Исследование уравнений регрессии.
Для наблюденных пар {Xi, Yi} было построено уравнение регрессии 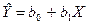 . В каждой точке Xi получено отклонение «предсказанного» значения
. В каждой точке Xi получено отклонение «предсказанного» значения 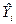 от наблюденного Yi: Это отклонение (остаток) можно представить в виде:
от наблюденного Yi: Это отклонение (остаток) можно представить в виде:
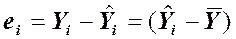 (1)
(1)
Уравнение (1) можно представить в виде.
 (2)
(2)
Возведя в квадрат обе части уравнения (2) и просуммировав все уравнения по i: i=1, ... , n, получим [2]
 (3)
(3)
В уравнении (3) сумма  является суммой квадратов отклонений зависимой переменной относительно среднего значения
является суммой квадратов отклонений зависимой переменной относительно среднего значения  .
.
Сумма 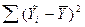 - представляет собой сумму квадратов отклонений предсказанных значений относительно среднего значения независимой переменной (сумма квадратов, обусловленная регрессией) и характеризует угол наклона линии регрессии.
- представляет собой сумму квадратов отклонений предсказанных значений относительно среднего значения независимой переменной (сумма квадратов, обусловленная регрессией) и характеризует угол наклона линии регрессии.
Сумма 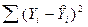 - сумма квадратов отклонений i - го наблюдения величины Y - oт ее предсказанного значения . Таким образом, уравнение (3) можно выразить следующим образом:
- сумма квадратов отклонений i - го наблюдения величины Y - oт ее предсказанного значения . Таким образом, уравнение (3) можно выразить следующим образом:
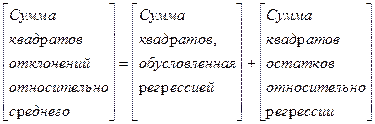
Качество построенной модели тем выше, чем больше сумма квадратов, обусловленная регрессией, превосходит сумму квадратов остатков относительно регрессии!
Так как сумма квадратов отклонений пропорциональна дисперсии случайной величины, то уравнение (3) называется основным уравнениемдисперсионного анализа.
В статистике исследуются средние квадраты остатков, которые получаются делением их суммы на число степеней свободы.
Под числом степеней свободы некоторой статистики понимается разность между числом наблюдений и числом параметров, определенных по этим наблюдениям [3].
Сумма квадратов отклонений относительно среднего имеет (n-1) степеней свободы [3]. С учетом выше изложенного строится таблица дисперсионного анализа.
| Источник вариации. | Число степеней свободы. | Суммы квадратов (SS). | Средний квадрат (MS). |
| Обусловленный регрессией. | 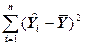
| MS рег.= 
| |
| Остаток относительно регрессии. | n -2 | 
| S= 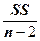
|
| Общий | n - 1 | 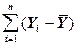
|
Если наблюдения независимые, а их погрешности подчиняются нормальному распределению, то отношение 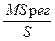 подчиняется F - распределению с числом степеней свободы g1 =1, g2 =n - 2
подчиняется F - распределению с числом степеней свободы g1 =1, g2 =n - 2
Задавая уровень значимости a, и сравнивая Fвыч.= 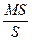 с табличным значением F - распределения, можно проверить гипотезу о значимости отличия MSрег от S (При этом вероятность ошибки будет равна a. В ППП «STATISTICA» уровень вероятностей ошибки -P выводится на экран). 100×(1-a)%-е доверительные интервалы для коэффициентов b0 и b1 определяются выражением [2]:
с табличным значением F - распределения, можно проверить гипотезу о значимости отличия MSрег от S (При этом вероятность ошибки будет равна a. В ППП «STATISTICA» уровень вероятностей ошибки -P выводится на экран). 100×(1-a)%-е доверительные интервалы для коэффициентов b0 и b1 определяются выражением [2]:
b0: 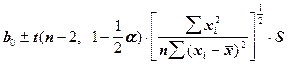 (3)
(3)
b1: 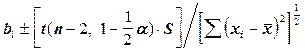 (4)
(4)
где S - средний остаток относительно регрессии (остаточная дисперсия). Для проверки гипотезы о равенстве параметра b0 некоторой заданной величине b00 (H0: b0=b00) вычисляется величина t
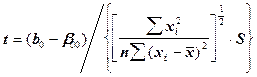 (4)
(4)
Вычисленное значение t сравнивается с табличным 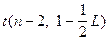 . Если t вычисл. < t таблич., гипотеза H0 принимается.
. Если t вычисл. < t таблич., гипотеза H0 принимается.
Для проверки гипотезы о равенстве параметра b1 некоторой величине b10 вычисляется статистика
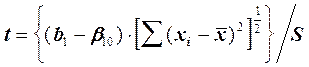 (5)
(5)
и сравнивается с табличным значением 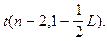
Решение о принятии гипотезы H0: b1=b10 принимается при t выч.< t табл.
Оценка стандартного отклонения вычисленного значения 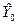 (при X=X0) равна [3]
(при X=X0) равна [3]
СКО 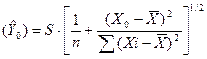 (6)
(6)
Доверительные интервалы для с доверительной вероятностью P=1-a определяются выражением
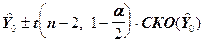 (7)
(7)
Дата добавления: 2016-02-20; просмотров: 844;