вычисление ошибок оценки и доверительных интервалов.
Хотя линия регрессия, построенная по методу наименьших квадратов, и является хорошей аппроксимацией данных, в выборке существуют некоторые отклонения от этой линии. Чтобы оценить точность рассчитанных теоретических значений 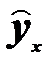 вычисляют стандартную ошибку оценки (как отношение остаточной вариации к числу степеней свободы).
вычисляют стандартную ошибку оценки (как отношение остаточной вариации к числу степеней свободы).
Чем меньше стандартная ошибка, тем выше степень согласия переменных в уравнении. При этом стандартная ошибка оценки будет оставаться одинаковой для любого значения независимой переменной.
В прогнозных расчетах по уравнению регрессии определяется предсказываемое значение 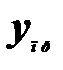 как точечный прогноз построенной функции
как точечный прогноз построенной функции 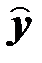 (путем подстановки в уравнение регрессии соответствующего значения
(путем подстановки в уравнение регрессии соответствующего значения 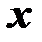 ). Точечный прогноз дополняется расчетом стандартной ошибки прогнозной оценки (myпр) и вычислением доверительных интервалов прогнозного значения.
). Точечный прогноз дополняется расчетом стандартной ошибки прогнозной оценки (myпр) и вычислением доверительных интервалов прогнозного значения.
Тема 13: Факторный анализ
1.Методы факторного анализа в маркетинговых исследованиях.
2.Алгоритмы факторного анализа.
В ходе реализации маркетингового исследования можно столкнуться со множеством переменных, большинство из которых взаимосвязаны. Для удобства обработки данных их число следует снизить до приемлемого уровня. С этой целью связи между коррелированными переменными анализируют и представляют в виде небольшого числа факторов.
То есть факторный анализ производят в том случае, если существует огромный массив данных, который необходимо уменьшить («сжать») для проведения дальнейшего исследования.
Факторный анализ часто предшествует применению других методов статистического анализа. Это совокупность методов, которые на основе объективно существующих взаимосвязей признаков (или объектов) позволяют выявлять латентные (или скрытые) обобщающие характеристики структуры изучаемых объектов и их свойств.
Таким образом, факторный анализ – метод, который позволяет сгруппировать большое число переменных, влияющих на предмет исследования и свести их к минимальному числу «обобщающих переменных» (факторов). Т.е. это метод преобразования исходных переменных в новые, некоррелирующие, называемые факторами.
Сущность факторного анализа заключается в следующем: имеющиеся зависимости между большим числом исходных наблюдаемых переменных определяются существованием гораздо меньшего числа скрытых или латентных переменных, называемых факторами, выявить которые можно на основе факторного анализа.
Факторный анализ дает возможность количественно измерить нечто, непосредственно неизмеряемое, исходя из нескольких доступных измерению переменных. Основное предположение факторного анализа заключается в том, что каждый наблюдаемый признак можно выразить в виде суммы некоторых других, ненаблюдаемых признаков (факторов), умноженных каждый на свой коэффициент. Эти коэффициенты принято называть факторными нагрузками. Значения факторных нагрузок, как правило, и являются результатом реализации алгоритма факторного анализа (они служат основой для интерпретации результатов).
Основная задача факторного анализа – это группировка схожих по смыслу утверждений в макрокатегории (факторы) с целью сократить число переменных и упростить процедуру анализа существующей базы данных. В один фактор объединяются несколько переменных, тесно коррелирующих между собой.
Таким образом, в результате факторного анализа мы получаем из несистематизированного массива данных несколько макропеременных, описывающих различные характеристики продукта.
Группировка производится по принципу – переменные, имеющие между собой высокую степень корреляции (тесную взаимосвязь), объединяются в один фактор.
Факторный анализ используется для решения двух основных задач:
1) исследование структуры взаимосвязей между переменными – т.е. классификация переменныхтруктуры взаимосвязей между переменными, т.е. ься числу переменных или пока исследователь не решит, что число полезных факторов;
2) уменьшение числа переменных (или редукция данных).
Факторный анализ позволяет исследователю описать объект измерения с одной стороны всесторонне, учитывая множество исходных тесно взаимосвязанных между собой переменных, а с другой стороны компактно с помощью небольшого числа переменных.
Факторный анализ широко используется в маркетинговых исследованиях:
- при сегментации рынка (с целью определения латентных переменных для группировки потребителей);
- при разработке товарной стратегии (для выявления набора характеристик торговой марки, влияющих на выбор потребителей);
- при планировании рекламной стратегии (для оценки коммуникационных предпочтений потребителя);
- при составлении стратегии ценообразования (для определения характеристик потребителей, наиболее чувствительных к ценовому фактору).
В классическом варианте факторном анализе используются переменные, измеренные по интервальной шкале.
При проведении факторного анализа могут возникнуть следующие сложности:
1) интерпретация результатов (т.е. подбор названий созданным факторам);
2) частичная потеря информации в ходе «сжатия» исходного массива информации.
В основе реализации факторного анализа лежит матрица корреляций – это симметричная матрица, отражающая все виды взаимосвязей между переменными. По матрице корреляций оценивается пригодность исходных данных для проведения факторного анализа. Для этого могут быть использованы следующие критерии:
Критерий Кайзера-Мейера-Олкина (КМО) позволяет оценивать, насколько полно построенная факторная модель описывает структуру респондентов на вопросы анкеты, представляющие исследуемые переменные.
Критерий Бартлетта, который проверяет гипотезу о том, что переменные, участвующие в факторном анализе, некоррелированы между собой.
Набор методов факторного анализа в настоящее время достаточно велик, существует несколько десятков подходов и приемов обработки данных. Наиболее распространенными являются:
1. методы факторного анализа (метод общих факторов)
При реализации этих методов основным показателем объема информации, предоставляемой каждым фактором, является его дисперсия. При этом образуемые факторы упорядочивают в порядке убывания дисперсии: то есть наиболее информативный – первый фактор; наименее информативный – последний.
При этом различают общие и характерные факторы:
– общие факторы – факторы, связанные значимыми коэффициентами веса более чем с одной переменной;
– характерный фактор – связан только с одной переменной, обобщает скрытую, нераскрываемую вариацию переменной.
В общем виде зависимость значений исходных переменных от значений факторов можно представить следующим выражением:
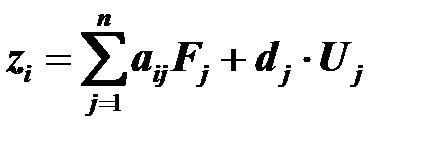 ,
,
где 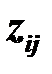 – значение стандартизированной j-й переменной по i-му объекту,
– значение стандартизированной j-й переменной по i-му объекту,
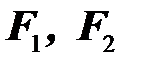 – общие факторы;
– общие факторы;
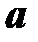 – весовые коэффициенты факторов для j-й переменной (элементы матрицы факторных нагрузок);
– весовые коэффициенты факторов для j-й переменной (элементы матрицы факторных нагрузок);
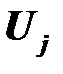 – j-й характерный (индивидуальный) фактор, присущий только данной j-й переменной;
– j-й характерный (индивидуальный) фактор, присущий только данной j-й переменной;
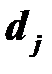 – нагрузка или весовой коэффициент j-й переменной на j-м факторе.
– нагрузка или весовой коэффициент j-й переменной на j-м факторе.
2. метод главных компонент. При анализе главных компонент учитывают всю дисперсию данных. В этом случае диагональ корреляционной матрицы из единиц, и вся дисперсия введена в матрицу факторных нагрузок.
Анализ главных компонент рекомендуется выполнять в том случае, когда основной задачей исследователя является определение минимального числа факторов, которые вносят максимальный вклад в дисперсию данных, чтобы в последующем использовать их в многомерном анализе. Эти факторы называют главными компонентами.
В общем виде зависимость значений исходных переменных от значений главных компонент при этом методе представлена следующим выражением:
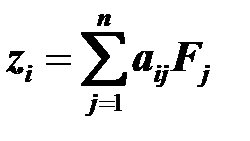 ,
,
где – значение стандартизированной j-й переменной по i-му объекту,
– весовые коэффициенты главной компоненты для j-й переменной (элементы матрицы факторных нагрузок);
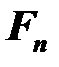 – j-ая главная компонента;
– j-ая главная компонента;
Одним из важнейших этапов факторного анализа является определение числа факторов. Выбор может быть основан на:
1) предварительной информации. Исследователь руководствуется предварительной информацией и оценивает, какое число факторов можно ожидать.
2) анализе собственных значений факторов. То есть учитывает только те факторы, собственные значения которых выше 1,0. Остальные факторы в модель не включают. Собственное значение – это значение дисперсии, обусловленной действием этого фактора.
3) использовании критерия «каменистой осыпи», предполагающее графическое изображение «каменистой осыпи» - графика зависимости собственных значений факторов от их количества в порядке выделения.
4) проценте объясненной дисперсии, когда число выделяемых факторов определяют таким образом, чтобы кумулятивный (накопленный) процент дисперсии, выделяемой факторами, достиг удовлетворительного уровня.
5) оценке надежности, выполняемой расщеплением. При этом выборку делят на две равные части и факторный анализ выполняют для каждой половины выборки. В итоге оставляют только факторы с высокой степенью соответствия факторных нагрузок в двух подвыборках.
Факторный анализ может давать несколько решений для любого набора данных. Каждое решение получается посредством схемы вращения факторов.
Факторную матрицу легко интерпретировать, когда она является простой, т.е. каждая исходная переменная 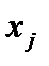 имеет значительную по величине нагрузку только на один фактор. Если матрица не является простой, ее подвергают процедуре вращения.
имеет значительную по величине нагрузку только на один фактор. Если матрица не является простой, ее подвергают процедуре вращения.
Цель процедуры вращения – расположить факторы в исходном пространстве признаков оптимальным образом для улучшения их интерпретации. Т.е. получение такой структуры факторов, в которой несколько исходных признаков xj существенно доминируют над другими. Это позволяет легко определить название и место фактора в конкретном анализе.
Т.е. вращение позволяет приблизить факторную модель к идеалу.
Используются следующие методы вращения:
1. ортогональное вращение – наиболее простое вращение, при котором сохраняется взаимное расположение осей под прямым углом. Факторы остаются некоррелирующими между собой
2. неортогональное (косоугольное) вращение –не сохраняется взаимное расположение факторов. В результате чего факторы могут коррелировать друг с другом.
Наиболее сложным этапом при проведении факторного анализа является интерпретация факторов. Здесь не существует универсального решения: в каждом конкретном случае аналитик использует имеющийся практический опыт, чтобы понять, почему факторная модель относит ту или иную переменную к данному конкретному фактору.
Интерпретация факторов основывается на матрице факторных нагрузок. Эта таблица является основным результатом факторного анализа.
Факторные нагрузки – представляют собой коэффициенты корреляции между выделенными факторами F и исходными переменными xj. Название фактора подбирается исходя из логики и названий переменных, объединенных этим фактором с учетом наибольшей нагрузки.
Обычно процедура содержательной интерпретации матрицы факторных нагрузок заключается в расположении нагрузок, относящихся к одному фактору в порядке убывания абсолютных значения. Рассматриваются признаки, имеющие максимальные абсолютные значения факторных нагрузок. Далее анализируется природа (содержание) этой группы признаков.
Выявляется общее содержание этой группы признаков, которое, по мнению исследователя, объединяет признаки в одну группу. Это свойство (группа свойств) затем получает название и фигурирует в качестве фактора.
Тема 14: Кластерный анализ
1. Понятие и применение кластерного анализа в маркетинговых исследованиях;
2. Порядок выполнения кластерного анализа;
3. Методы кластеризации: иерархическая и не иерархическая кластеризация;
Если процедура факторного анализа сжимает матрицу признаков в матрицу с меньшим числом переменных, кластерный анализ дает нам группы единиц анализа, иначе – выполняет классификацию объектов. Иными словами, если в факторном анализе мы группируем столбцы матрицы данных, то в кластерном группируются строки.
Кластерный анализ – это совокупность методов многомерной классификации объектов по заданным исходным признакам.
В отличие от комбинационных группировок кластерный анализ приводит к разбиению на группы с учетом всех группировочных признаков одновременно.
Задача кластерного анализа состоит в формировании групп однородных внутри (соблюдение условия внутренней гомогенности) и четко отличных друг от друга (соблюдение условия внешней гетерогенности).
В отличие от факторного анализа переменные группируются не на основе тесноты корреляционной связи, на основе исследования расстояний между переменными.
Цель кластерного анализа – разбиение множества исследуемых объектов, характеризуемых совокупностью признаков, на однородные группы – кластеры.
Кластерный анализ выступает одним из направлений статистического исследования. Особо важное место он занимает в тех сферах, которые связаны с изучением массовых явлений и процессов. Необходимость развития методов кластерного анализа продиктована, прежде всего тем, то они помогают построить научно обоснованные классификации, выявить внутренние связи между единицами наблюдаемой совокупности.
Объектом при этом выступает конкретный предмет исследования, нуждающийся в классификации. Объекты в каждом кластере должны быть похожи между собой и отличаться от объектов в других кластерах.
Признак характеризует конкретное свойство, характеристика объекта.
Кластерный анализ в маркетинговых исследованиях может использоваться при решении следующих задач:
1. определение целевых групп потребителей, для которых было бы целесообразно разработать специальное торговое предложение – сегментация потребителей.
2. определение конкурентоспособности товара путем кластеризации торговых марок (торговые марки в одном кластере конкурируют между собой более жестко. Фирма может изучить свои текущие предложения по сравнению с предложениями своих конкурентов, чтобы определить потенциальные возможности новых товаров).
3. распределение товаров по степени их использования (если выяснится, что две марки продуктов приобретает одно и та же группа людей, станут возможными меры по их совместному продвижению);
4. выявление групп (кластеров) схожих городов таким образом, чтобы можно было сопоставить различные маркетинговые программы, проведя их апробацию на разных городах и др.
Элементы, включаемые в один и тот же кластер, имеют разную степень схожести (уровень отличия друг от друга).
Техника кластерного анализа заключается в выявлении уровня схожести всех исследуемых элементов; последовательном объединении элементов в порядке возрастания уровня различия между ними.
Число выявленных кластеров зависит от заданного уровня схожести (различия) элементов, включаемых в один кластер.
Существует две группы методовформирования кластеров:
Иерархические методы –характеризуются построением иерархической (древовидной) структуры. Основаны на последовательном объединении отдельных объектов во все более крупные кластеры или разделении одного крупного кластера на более однородные. Если два объекта взаимосвязаны в своем кластере, то они останутся вместе и после проведения иерархической кластеризации.
Неиерархические методы – методы, при которых вначале определяют центр кластера, а затем группируют все объекты в пределах заданного от центра порогового значения. Такая кластеризация отличается тем, что она позволяет объектам покидать один кластер и присоединяться к другому в процессе образования кластеров, если это улучшает значение критерия кластеризации. Если требуется получить три кластера, то находят три центра. Эти центры могут быть случайными величинами или получены в результате иерархической кластеризации.
Чтобы произвести классификацию объекта вводят понятие сходства объектов по наблюдаемым переменным. Схожие объекты группируются вместе, а те, что отстоят от них, попадают в другие кластеры.
Если каждый объект описывается m признаками, то он может быть представлен как точка в m-мерном пространстве. Следовательно сходство с другими объектами будет определяться как соответствующее расстояние.
Мера расстояния и сходства – это способ вычисления расстояния между объектами.
Обычно рассматриваются следующие меры расстояний между объектами:
Евклидово расстояние – наиболее часто используется. Если изучается двумерное или трехмерное признаковое пространство, то это расстояние является реальным геометрическим расстоянием между объектами в пространстве.
Взвешенное евклидово расстояние – применяется, когда каждой k-й переменной присваиваются весовые коэффициенты, пропорциональные степени важности признака при проведении классификации.
Квадрат евклидова расстояния – используется, чтобы придать больше веса наиболее отдаленным друг от друга объектам. Благодаря возведению в квадрат при расчете лучше учитываются большие разности.
Расстояние Минковского – модификация евклидова расстояния, в котором вместо 2-й степени используется иная степень p (как правило, выбираемая исследователем).
Расстояние city-block (расстояние городских кварталов) – частный случай расстояния Минковского при p=1. Чаще всего используется для дихотомических качественных переменных, относящихся к номинальной шкале (имеющих всего два значения).
Существуют и другие меры расстояния, выбор которых зависит от типа критериев кластеризации.
Необходимо учитывать тот факт, что использование различных мер расстояния дает неодинаковые результаты в рамках одного метода объединения.
Один из основных вопросов кластерного анализа – определение числа выделяемых кластеров. Необходимо учитывать, что оптимальным является такое число кластеров, при котором сформированные кластеры с одной стороны, объединяют в себе как можно больше объектов исследования;с другой стороны, являются возможно менее гетерогенными внутри.
Здесь нет четких правил, но можно руководствоваться следующими подходами:
1) теоретическое обоснование числа кластеров. Аналитик определяет число кластеров, исходя из теоретических знаний и логики.
2) в качестве критерия можно использовать расстояние, при которых объединяются кластеры, так как при иерархической кластеризации объединение последних кластеров происходит при больших расстояниях.
3) построение графика зависимости соотношения внутригрупповой и межгрупповой дисперсий от числа факторов. Точка резкого изгиба (поворота) – указывает на приемлемое число кластеров;
4) уровень кластеризации. Можно задать уровень кластеризации, который будет выражен значением ее критерия. Если критерий кластеризации может быть легко интерпретирован, следует определить уровень, который и покажет число кластеров.
После формирования кластеров производят их интерпретацию. Для этого используют специальный показатель – центроиды кластеров.
Центроид представляет собой среднее значение каждой из переменных по объектам, содержащимся в кластере. Центроиды позволяют описывать каждый кластер, если присвоить ему номер или иную метку. Кроме того, изучение центроидов переменных по объектам, образующим кластер, позволит присвоить наименования кластерам (или профили).
При этом рекомендовано, присваивать кластерам профили, используя переменные, которые не были основанием для кластерного анализа (например, демографические, психографические характеристики покупателя и др.).
Из всех методов наиболее распространенными являются иерархические аметоды. При этом различают агломеративные и дивизимные иерархические методы.
Сущность агломеративной кластеризации – на первом этапе каждый объект выборки рассматривается как отдельный кластер. Затем происходит объединение кластеров на основе матрицы расстояний (или матрицы сходства). В итоге все объекты будут объединены в один кластер.
Результаты кластерного анализа в определяющей мере зависят от двух факторов меры расстояния между объектами и правила объединения кластеров друг с другом.
Различают следующие правила (методы) объединения кластеров:
1) метод одиночной связи, при котором на основе матрицы сходства (различий) определяются два наиболее схожих или близких объекта. Они и образуют первый кластер. На следующем шаге к ним присоединяется объект с максимальной мерой сходства (минимальным расстоянием) хотя бы с одним из объектов кластера. Т.е. степень сходства оценивается по расстоянию между ближайшими объектами кластеров.
2) метод полной связи, в основе которого лежит максимальное расстояние между объектами. Расстояние между двумя кластерами вычисляют как расстояние между двумя их сами удаленными точками (называют метод дальнего соседа). Присоединение объекта к кластеру происходит лишь в том случае, когда сходство между кандидатом на включение и любым из элементов кластера не меньше некоторого порогового значения;
3) метод средней связи – расстояние между двумя кластерами определяется как среднее значение всех попарных расстояний между объектами двух кластеров. Объект присоединяется к кластеру, если найденное среднее значение сходства достигает некоторого заданного порогового уровня.
4) центроидный метод – предполагает использование расстояния между центроидами двух групп. Центроид – это точка, координаты которой являются средними по всем наблюдениям в кластере. Если в кластере имеется только одно наблюдение, то оно само и будет центроидом. Группы, расстояния между центроидами которых являются минимальными, объединяются первыми.
Сущность дивизимной кластеризации – первоначально все объекты принадлежат одному кластеру. В процессе классификации по определенным правилам постепенно от этого кластера отделяются группы схожих между собой объектов. Таким образом, на каждом шаге количество кластеров возрастает, а мера расстояния между кластерами уменьшается.
Последовательность иерархического объединения можно изобразить графически в виде дерева объединения кластеров – дендрограммы. На дендрограмме указываются номера объединяемых объектов и расстояние (или иная мера сходства), при котором происходит объединении.
Наряду с иерархическими методами существует многочисленная группа неиерархических методов,которые работают непосредственно с объектами, а не с матрицей сходства.
К таким методам относят метод k-средних, идея которого заключается в том, что процесс классификации начинается с задания некоторых начальных условий – точное количество выделяемых кластеров и начальные значения каждого кластера (центроиды). После этого все объекты, которые попадают в заранее определенное пороговое расстояние от него, включаются в кластер. Если требуется получить решение с тремя кластерами – определяют три центра.
Этот метод позволяет объектам покидать один кластер и присоединяться к другому в процессе образования кластеров, если это улучшает значение критерия кластеризации. В отличие от иерархических методов этот метод не требует вычисления матрицы расстояний (или сходств). Алгоритм метода предполагает использование только исходных значений переменных.
Тема 15: Дискриминантный анализ
1. Назначение и процедуры дискриминантного анализа.
2. Основные понятия метода: дискриминационное множество, функция, переменные.
Если кластерный анализ выявляет возможность разбиения совокупности респондентов на группы, то дискриминантный анализ выявляет возможность установления различий уже существующих групп респондентов.
Дискриминантный анализ используется для принятия решения о том, какие переменные различают (дискриминируют) две или более возникающие совокупности (группы).
Например, если исследователь в области образования может захотеть исследовать, какие переменные относят выпускника средней школы к одной из трех категорий: (1) поступающий в колледж, (2) поступающий в профессиональную школу или (3) отказывающийся от дальнейшего образования или профессиональной подготовки. Для этой цели исследователь может собрать данные о различных переменных, связанных с учащимися школы. После выпуска большинство учащихся естественно должно попасть в одну из названных категорий. Затем можно использовать Дискриминантный анализ для определения того, какие переменные дают наилучшее предсказание выбора учащимися дальнейшего пути.
Дискриминантный анализ – статистический метод, который направлен на различение, т.е. разбиение (дискриминацию) объектов наблюдения по определенным признакам.
Цель дискриминантного анализа – выявление различий между исследуемыми группами.
Основное отличие от кластерного анализа в том, что в ходе дискриминантного анализа новые кластеры не образуются, а формулируется правило, по которому новые единицы совокупности относятся к одному из уже существующих множеств (классов).
Совокупности заведомо различаются, и каждый индивидуум принадлежит одной из них. Такой анализ можно использовать и для того, чтобы определить какие переменные вносят вклад в эту классификацию.
Задачи дискриминантного анализа:
1. определение линейной комбинации независимых переменных, которая позволяет разделить группы таким образом, чтобы объекты в различных группах были максимально разделены;
2. разработка процедур распределения между группами новых объектов (компаний или индивидуумов), характеристики которых известны, но неизвестна принадлежность их к той или иной группе;
3. проверка наличия значимых различий между группами на основе их центроидов;
4. определение переменных, объясняющих различия между группами наилучшим образом;
5. оценка точности классификации данных на группы;
6. отнесение случаев к одной и групп (классификация) исходя из значений предикторов.
Методы дискриминантного анализа находят применение в различных областях – медицине, социологии, психологии, экономике, маркетинге и т.л. При наблюдении больших статистических совокупностей часто появляется необходимость разделить неоднородную совокупность на однородные группы (классы). Такое расчленение в дальнейшем при проведении анализа дает лучшие результаты моделирования зависимостей между отдельными признаками.
Дискриминантный анализ в маркетинговых исследованиях может применяться для оценки следующих моментов:
а) чем с точки зрения демографических характеристик отличаются приверженцы данного магазина от тех, у кого эта приверженность отсутствует?
б) отличаются ли в потреблении замороженных продуктов покупатели, которые пьют безалкогольные напитки мало, умеренно или много?
в) различаются ли между собой различные сегменты рынка по своим предпочтениям к средствам массовой информации?
г) какими отличительными характеристиками обладают потребители, реагирующие на прямую почтовую рекламу и др.
Переменная, разделяющая совокупность объектов исследования на группы, называется группирующей.
Группирующая переменная должна быть номинальной (т.е. измеряться по номинальной шкале), а зависимые переменные – метрическими. Соблюдение этого условия обеспечивает высокую точность статистических расчетов.
При выборе зависимой переменной следует помнить, что увеличение числа категорий в ней практически всегда влечет уменьшение качества статистической модели, то есть ее точности и надежности.
Основным результатом дискриминантного анализа является расчет вероятности попадания каждого респондента (объекта) в ту или иную группу, а также поиск переменной, кодирующей их к данным группам.
Наряду с этим по результатам дискриминантного анализа можно составить уравнение дискриминантной функции.
В зависимости от количества обучающих выборок различают два метода дискриминантного анализа:
1. дискриминантный анализ для двух групп, который применяется, кода зависимая переменная имеет только две категории. В этом случае строится только одна дискриминантная функция;
2. дискриминантный анализ для трех и более групп – в этом случае применяется множественный дискриминантный анализ, когда у зависимой переменной есть три и более категорий. Тогда строится несколько дискриминантных функций (по количеству групп минус единицу).
В зависимости от правил дискриминациив литературе рассматривается три вида дискриминантного анализа:
1) линейный дискриминантный анализ Фишера – в этом случае правила дискриминации представлены в виде линейной комбинации дискриминантных переменных;
2) канонический дискриминантный анализ – правила дискриминации представлены в виде дискриминантных функций;
3) линейный дискриминантный анализ – правила дискриминации представлены совокупностью характеристик (групповая ковариационная матрица, групповой вектор средних, определитель ковариационной матрицы).
Наиболее часто применяется линейный дискриминантный анализ.
Выполнение дискриминантного анализа включает следующие стадии: формулирование проблемы, вычисление коэффициентов дискриминантной функции, определение значимости, интерпретация и проверка достоверности.
Первый шаг дискриминантного анализа — формулирование проблемы путем определения целей, зависимой переменой и независимых переменных.
Следующий шаг — разделение выборки на две части. Одна из них — анализируемая выборка — используется для вычисления дискриминантной функции. Когда выборка достаточно большая, ее можно разбить на две равные части. Одна служит анализируемой выборкой, а другую используют для проверки.
Анализируемая выборка (analysis sample) –это часть общей выборки, которую используют для вычисления дискриминантной функции. Другая часть — проверочная выборка (validation sample) — предназначена для проверки дис-
криминантной функции.
Проверочная выборка (validation sample)– это часть общей выборки, которую используют для проверки результатов расчета на основании анализируемой выборки.
После уточнения оптимального набора дискриминантных переменных исследователю предстоит решить вопрос о выборе вида дискриминантной функции. Функция f(x)=c называется канонической дискриминантной функцией:
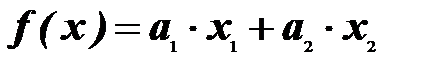
Величины 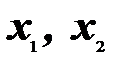 – дискриминантные переменные представляют собой значения признаков, которые используются для того, чтобы отличать один класс (подмножество) от другого.
– дискриминантные переменные представляют собой значения признаков, которые используются для того, чтобы отличать один класс (подмножество) от другого.
Величины 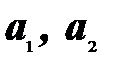 – дискриминантные множители, которые позволяют перейти от двухмерного пространства первичных показателей к одномерному, обеспечивая при этом минимальную ошибку классификации.
– дискриминантные множители, которые позволяют перейти от двухмерного пространства первичных показателей к одномерному, обеспечивая при этом минимальную ошибку классификации.
Таким образом, каноническая дискриминантная функция представляет собой линейную комбинацию двух переменных x1 и x2, которая наилучшим образом разграничивает объекты между двумя группами (множествами).
Дискриминантная функция может быть линейной и нелинейной. Выбор вида функции зависит от геометрического расположения разделяемых классов в пространстве дискриминантных переменных. Это достигается максимизацией межгрупповой вариации по сравнению с вариацией внутри групп.
Коэффициенты дискриминантной функции можно определить используя два способа:
1. прямой способ (принудительное включение) – это дискриминантный анализ, при котором дискриминантную функцию вычисляют при одновременном введении всех предикторов.
В этом случае учитывается каждая независимая переменная, при этом ее дискриминирующая (классификационная) сила не принимается во внимание. Используется, если аналитик предпочитает, чтобы в разграничении принимали участие все переменные.
2. пошаговый метод – это дискриминантный анализ, при котором переменные (предикторы) вводят последовательно.
Этот метод основан на минимизации внутригрупповых различий после включение в уравнение каждой новой переменной.
Если множества, используемые в качестве обучающих выборок, близко расположены друг к другу, то возрастает вероятность ошибочной классификации, особенно в тех случаях, когда классифицируемый объект сильно удален от центров обоих множеств. Складывается ситуация, при которой распознавание объекта затруднено. Одним из возможных выводов в таком случае является пересмотр набора дискриминантных переменных.
В качестве дискриминантных переменных могут выступать не только исходные (наблюдаемые) признаки, но и главные компоненты или главные факторы.
Бессмысленно интерпретировать результаты анализа, если определенные дискриминантные функции не являются статистически значимыми. Поэтому следует выполнить статистическую проверку нулевой гипотезы о равенстве средних всех дискриминантных функций во всех группах генеральной совокупности. Для того, чтобы произвести оценку значимости дискриминантной функции используют различные критерии:
1. собственное значение Лямбда, рассчитанное значение которого показывает, во сколько раз изменчивость между группами превышает изменчивость внутри групп. Представляет собой отношение межгрупповой дисперсии к внутригрупповой. Принято считать – чем больше значения лямбда, тем лучше подобрана дискриминантная функция.
2. критерий Уилкса – используется для оценки существенности различий между средними значениями дискриминантной функции в разных группах.
При применении этого критерия выдвигается нулевая гипотеза: средние дискриминантной функции по каждой группе равны. Расчетное значение критерия сравнивается с табличным и принимается решение о принятии или отклонении нулевой гипотезы.
Характеристика коэффициентов дискриминантной функции производится по аналогии с корреляционно-регрессионным анализом. Значение коэффициента при определенной независимой переменной зависит от других переменных, входящих в дискриминантную функцию.
Коэффициенты дискриминантной функции могут быть проинтерпретированы обычным образом: чем больше стандартизованный коэффициент, тем больше вклад соответствующей переменной в дискриминацию совокупностей. Однако эти коэффициенты не дают информации о том, между какими совокупностями дискриминируют соответствующие функции.
Для оценки вклада отдельной переменной в значение дискриминантной функции целесообразно пользоваться стандартизованными коэффициентами детерминации.
Помимо определения вклада каждой исходной переменной в дискриминантную функцию, можно проанализировать и степень корреляционной зависимости между ними.
Некоторое представление об относительной важности предикторов можно также получить, изучив структурные коэффициенты корреляции, которые также называют каноническими или дискриминантными нагрузками. Эти линейные коэффициенты корреляции между каждым из предикторов и дискриминантной функцией представляют дисперсию, которую предиктор делит вместе с функцией. Как и нормированные коэффициенты, эти коэффициенты корреля-
ции следует использовать осторожно.
Дискриминантный анализ можно использовать как метод прогнозирования поведения наблюдаемых единиц статистической совокупности на основе имеющихся стереотипов поведения аналогичных объектов, входящих в состав объективно существующих или сформированных по определенному принципу множеств (обучающих выборок). Это уравнение позволяет по известным значениям независимой переменной определить неизвестные значения зависимой переменной (критерия классификации) для другой выборки.
Тема 16: Многомерное шкалирование
1. Понятие и использование многомерного шкалирования в маркетинге;
2. Порядок выполнения многомерного шкалирования.
Методы многомерного шкалирования разрабатывались и применяются в практике для исследований сложных явлений и процессов, не поддающихся непосредственному описанию или моделированию.
Многомерное шкалирование – объединяет класс методов, позволяющих представить большой массив данных о сходстве (различиях) изучаемых объектов в наглядном, доступном для интерпретации графическом виде.
Источниками данных при многомерном шкалировании выступают:
1. эксперты, субъективно воспринимающие и оценивающие относительное расположение объектов в реальных условиях;
2. результаты прямой регистрации сведений о состоянии и поведении объектов.
Целью такого анализа является определение местонахождения объекта в «пространстве восприятия» его субъектами (экспертами, респондентами) и создание его образа.
Воспринимаемые (психологические) взаимосвязи между объектами представляются в виде геометрических связей между точками в многомерном пространстве. Эти геометрические представления называют пространственными картами. Оси координат на пространственной карте соответствуют психологическим факторам поведения человека или, иначе говоря, основным размерностям, которыми пользуются респонденты для формирования восприятия и предпочтения объектов
Методы многомерного шкалирования используются для решения следующих задач:
1) сжатие признакового пространства;
2) визуализация расположения наблюдаемых объектов относительно друг друга в теоретическом пространстве;
3) выявление латентных факторов, предопределяющих пространственное расположение, различие наблюдаемых объектов.
В отличие от других методов анализа в многомерном шкалировании представление объектов осуществляется не по значениям характеризующих их признаков, а по данным, представляющим сходства (или различия) объектов.
Многомерное шкалирование используют в маркетинге, чтобы определить следующее:
1. Количество и природу измерителей, которые используют потребители, чтобы выразить свое отношение к торговым маркам на рынке.
2. Позиционирование имеющихся торговых марок согласно этим измерителям.
3. Позиционирование идеальных потребительских торговых марок по этим измерителям.
Направления использования в маркетинговых исследованиях:
1.измерение имиджа.Сравнение восприятия фирмы потребителями и непотребителями её продукции по сравнению с собственным восприятием фирмы самой себя;
2. сегментация рынка. Расположение в одном и том же пространстве торговых марок и потребителей для выявления относительно однородных по восприятиям групп;
3. разработка новой торговой марки. Многомерное шкалирование позволяет увидеть пробелы на пространственной карте, которые сигнализируют о возможностях позиционирования новых продуктов. Кроме того, с помощью тестирования возможно оценить новый товар и существующие торговые марки и таким образом определить, как потребители воспринимают новые идеи, заложенные в товаре. Доля тех, кто в процессе исследования предпочтет новый продукт, отражает его шансы на успех в будущем;
4. оценка эффективности рекламы. Предполагает изучение положения торговой марки на пространственной карте до и после реализации рекламной кампании.
5. ценовой анализ. Сопоставление карт восприятия, построенных по данным, когда респондентам сообщают и не сообщают цены на товар, позволяют судить о воздействии ценового фактора.
6. решение о размерах каналов сбыта. Суждения респондентов о сравнительных характеристиках брендов, высказанные ими в разных торговых точках, позволяют получить карты восприятия, полезные с точки зрения выбора каналов распространения товара.
7. построение шкалы отношений. Методы многомерного шкалирования используются для конструирования новой шкалы, по которой потребители будут оценивать свойства товара.
Можно перечислить следующие основные понятия и категории многомерного шкалирования:
Сходство (подобие) –это величина, которая показывает, в какой степени два объекта являются (или воспринимаются) одинаковыми или различными.
Стимул–это некоторое свойство объекта, его признак, качественная либо количественная, но непосредственно не измеряемая характеристика изучаемого объекта. В аналитической практике это обычно объект, обладающий определенным набором характеристик.
Стресс–это мера соответствия построенной модели исходным данным по каждому объекту. Чем ниже значение стресса, тем лучше качество модели.
Коэффициент R2 – характеризует долю дисперсии (вариации) в матрице различий между объектами, обусловленную построенной моделью. Чем лучше модель, тем выше значение коэффициента R2.
Пространственная карта. Воспринимаемые взаимосвязи между торговыми марками или другими объектами, представленные в виде геометрических связей между точками в многомерном пространстве.
Исследователь должен тщательно сформулировать проблему многомерного шкалирования, поскольку можно использовать большое разнообразие исходных данных. Задача маркетолога — определить соответствующую форму для получения данных и выбрать метод многомерного шкалирования для их анализа. Важный аспект решения включает определение размерности для пространственной карты. Кроме того, следует обозначить оси координат на карте и интерпретировать выведенную на основе данных конфигурацию точек. И наконец, исследователь должен оценить качество полученных результатов.
При формулировании проблемы исследователю необходимо конкретизировать цель использования результатов многомерного шкалирования и выбрать торговые марки или другие объекты, которые предполагается проанализировать. Именно они определяют размерность шкалирования и получаемые конфигурации. Чтобы получить хорошо определяемую пространственную карту, следует включить как минимум восемь торговых марок или объектов. Включение свыше 25 торговых марок, вероятно, будет громоздким и утомит респондентов при опросе.
Очень внимательно надо подходить к выбору конкретных торговых марок или объектов. Предположим, что исследователь заинтересован узнать восприятия покупателей автомобилей. Если автомобили-люкс не включены в набор объектов, результаты могут быть искажены. В основе выбора количества торговых марок и их конкретных наименований должна лежать проблема, маркетингового исследования, теоретические предпосылки и интуиция исследователя.
Как было сказано, исходные данные, полученные от респондентов, должны быть связаны с восприятиями или предпочтениями.
Данные, касающиеся восприятия объектов, могут быть прямыми или непрямыми.
Восприятие объектов: прямые подходы. При использовании прямого подхода к сбору данных о восприятии респондентов просят оценить, используя их собственный критерий, насколько похожи или не похожи между собой различные известные торговые марки. От респондентов часто требуется оценить все возможные пары известных торговых марок, рассматривая сходство по шкале Лайкерта. Эти данные связаны с оценками респондентов о сходстве това-
ров.
Существуют и другие методы сбора данных. Респондентов можно попросить проранжировать все возможные пары от наиболее похожих к наименее похожим. В другом методе респонденты ранжируют известные торговые марки по сравнению с определенной базовой торговой маркой. Каждая торговая марка, в свою очередь, служит такой базой.
Восприятие объектов: непрямые подходы. Непрямые подходы (derived approaches) к сбору данных о восприятии основаны на характеристиках объектов и требуют, чтобы респонденты оценивали объекты, исходя из их определенных характеристик, используя семантическую дифференциальную шкалу или шкалу Лайкерта.
Иногда в набор объектов также включают идеальную торговую марку. Респондентов просят оценить гипотетическую идеальную торговую марку по одному и тому же набору характеристик. Если атрибутивные рейтинги получены, то для каждой пары торговых марок выводят меру сходства (евклидово расстояние).
Прямые методы по сравнению с непрямыми методами. Прямые методы имеют то преимущество, что исследователю не приходится определять набор явных характеристик. Респонденты оценивают сходство объектов, используя собственный критерий. К недостаткам прямого подхода можно отнести то, что на критерий влияют рассматриваемые торговые марки. Если различные известные марки автомобилей находятся в одном псионом диапазоне, то цена не будет важным фактором. Достаточно сложно определить перед началом анализа, надо ли и если надо, то как объединять оценки респондентов. Более того, может быть затруднительно дать название размерностям на пространственной карте. Преимущество непрямого подхода состоит в том, что легко разделить респондентов на однородные группы в соответствии с их отношением к объекту, т.е. исходя из оценок свойств объекта. Также легко обозначить размерности на пространственной карте. Недостатком метода считается то, что исследователь должен определить все явные характеристики, а это непростая задача. На основе идентифицированных характеристик получают пространственную карту.
Прямые подходы используют чаще, чем непрямые (атрибутивные). Однако лучше всего использовать оба подхода как взаимодополняющие. Суждения респондентов о сходстве объектов, полученные прямым методом, используются для получения пространственной карты, а атрибутивные оценки — для интерпретации размерностей карты восприятий. Аналогичные процедуры используют для данных, касающихся предпочтений респондентов.
Данные, касающиеся предпочтений респондентов.Спомощью данных о предпочтениях маркетолог-исследователь может увидеть порядок предпочтения объектов респондентами с точки зрения какого-либо их свойства. Обычный способ получения таких данных — ранжирование предпочтений. От респондентов требуется проранжировать торговые марки в порядке снижения их предпочтения (от наиболее предпочитаемого к наименее). Альтернативно, респондентов можно попросить выполнить попарное сравнение и указать, какую торговую марку они предпочитают в данной паре. Другой метод сбора данных о предпочтениях — получение оценок предпочтений для разных торговых марок. (Ранжирование, попарное сравнение и определение рейтинга изложены в главах 8 и 9 при обсуждении методов шкалирования). Если в основе пространственной карты лежат данные о предпочтениях, то расстояние означает различие в предпочтениях.
Контур пространственной карты, построенной по данным о сходстве объектов и по данным о предпочтениях, может различаться.
Выбор метода зависит от того, какие именно данные (о сходствах или предпочтениях) подлежат шкалированию.
Всю совокупность методов МШ подразделяют на два больших класса:
1. метрические методы – используются для обработки порядковых (количественных) данных;
2. неметрические методы– применяют, когда исходными являются неколичественные данные (порядковые, ранговые и др.).
Конечная цель многомерного шкалирования — получить пространственную карту с наименьшим количеством размерностей, которая наилучшим образом подходит для анализа исходных данных. Однако пространственные карты рассчитывают таким образом, что соответствие модели исходным данным увеличивается с ростом количества размерностей пространства.
Для определения соответствия между исходными данными и построенной моделью используют показатель стресса. Он является мерой соответствия подогнанной модели исходным данным; чем выше значение стресса, тем ниже качество подгонки модели.
Как только пространственная карта создана, необходимо дать название соответствующим размерностям (осям координат на пространственной карте) и интерпретировать конфигурацию точек на карте. Исследователь самостоятельно принимает решение об обозначении размерности, руководствуясь своим опытом. В этом помогут следующие указания.
• Даже если прямым метолом получены суждения респондентов о сходстве объектов, то все равно можно собрать рейтинги торговых марок по характеристикам объекта. С помощью регрессионного анализа эти атрибутивные векторы можно расположить на пространственной карте. Затем осям координат дается обозначение, исходя из того, насколько близко векторы совмещаются с соответствующими осями.
• После сбора прямым методом респондентами оценок сходства или восприятия их можно попросить указать критерий, используемый в их оценках. Затем эти критерии привязываются к осям пространственной карты.
• По возможности респондентам следует показывать пространственные карты, получившиеся на основе их оценок и попросить обозначить оси, анализируя получившуюся конфигурацию точек.
• Если существуют объективные характеристики товаров (например, лошадиная сила или количество пройденных километров на литр бензина для автомобилей), то их можно использовать как средство интерпретации субъективных размерностей пространственной карты.
Если значения на шкалах не поддаются логическому объяснению, осуществляют поворот шкального пространства. Для этого используют такие методы как: варимакс; квартимакс; облимакс и др.
Тема 17: Совместный анализ
1. Сущность совместного анализа и возможности его применения в маркетинговых исследованиях;
2. Алгоритм совместного анализа;
3. Методы анализа и интерпретации результатов.
С помощью совместного анализа (conjoint analysis) маркетологи пытаются определить относительную важность, которую придают потребители ясно выраженным характеристикам, а также полезность, которую они связывают с уровнями характеристик.
Эту информацию маркетологи получают из оценок потребителями торговых марок или профилей торговых марок, составленных из характеристик товаров и их уровней. Респондентов знакомят с объектами, которым присущи определенные характеристики и уровни этих характеристик, и просят оценить эти объекты с точки зрения желательности тех или иных характеристик. Маркетологи, используя метод совместного анализа, пытаются присвоить уровням каждой характеристики определенную ценность. В итоге ценности или полезности, которыми обладает каждый объект, тесно согласуются с исходными оценками респондентов. Основное допущение состоит в том, что любой набор объектов, таких как изделия, торговые марки или магазины, оценивают как пучок характеристик
Таким образом, совместный анализ – это специальные методы сбора и анализа данных, при помощи которых маркетологи определяют наилучшую конфигурацию новых или уже существующих продуктов (или услуг).
Он позволяет определить самый лучший набор атрибутов, составляющий товар или услугу, предложенный на рынке.
Эти методы получили распространение с середины 1990-х годов. В России и Беларуси практически не применяется (из-за отсутствия специалистов).
Название «совместный» (conjoint) происходит от комбинации двух слов consider jointly – рассматривать совместно. В просторечии называют конджоинг.
Важная цель совместного анализа – измерение степени предпочтения потребителем одного из конкурирующих продуктов (услуг) в условиях предположения о комплексной оценке всех атрибутов, составляющих продукт.
Совместный анализ позволяет количественно оценить важность одной характеристики продукта по сравнению с другой.
Подобно многомерному шкалированию, совместный анализ опирается на субъективные оценки респондентов. Однако, существуют следующие отличия:
1. если в многомерном шкалировании объекты представляют собой изделия или торговые марки, то в совместном анализе— комбинации уровней характеристик объекта, определяемые исследователем.
2. целью многомерного шкалирования является разработка пространственной карты, изображающей объекты в многомерном пространстве восприятий или предпочтений. С помощью совместного анализа маркетологи стремятся определить функции частной ценности или полезности, описывающие полезность, которую потребители присваивают уровням каждой характеристики.
Эти два метода взаимно дополняют друг друга.
Совместный анализ используют в маркетинге для различных целей.
• Определение относительной важности характеристик в процессе выбора товара потребителем. Типичный результат совместного анализа представляет собой веса относительной важности для всех характеристик, используемых для описания объектов. Веса относительной важности показывают, какие из характеристик больше всего влияют на выбор потребителя.
• Определение рыночной доли торговых марок, которые различаются уровнями своих характеристик. Значения полезностей, полученные в результате совместного анализа, можно использовать как исходные данные в модели выбора, чтобы определить долю, выпадающую на те или иные марки, и, следовательно, долю рынка различных торговых марок.
• Определение структуры свойств наиболее предпочитаемой торговой марки. Свойства торговой марки могут варьировать с точки зрения уровней характеристик и соответствующих полезностей. Свойства торговой марки, которые приводят к наивысшей полезности, указывают структуру характеристик наиболее предпочитаемой торговой марки.
• Сегментирование рынка, исходя из сходства предпочтений для уровней характеристик. Функции частной ценности, полученные для характеристик, можно использовать как основу для кластеризации респондентов в однородные по своим предпочтениям сегменты.
Совместный анализ находит применение при изучении потребительских и промышленных товаров, финансовых и других услуг. Более того, эти применения совместного анализа простираются на всю сферу маркетинга. Б недавнем обзоре совместного анализа сообщается о применении совместного анализа для определения идеи нового товара, конкурентного анализа, ценообразования, сегментации рынка, рекламы
Основные категории совместного анализа:
Атрибут – это одна из рассматриваемых характеристик продукта. Иногда называют фактором или переменной.
Уровень атрибута – вариант принимаемого атрибутом значения. В некоторых случаях называют возможность или качество.
Профиль – полное описание продукта с конкретным набором уровней атрибутов. Некоторые исследователи называют профиль стимулом или карточкой.
План исследования – количество и конкретный набор профилей. Некоторые исследователи называют дизайном.
Полный план – участвуют все возможные наборы уровней атрибутов (профили). При этом количество профилей равно произведению количества всех уровней атрибутов.
Неполный план – участвуют только необходимые для дальнейшего анализа профили.
Полезность – числовое значение, которое процедура совместного анализа присваивает уровням. На основании полезностей уровней вычисляют важность каждого из атрибутов.
Парные таблицы – таблицы, в которых респонденты одновременно оценивают по две характеристики до тех пор, пока не оценят все пары характеристик.
Формулирование проблемы совместного анализа включает идентификацию основных характеристик объекта и их уровней. Эти характеристики и их уровни используют для конструирования объектов в задаче совместного оценивания. Респонденты оценивают или ранжируют объекты, используя подходящую шкалу, и полученные данные анализируют. Результаты интерпретируют и оценивают их надежность и достоверность.
При формулировании проблемы совместного анализа исследователь должен определить характеристики и уровни характеристик (атрибутивные уровни), используемые в конструировании объектов. Атрибутивный уровень указывает на значение данной характеристики. С теоретической точки зрения выбранные характеристики должны быть явно выраженными, вносить основной вклад в предпочтения и выбор потребителей. Например, при выборе марки автомобиля в характеристики следует включить цену автомобиля, расход бензина на определенное количество километров пути, объем салона автомобиля и т.п.
После определения характеристик следует выбрать подходящие уровни. Их число определяет число оцениваемых параметров, а также влияет на число объектов, которые будут оцениваться респондентами. Чтобы облегчить задачу, стоящую перед респондентами, и при этом оценивать параметры с достаточной точностью, желательно ограничить число уровней.
Существует два широко распространенных подхода к построению объектов в совместном анализе — попарный подход и метод полного профиля (полнопрофильный метод).
В попарном подходе, также называемом методом двухфакторных оценок, респонденты одновременно оценивают по две характеристики до тех пор, пока не оценят все возможные пары характеристик.
В подходе полного профиля, также известного под названием метод многофакторных оценок, для всех характеристик строили полные профили торговых марок. Обычно каждый профиль описывают на отдельной индексной карточке.
Преимущество попарного метода в том, что он легче для респондентов: им проще высказать свое мнение при попарном сравнении характеристик. Однако относительным недостатком этого подхода является то, что в нем требуется сделать больше оценок, чем при использовании полнопрофильного метода.
Кроме того, задача оценивания может оказаться нереалистичной, если одновременно оценивают только две характеристики. Сравнение двух подходов показывает, что оба метода приводят к сопоставимым функциям полезности, однако полнопрофильный метод распространен больше.
Как и в многомерном шкалировании, исходные данные для совместного анализа бывают неметрическими или метрическими. Для получения неметрических данных респондентов обычно просят дать оценку в виде рангов.
При попарном подходе респонденты ранжируют все ячейки каждой из матриц, определяя их желательность.
При полнопрофильном методе они ранжируют все профили объектов. Ранги включают относительные оценки атрибутивных уровней. Сторонники ранжированных данных полагают, что такие данные точно отражают поведение потребителей на рынке.
При использовании метрических переменных респонденты пользуются рейтингами, а не рангами. Сторонники рейтинговых данных полагают, что они удобнее для респондентов и их анализировать легче, чем ранжированные данные. Последнее время наблюдается рост исследований именно с рейтинговыми данными.
В совместном анализе зависимая переменная обычно представляет собой предпочтение или намерение совершить покупку. Другими словами, респонденты предоставляют рейтинги или ранги, выражающие их предпочтения или намерения покупки. Однако методология совместного анализа достаточно гибкая и позволяет использовать диапазон других зависимых переменных, включая фактическую покупку или выбор.
Основная процедура совместного анализа состоит в вычислении частных полезностей для каждого уровня профилей.
Для оценки параметров модели можно использовать различные методы:
1. регрессионный анализ;
2. логит-регрессия;
3. регрессионный анализ с фиктивными переменными и др.
Для интерпретации результатов совместного анализа целесообразно построить графики функций полезности. Функция полезности – визуально описывает оценки респондентом уровней различных атрибутов объектов.
Совместный анализ имеет ряд допущений и ограничений. Его использование предполагает, что можно определить важные характеристики изделия. Более того, подразумевается, что потребители оценивают выбор вариантов с позиции этих характеристик и идут на определенные компромиссы. Однако в ситуациях, где значение имеет торговая марка изделия, потребители не могут оценивать марки через их характеристики. Даже если потребители принимают во внимание характеристики, полученная компромиссная модель может не отражать достаточно хорошо процесс выбора. Другое ограничение совместного анализа состоит в том, что набор данных может быть сложным, особенно если он включает большое число характеристик, а модель должна оцениваться на индивидуальном уровне. Остроту этой проблемы до некоторой степени можно смягчить такими методами, как интерактивный, или адаптивный совместный анализ и гибридный совместный анализ.
Тема 18: Подготовка отчёта о результатах маркетингового исследования
1. Функции и структура отчёта.
2. Подготовка устной презентации отчёта.
3. Использование пакетов Microsoft Excel и Microsoft Power Point для подготовки презентации результатов маркетингового исследования.
Подготовка отчета и его презентация — последний этап маркетинговых исследований. Ему предшествуют определение проблемы, разработка подхода, формулирование плана исследования, полевые работы, подготовка данных и их анализ.
Как и любой товар результаты маркетинговых исследований должны быть хорошо упакованы. Итоги маркетингового исследования можно представить в виде краткого общедоступного изложения сущности исследования или полного научного отчета. Обычно письменный отчет сопровождается устной презентацией.
Отчет о результатах маркетингового исследования и его презентация — важные части проекта маркетингового исследования.
1. Они являются ощутимым результатом проведенной работы. После завершения проекта и принятия руководством решения, не существует никакого другого документального подтверждения маркетингового исследования, за исключением письменного отчета. Он выступает фактическим свидетельством выполненного проекта.
2. Менеджмент компании при принятии решений руководствуется отчетом и презентацией. Если первые пять этапов проекта маркетинговых исследований выполнены тщательно, а шестому уделено слишком мало внимания, то ценность проекта для заказчика резко снижается.
3. Во многих случаях менеджеры-маркетологи компании-заказчика ограничивают свое участие в проекте знакомством с письменным отчетом и устной презентацией. Они оценивают качество всего проекта по отчету и презентации.
4. На решение менеджмента о проведении маркетингового исследования в будущем или о продолжении сотрудничества с конкретной фирмой для проведения повторного исследования влияет восприятие полезности отчета и презентации.
Маркетологи по-разному
Дата добавления: 2016-06-13; просмотров: 2101;