Методы сжатия информации
Методы сжатия данных имеют достаточно длинную историю развития, которая началась задолго до появления первого компьютера. В этой статье будет произведена попытка дать краткий обзор основных теорий, концепций идей и их реализаций, не претендующий, однако, на абсолютную полноту. Более подробные сведения можно найти, например, в Кричевский Р.Е. [1989], Рябко Б.Я. [1980], Witten I.H. [1987], Rissanen J. [1981], Huffman D.A.[1952], Gallager R.G. [1978], Knuth D.E. [1985], Vitter J.S. [1986] и др.
Сжатие информации - проблема, имеющая достаточно давнюю историю, гораздо более давнюю, нежели история развития вычислительной техники, которая (история) обычно шла параллельно с историей развития проблемы кодирования и шифровки информации. Все алгоритмы сжатия оперируют входным потоком информации, минимальной единицей которой является бит, а максимальной - несколько бит, байт или несколько байт. Целью процесса сжатия, как правило, есть получение более компактного выходного потока информационных единиц из некоторого изначально некомпактного входного потока при помощи некоторого их преобразования. Основными техническими характеристиками процессов сжатия и результатов их работы являются:
- степень сжатия (compress rating) или отношение (ratio) объемов исходного и результирующего потоков;
- скорость сжатия - время, затрачиваемое на сжатие некоторого объема информации входного потока, до получения из него эквивалентного выходного потока;
- качество сжатия - величина, показывающая на сколько сильно упакован выходной поток, при помощи применения к нему повторного сжатия по этому же или иному алгоритму.
Существует несколько различных подходов к проблеме сжатия информации. Одни имеют весьма сложную теоретическую математическую базу, другие основаны на свойствах информационного потока и алгоритмически достаточно просты. Любой способ подход и алгоритм, реализующий сжатие или компрессию данных, предназначен для снижения объема выходного потока информации в битах при помощи ее обратимого или необратимого преобразования.
Я рассмотрю методы сжатия без потери информации. К таким методам относятся:
· Алгоритм Хафмана
· Арифметическое кодирование
· Контекстное кодирование (PPM - Prediction by Partial Matching)
· Алгоритм Зива-Лемпеля(-Welch)
· Алгоритм Барроуза-Веллера
Полное число алгоритмов сжатия данных без потерь информации существенно более десяти.
Пропускная способность каналов связи более дорогостоящий ресурс, чем дисковое пространство, по этой причине сжатие данных до или во время их передачи еще более актуально. Здесь целью сжатия информации является экономия пропускной способности и в конечном итоге ее увеличение. Все известные алгоритмы сжатия сводятся к шифрованию входной информации, а принимающая сторона выполняет дешифровку принятых данных.
Существуют методы, которые предполагают некоторые потери исходных данных, другие алгоритмы позволяют преобразовать информацию без потерь. Сжатие с потерями используется при передаче звуковой или графической информации, при этом учитывается несовершенство органов слуха и зрения, которые не замечают некоторого ухудшения качества, связанного с этими потерями. Более детально эти методы рассмотрены в разделе "Преобразование, кодировка и передача информации".
Сжатие информации без потерь осуществляется статистическим кодированием или на основе предварительно созданного словаря. Статистические алгоритмы (напр., схема кодирования Хафмана) присваивают каждому входному символу определенный код. При этом наиболее часто используемому символу присваивается наиболее короткий код, а наиболее редкому - более длинный. Распределение частот отдельных букв английского алфавита показано на рис.1. Такое распределение может быть построено и для русского языка. Таблицы кодирования создаются заранее и имеют ограниченный размер. Этот алгоритм обеспечивает наибольшее быстродействие и наименьшие задержки. Для получения высоких коэффициентов сжатия статистический метод требует больших объемов памяти.
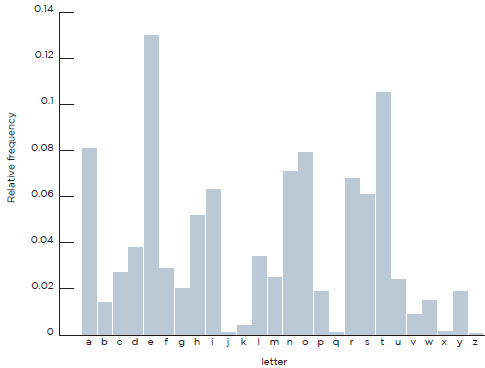
Рис. 1. Распределение английских букв по их частоте использования
Величина сжатия определяется избыточностью обрабатываемого массива бит. Каждый из естественных языков обладает определенной избыточностью. Среди европейских языков русский обладает одной из самых высоких уровней избыточности. Об этом можно судить по размерам русского перевода английского текста. Обычно он примерно на 30% больше.
Если речь идет о стихотворном тексте, избыточность может быть до двух раз выше.
В 1977 году Абрахам Лемпель и Якоб Зив предложили алгоритм сжатия данных, названный позднее LZ77. Этот алгоритм используется в программах архивирования текстов compress, lha, pkzip и arj. Модификация алгоритма LZ78 применяется для сжатия двоичных данных. Эти модификации алгоритма защищены патентами США. Алгоритм предполагает кодирование последовательности бит путем разбивки ее на фразы с последующим кодированием этих фраз. Суть алгоритма заключается в следующем.
Если в тексте встретится повторение строк символов, то повторные строки заменяются ссылками (указателями) на исходную строку. Ссылка имеет формат <префикс, расстояние, длина>. Префикс в этом случае равен 1. Поле расстояние идентифицирует слово в словаре строк. Если строки в словаре нет, генерируется код символ вида <префикс, символ>, где поле префикс = 0, а поле символ соответствует текущему символу исходного текста. Отсюда видно, что префикс служит для разделения кодов указателя от кодов символ. Введение кодов <символ> позволяет оптимизировать словарь и поднять эффективность сжатия. Главная алгоритмическая проблема здесь заключается в оптимальном выборе строк, так как это предполагает значительный объем переборов.
Альтернативой статистическому алгоритму стала схема сжатия, основанная на динамически изменяемом словаре (напр., алгоритмы Лембеля-Зива). Данный метод предполагает замену потока символов кодами, записанными в памяти в виде словаря (таблица перекодировки). Соотношение между символами и кодами меняется вместе с изменением данных. Таблицы кодирования периодически меняются, что делает метод более гибким. Размер небольших словарей лежит в пределах 2-32 килобайт, но более высоких коэффициентов сжатия можно достичь при заметно больших словарях до 400 килобайт.
Реализация алгоритма возможна в двух режимах: непрерывном и пакетном. Первый использует для создания и поддержки словаря непрерывный поток символов. При этом возможен многопротокольный режим (например, TCP/IP и DECnet). Словари сжатия и декомпрессии должны изменяться синхронно, а канал должен быть достаточно надежен (напр., X.25 или PPP), что гарантирует отсутствие искажения словаря при повреждении или потере пакета. При искажении одного из словарей оба ликвидируются и должны быть созданы вновь.
Пакетный режим сжатия также использует поток символов для создания и поддержания словаря, но поток здесь ограничен одним пакетом и по этой причине синхронизация словарей ограничена границами кадра. Для пакетного режима достаточно иметь словарь объемом, порядка 4 Кбайт. Непрерывный режим обеспечивает лучшие коэффициенты сжатия, но задержка получения информации (сумма времен сжатия и декомпрессии) при этом больше, чем в пакетном режиме.
При передаче пакетов иногда применяется сжатие заголовков, например, алгоритм Ван Якобсона (RFC-1144). Этот алгоритм используется при скоростях передачи менее 64 Kбит/с. При этом достижимо повышение пропускной способности на 50% для скорости передачи 4800 бит/с. Сжатие заголовков зависит от типа протокола. При передаче больших пакетов на сверх высоких скоростях по региональным сетям используются специальные канальные алгоритмы, независящие от рабочих протоколов. Канальные методы сжатия информации не могут использоваться для сетей, базирующихся на пакетной технологии, SMDS (Switched Multi-megabit Data Service), ATM, X.25 и Frame Relay. Канальные методы сжатия дают хорошие результаты при соединении по схеме точка-точка, а при использовании маршрутизаторов возникают проблемы - ведь нужно выполнять процедуры сжатия/декомпрессии в каждом маршрутизаторе, что заметно увеличивает суммарное время доставки информации. Возникает и проблема совместимости маршрутизаторов, которая может быть устранена процедурой идентификации при у становлении виртуального канала.
Иногда для сжатия информации используют аппаратные средства. Такие устройства должны располагаться как со стороны передатчика, так и со стороны приемника. Как правило, они дают хорошие коэффициенты сжатия и приемлемые задержки, но они применимы лишь при соединениях точка-точка. Такие устройства могут быть внешними или встроенными, появились и специальные интегральные схемы, решающие задачи сжатия/декомпрессии. На практике задача может решаться как аппаратно, так и программно, возможны и комбинированные решения.
Если при работе с пакетами заголовки оставлять неизмененными, а сжимать только информационные поля, ограничение на использование стандартных маршрутизаторов может быть снято. Пакеты будут доставляться конечному адресату, и только там будет выполняться процедура декомпрессии. Такая схема сжатия данных приемлема для сетей X.25, SMDS, Frame Relay и ATM. Маршрутизаторы корпорации CISCO поддерживают практически все режимы сжатия/декомпрессии информации, перечисленные выше.
Этой проблеме посвящено много книг, например, David Salomon, Giovanni Motta, "Handbook of Data Compression", Springer, или Khalid Sayood, "Introduction to data compression". Обе книги можно, по крайней мере частично, просмотреть через Интернет. За последние 15 лет эти технологии достаточно мало изменились.
Дата добавления: 2016-03-22; просмотров: 1989;