Статический алгоритм Хафмана
Статический алгоритм Хафмана можно считать классическим.
Пусть сообщения m(1),…,m(n) имеют вероятности P(m(1)),… P(m(n)) и пусть для определенности они упорядочены так, что P(m(1)) і P(m(2)) і … і P(m(N)). Пусть x1,…, xn – совокупность двоичных кодов и пусть l1, l2,…, lN длины этих кодов. Задачей алгоритма является установление соответствия между m(i) и xj. Можно показать, что для любого ансамбля сообщений с полным числом более 2 существует двоичный код, в котором два наименее вероятных кода xN и xN-1 имеют одну и ту же длину и отличаются лишь последним символом: xN имеет последний бит 1, а xN-1 – 0. Редуцированный ансамбль будет иметь свои два наименее вероятные сообщения, сгруппированными вместе. После этого можно получить новый редуцированный ансамбль и так далее. Процедура может быть продолжена до тех пор, пока в очередном ансамбле не останется только два сообщения. Процедура реализации алгоритма сводится к следующему (см. рис. 2.). Сначала группируются два наименее вероятные сообщения, предпоследнему сообщению ставится в соответствие код с младшим битом, равным нулю, а последнему – код с единичным младшим битом (на рисунке m(4) и m(5)). Вероятности этих двух сообщений складываются, после чего ищутся два наименее вероятные сообщения во вновь полученном ансамбле (m(3) и m`(4); p(m`(4)) = p(m(4)) + P(m(5))).
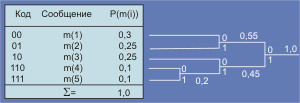
Рис. 2. Пример реализации алгоритма Хафмана
На следующем шаге наименее вероятными сообщениями окажутся m(1) и m(2). Кодовые слова на полученном дереве считываются справа налево. Алгоритм выдает оптимальный код (минимальная избыточность).
Но при использовании кодов разной длины могут возникнуть проблема разделение кодовых слов при последовательной пересылке. Например, пусть <(a,1); (b,01); (c,101); (d,011)>, тогда битовая последовательность 1011 может быть интерпретирована как aba, ca или ada. Чтобы избежать этой неопределенности можно посылать код длины перед каждым символом, что связано с пересылкой дополнительных данных. Более эффективным решением является конструирование кодов, в которых мы можем всегда однозначно преобразовать битовую последовательность в кодовое слово. Кодом такого типа является префиксный код, в котором никакая битовая строка не является префиксом другого кода. Например, <(a,1); (b.01);(c,000);(d,001)>. Префиксные коды имеют то преимущество перед другими кодами, что мы можем дешифровать любое сообщение без необходимости выявления начала следующего. Префиксный код может быть представлен в виде двоичного дерева:
· Каждое сообщение является листом дерева.
· Код каждого сообщения определяется движением от корня к листу, причем к коду добавляется 0 для ответвления влево и 1 – для ответвления вправо.
Такое дерево называется деревом префиксных кодов. Это дерево может использоваться и при декодировании префиксных кодов. При поступлении битов декодер может следовать вдоль дерева, пока не достигнет листа, формируя таким способом сообщение. После этого при поступлении очередного бита осуществляется возврат к корню дерева и процедура повторяется. При декодировании могут использоваться несколько префиксных деревьев.
При использовании кодирования по схеме Хафмана надо вместе с закодированным текстом передать соответствующий алфавит. При передаче больших фрагментов избыточность, сопряженная с этим не может быть значительной. Для одного и того же массива бит могут быть сформированы разные алфавиты, но они будут одинаково оптимальными (среднее число бит, приходящихся на один символ для любого такого алфавита, будет идентичным). Таким образом, коды Хафмана являются оптимальным (наиболее экономным), но не единственным решением.
Возможно применение стандартных алфавитов (кодовых таблиц) для пересылки английского, русского, французского и т.д. текстов, программных текстов на С++, Паскале и т.д. Кодирование при этом не будет оптимальным, но исключается статистическая обработка пересылаемых фрагментов и отпадает необходимость пересылки кодовых таблиц.
Ниже в таблице представлена таблица возможных кодов Хафмана для английского алфавита.
| Буква | Код Хафмана |
| E | |
| T | |
| A | |
| O | |
| N | |
| R | |
| I | |
| S | |
| H | |
| D | |
| L | |
| F | |
| C | |
| M | |
| U | |
| G | |
| Y | |
| P | |
| W | |
| B | |
| V | |
| K | |
| X | |
| J | |
| Q | |
| Z |
Ниже представлена аналогичная таблица для русского алфавита. В этой таблице коды букв Е и Ё идентичны, аналогичная сутуация с кодами Ь и Ъ. Следует также иметь в виду, что помимо букв определенные коды должны быть присвоены символам пунктуации, числам и некоторым специальным символам (1 2 3 4 5 6 7 8 9 0 . , : ; ! ? ... ' " ~ % # * + - = \ ( ) [ ] { } _).
| Буква | Относит. частота | Код Хафмана |
| – пробел | 0,175 | |
| O | 0,090 | |
| Е,Ё | 0,072 | |
| А | 0,062 | |
| И | 0,062 | |
| T | 0,053 | |
| Н | 0,053 | |
| C | 0,045 | |
| Р | 0,040 | |
| В | 0,038 | |
| Л | 0,035 | |
| К | 0,028 | |
| М | 0,026 | |
| Д | 0,025 | |
| П | 0,023 | |
| У | 0,021 | |
| Я | 0,018 | |
| Ы | 0,016 | |
| З | 0,016 | |
| Ь,Ъ | 0,014 | |
| Б | 0,014 | |
| Г | 0,013 | |
| Ч | 0,012 | |
| Й | 0,010 | |
| Х | 0,009 | |
| Ж | 0,007 | |
| Ш | 0,006 | |
| Ю | 0,006 | |
| Ц | 0,004 | |
| Щ | 0,003 | |
| Э | 0,003 | |
| Ф | 0,002 |
Возможная схема реализации алгоритма формирования кодов Хафмана для русского алфавита показана на рис. 3.
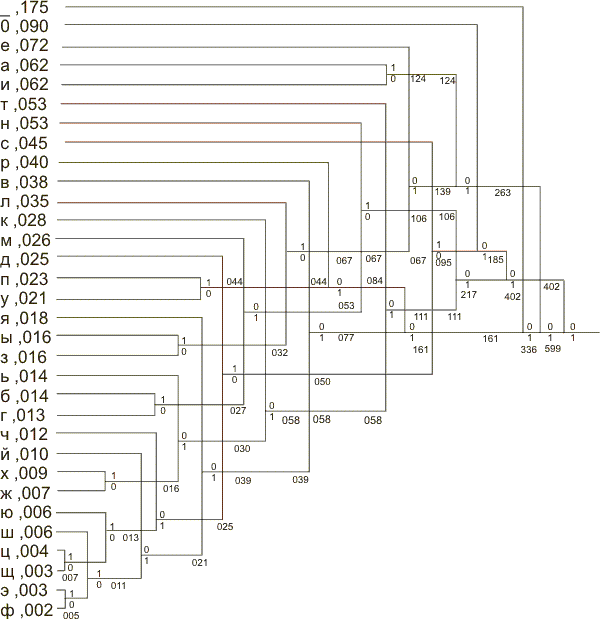
Рис. 3. Среднее число элементарных сигналов для передачи буквы при данном методе кодирования равно 4,4
Метод Шеннона-Фано
Данный метод выделяется своей простотой. Берутся исходные сообщения m(i) и их вероятности появления P(m(i)). Сообщения упорядываются так, чтобы вероятность i-го сообщения была не больше (i+1)-го. Этот список делится на две группы с примерно равной интегральной вероятностью. Каждому сообщению из группы 1 присваивается 0 в качестве первой цифры кода. Сообщениям из второй группы ставятся в соответствие коды, начинающиеся с 1. Каждая из этих групп делится на две аналогичным образом и добавляется еще одна цифра кода. Процесс продолжается до тех пор, пока не будут получены группы, содержащие лишь одно сообщение. Каждому сообщению в результате будет присвоен код x c длиной –lg(P(x)). Это справедливо, если возможно деление на подгруппы с совершенно равной суммарной вероятностью. Если же это невозможно, некоторые коды будут иметь длину –lg(P(x))+1. Алгоритм Шеннона-Фано не гарантирует оптимального кодирования.
Дата добавления: 2016-03-22; просмотров: 1006;