Диаграмма состояний с действиями
Анализ текста проводится путем разбора по регулярным грамматикам и опирается на способ разбора по диаграмме состояний, снабженной дополнительными пометками-действиями. В диаграмме состояний с действиями каждая дуга имеет вид, представленный на рисунке 2.4. Смысл этой конструкции: если текущим является состояние А и очередной входной символ совпадает с 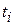 для какого либо i, то осуществляется переход в новое состояние В, при этом выполняются действия D1, D2,…, Dm.
для какого либо i, то осуществляется переход в новое состояние В, при этом выполняются действия D1, D2,…, Dm.
Для удобства разбора вводится дополнительное состояние диаграммы ER, попадание в которое соответствует появлению ошибки в алгоритме разбора. Переход по дуге, не помеченной ни одним символом, осуществляется по любому другому символу, кроме тех, которыми помечены все другие дуги, выходящие из данного состояния.

Рисунок 4.2 – Дуга ДС с действиями
АлгоритмРазбор цепочек символов по ДС с действиями
Шаг 1. Объявляем текущим начальное состояние ДС H.
Шаг 2. До тех пор, пока не будет достигнуто состояние ER или конечное состояние ДС, считываем очередной символ анализируемой строки и переходим из текущего состояния ДС в другое по дуге, помеченной этим символом, выполняя при этом соответствующие действия. Состояние, в которое попадаем, становится текущим.
ЛА строится в два этапа:
1) построить ДС с действиями для распознавания и формирования внутреннего представления лексем;
2) по ДС с действиями написать программу сканирования текста исходной программы.
ПримерСоставим ЛА для модельного языка М. Предварительно введем следующие обозначения для переменных, процедур и функций.
Переменные:
1) СН – очередной входной символ;
2) S - буфер для накапливания символов лексемы;
3) B – переменная для формирования числового значения константы;
4) CS - текущее состояние буфера накопления лексем с возможными значениями: Н - начало, I - идентификатор, N - число, С - комментарий, DV – двоеточие, О - ограничитель, V - выход, ER –ошибка;
5) t - таблица лексем анализируемой программы с возможными значениями: TW - таблица служебных слов М-языка, TL – таблица ограничителей М-языка, TI - таблица идентификаторов программы, TN – чисел, используемых в программе;
6) z - номер лексемы в таблице t (если лексемы в таблице нет, то z=0).
Процедуры и функции:
1) gc – процедура считывания очередного символа текста в переменную СН;
2) let – логическая функция, проверяющая, является ли переменная СН буквой;
3) digit - логическая функция, проверяющая, является ли переменная СН цифрой;
4) nill – процедура очистки буфера S;
5) add – процедура добавления очередного символа в конец буфера S;
6) look(t) – процедура поиска лексемы из буфера S в таблице t с возвращением номера лексемы в таблице;
7) put(t) – процедура записи лексемы из буфера S в таблицу t, если там не было этой лексемы, возвращает номер данной лексемы в таблице;
8) out(n, k) – процедура записи пары чисел (n, k) в файл лексем.

Рисунок 4.3 – Диаграмма состояний с действиями
для модельного языка М
4.4.3 Функция scanner
На основе построенной ДС с действиями для распознавания и формирования внутреннего представления лексем модельного языка М (рисунок 4.5.2) составляем функцию scanner для анализа текста исходной программы:
function scanner: boolean;
var CS: (H, I, N, C, DV, O, V, ER);
begin gc; CS:=H;
repeat
case CS of
H: if CH=’ ‘ then gc
else
if let then
begin
nill; add;
gc; CS:= I
end
else
if digit then
begin
B:=ord(CH)-ord(‘0’);
gc; CS:= N
end
else
if CH= ‘:’ then
begin
gc;
CS:= DV
end
else
if CH=’.’ then
begin
out(2,1);
CS:=V
end
else
if CH=’{‘ then
begin
gc; CS:=C
end
else CS:=O;
I: if let or digit then
begin
add; gc
end
else begin
look(TW);
if z<>0 then
begin
out(1,z); CS:=H
end
else begin
put(TI);
out(4,z);
CS:=H
end
end;
N: if digit then
begin
B:=10*B+ord(CH)-ord(‘0’);
gc
end
else begin
put(TN);
out(3,z); CS:=H
end;
C: if CH=’}’ then begin
gc; CS:=H
end
else if CH=’.’ then CS:=ER else gc;
DV: if CH=’=’ then begin
gc; out(2,5);
CS:=H
end
else begin
out(2,4); CS:=H
end;
O: begin
null; add; look(TL);
if z<>0 then begin
gc; out(2,z);
CS:=H
end
else CS:=ER
end
end {case}
until (CS=V) or (CS=ER);
scanner:= CS=V
end;
Дата добавления: 2016-03-27; просмотров: 1017;