Системы кодировки текста
См презентацию Двоичное кодиров.
Имеется две системы кодировки: на основе ASCII и Unicode.
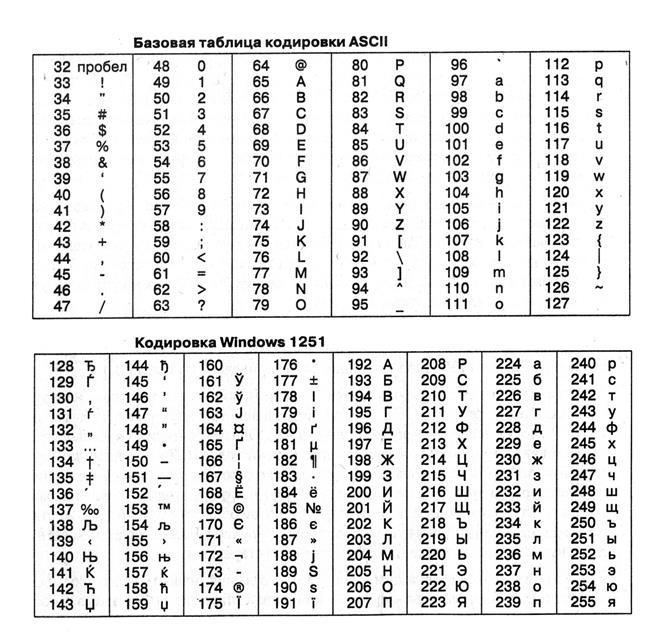 В системе кодирования ASCII (American Standard Code for Information Interchange – стандартный код информационного обмена США) каждый символ представлен одним байтом, что позволяет закодировать 256 символов.
В системе кодирования ASCII (American Standard Code for Information Interchange – стандартный код информационного обмена США) каждый символ представлен одним байтом, что позволяет закодировать 256 символов.
В ASCII имеется две таблицы кодирования — базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255. Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и общепринятые специальные символы, которые можно наблюдать на клавиатуре.
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств (в первую очередь, производителям компьютеров и печатающих устройств). В этой области размещаются так называемые управляющие коды, которым не соответствуют никакие символы языков, и, соответственно, эти коды не выводятся ни на экран, ни на устройства печати, но ими можно управлять тем, как производится вывод прочих данных. Начиная с кода 32 по код 127, размещены символы английского алфавита, знаки препинания, цифры, арифметические действия и вспомогательные символы, все их можно видеть на латинской части клавиатуры компьютера.
 Вторая, расширенная часть отдана национальным системам кодирования. В мире существует много нелатинских алфавитов (арабский, еврейский, греческий и пр.), в число которых входит и кириллица. Кроме того, немецкая, французская, испанская раскладки клавиатуры отличаются от английской.
Вторая, расширенная часть отдана национальным системам кодирования. В мире существует много нелатинских алфавитов (арабский, еврейский, греческий и пр.), в число которых входит и кириллица. Кроме того, немецкая, французская, испанская раскладки клавиатуры отличаются от английской.
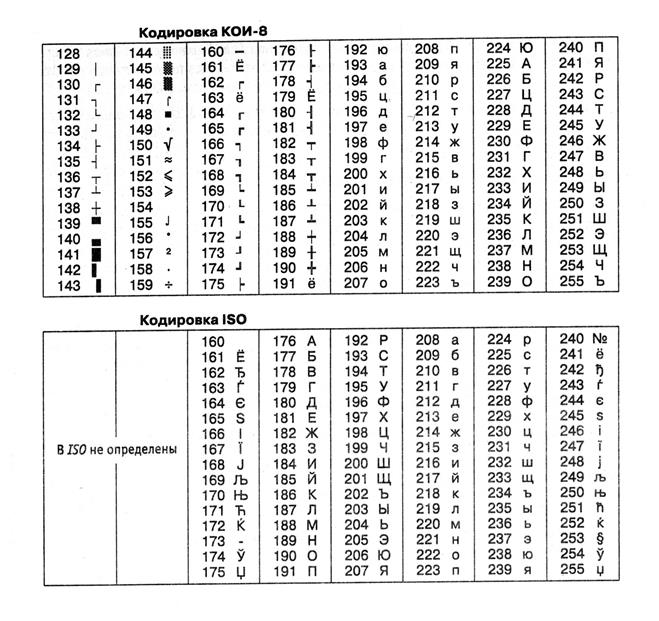
В английской части клавиатуры раньше было много стандартов, а теперь все они заменены на единый код ASCII. Для русской клавиатуры тоже существовало много стандартов: ГОСТ, ГОСТ-альтернативная, ISO (International Standard Organization — Международный институт стандартизации), но эти три стандарта фактически уже вымерли, хотя и могут где-то встретиться, в каких-то допотопных компьютерах или сетях.
Основная кодировка символов русского языка, которая используется в компьютерах с операционной системой Windows называется Windows-1251, она была разработана для алфавитов кириллицы компанией Microsoft. Естественно, что в Windows-1251 закодировано абсолютное большинство русскоязычных текстов. Кстати кодировки с другим четырехзначным номером разработаны Microsoft для других распространенных алфавитов:Windows-1250 для расширенной латиницы (различные национальные латинские буквы), Windows-1252 для иврита, Windows-1253 для арабской письменности, и т.д.
Другая, менее распространенная кодировка носит название КОИ-8(код обмена информацией, восьмизначный). Ее происхождение относится к 60-м годам XX века. Тогда не существовало персональных компьютеров, сети Интернет, компании Microsoftи многого другого. Но в СССР уже было довольно много ЭВМ, и для них требовалось разработать стандарт кодировки кириллицы.
Сегодня кодировка КОИ-8 имеет распространение в компьютерных сетях на территории бывшего СССР и в русскоязычном секторе Интернета. Бывает так, что какой-то текст письма или еще чего-то не читается, это значит, что надо перейти из КОИ-8 или другой кодировки в Windows-1251.
В 90-х годах крупнейшие производители программного обеспечения: Microsoft, Borland, та же Adobe приняли решение о разработке другой системы кодировки текста, в которой каждому символу будет отводиться не 1, а 2 байта. Она получила название Unicode.
С помощью 2-х байтов можно закодировать 65 536 символов. Этого массива оказалось достаточно для размещения в одной таблице всех национальных алфавитов, существующих на Земле. Кроме того, в Unicode включены много различных служебных обозначений: штрих коды, азбука Морзе, азбука флагов, азбука Брайля (для слепых), знаки валют, геометрические фигуры и многое другое.
Всего Unicode насчитывает более 90 страниц, на каждой расположен какой-либо национальный или служебный алфавит. И еще около 5 тысяч символов занимает так называемая «область общего назначения», незаполненная, оставленная в качестве резерва.
Самую большую страницу (около 70% всегоUnicode) занимают китайские иероглифы, которые в Китае набирают с помощью клавиатурных наборов. Водной только Индии имеется 11 различных алфавитов, есть в Unicodeмножество экзотических названий, например: письменность канадских аборигенов. Вообще рассмотрение национальных письменностей довольно занимательно с точки зрения географии и истории.
Преимущества Unicode очевидны. Система стандартизует все национальные и служебные текстовые символы. Устраняется путаница, возникающая из-за различных национальных стандартов. Создаются даже шрифты для всех алфавитов, например Arial Unicode.
Поскольку на кодирование каждого символа в Unicode отводится не 8, а 16 разрядов, объем текстового файла увеличивается примерно в 2 раза. Когда-то это было препятствием для введения 16-разрядной системы. А сейчас, при современном уровне развития компьютерной техники, увеличение размера текстовых файлов большого значения не имеет. Тексты занимают очень мало места в памяти компьютеров.
Кириллица занимает в Unicode места с 768 по 923 (основные знаки) и с 924 по 1023 (расширенная кириллица, различные малораспространенные национальные буквы). Если программа не адаптирована под кириллицу Unicode, то возможен вариант, когда символы текста распознаются не как кириллица, а как расширенная латиница (коды с 256 по 511). И в этом случае вместо текста на экране появляется бессмысленный набор экзотических символов.
Такое возможно, если программа устаревшая, созданная до 1995 года. Или малораспространенная, о русификации которой никто не позаботился. Еще возможен вариант, когда установленная на компьютере ОС Windowsне полностью настроена под кириллицу. В этом случае надо сделать соответствующие записи в реестре Windows.
Дата добавления: 2016-04-22; просмотров: 5106;