим кодирование бесконечной последовательности X=a3a2a3a1a4... в алфавите A={a1, a2, a3, a4} с помощью арифметического кода. Пусть вероятности букв исходного алфавита равны соответственно
p1 = 0.1, p2 = 0.4, p3 = 0.2, p4 = 0.3.
Вычислим кумулятивные вероятности Qi :
Q0 = 0,
Q1 =p1 = 0.1,
Q2 =p1+p2 = 0.5,
Q3 =p1+p2+p3 = 0.7,
Q4 =p1 +p2 +p3 + p4 = 1.
Получим границы интервала, соответствующего первому символу кодируемого сообщения a3:
l1 = l0 + r0·Q2 = 0 + 1·0.5 = 0.5,
h1 = l0 + r0·Q3 = 0 + 1·0.7 = 0.7,
r1 = h1 - l1 = 0.7 - 0.5 = 0.2.
Для второго символа кодируемого сообщения a2 границы интервала будут следующие:
l2 = l1 + r1·Q1 = 0.5 + 0.2·0.1 = 0.52,
h2 = l1 + r1·Q2 = 0.5 + 0.2·0.5 = 0.6,
r2 = h2 - l2 = 0.6 - 0.52 = 0.08и т.д.
В результате всех вычислений получаем следующую последовательность интервалов для сообщения a3a2a3a1a4
В начале [0.0, 1.0)
После пpосмотpа a3[0.5, 0.7)
После пpосмотpа a2 [0.52, 0.6)
После пpосмотpа a3 [0.56, 0.576)
После пpосмотpа a1[0.56, 0.5616)
После пpосмотpа a4[0.56112, 0.5616)
Кодом последовательности a3a2a3a1a4 будет двоичная запись любой точки из интервала [0.56112, 0.5616), например, 0.56112. Для однозначного декодирования возьмем élog2(r5)ù = élog2(0.00048)ù = 12 разрядов, получим 100011111010.
Таким образом, при арифметическом кодировании сообщение представляется вещественными числами в интервале [0,1). По мере кодирования сообщения отображающий его интервал уменьшается, а количество битов для представления интервала возрастает. Очередные символы сообщения сокращают величину интервала в зависимости от значений их вероятностей. Более вероятные символы делают это в меньшей степени, чем менее вероятные, и следовательно, добавляют меньше битов к результату.
Дата добавления: 2019-02-07; просмотров: 413;