Количественный анализ диаграмм
Для проведения количественного анализа диаграмм перечислим показатели модели:
- количество блоков на диаграмме – N;
- уровень декомпозиции диаграммы – L;
- сбалансированность диаграммы – В;
- число стрелок, соединяющихся с блоком, – А.
Данный набор факторов относится к каждой диаграмме модели. Далее будут перечислены рекомендации по желательным значениям факторов диаграммы.
Необходимо стремиться к тому, чтобы количество блоков на диаграммах нижних уровней было бы ниже количества блоков на родительских диаграммах, т.е. с увеличением уровня декомпозиции убывал бы коэффициент 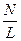 . Таким образом, убывание этого коэффициента говорит о том, что по мере декомпозиции модели функции должны упрощаться, следовательно, количество блоков должно убывать.
. Таким образом, убывание этого коэффициента говорит о том, что по мере декомпозиции модели функции должны упрощаться, следовательно, количество блоков должно убывать.
Диаграммы дол лены быть сбалансированы. Это означает, что в рамках одной диаграммы не должно происходить ситуации, изображенной на рис. 14: у работы 1 входящих стрелок и стрелок управления значительно больше, чем выходящих. Следует отметить, что данная рекомендация может не выполняться в моделях, описывающих производственные процессы. Например, при описании процедуры сборки в блок может входить множество стрелок, описывающих компоненты изделия, а выходить одна стрелка – готовое изделие.

Рис. 14. Пример несбалансированной диаграммы
Введем коэффициент сбалансированности диаграммы:
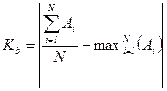 .
.
Необходимо стремиться, чтобы Кb, был минимален для диаграммы.
Помимо анализа графических элементов диаграммы необходимо рассматривать наименования блоков. Для оценки имен составляется словарь элементарных (тривиальных) функций моделируемой системы. Фактически в данный словарь должны попасть функции нижнего, уровня декомпозиции диаграмм. Например, для модели БД элементарными могут являться функции «найти запись», «добавить запись в БД», в то время как функция «регистрация пользователя» требует дальнейшего описания.
После формирования словаря и составления пакета диаграмм системы необходимо рассмотреть нижний уровень модели. Если на нем обнаружатся совпадения названий блоков диаграмм и слов из словаря, то это говорит, что достаточный уровень декомпозиции достигнут. Коэффициент, количественно отражающий данный критерий, можно записать как L*C – произведение уровня модели на число совпадений имен блоков со словами из словаря. Чем ниже уровень модели (больше L), тем ценнее совпадения.
Методология DFD
В основе методологии DFD лежит построение модели анализируемой АИС – проектируемой или реально существующей. Основным средством моделирования функциональных требований проектируемой системы являются диаграммы потоков данных (DFD). В соответствии с данной методологией модель системы определяется как иерархия диаграмм потоков данных. С их помощью требования разбиваются на функциональные компоненты (процессы) и представляются в виде сети, связанной потоками данных. Главная цель таких средств – продемонстрировать, как каждый процесс преобразует свои входные данные в выходные, а также выявить отношения между этими процессами.
Компонентами модели являются:
- диаграммы;
- словари данных;
- спецификации процессов.
DFD-диаграммы
Диаграммы потоков данных (DFD – Data Flow Diagrams) используются для описания документооборота и обработки информации. DFD представляет модельную систему как сеть связанных между собой работ, которые можно использовать для более наглядного отображения текущих операций документооборота в корпоративных системах обработки информации.
DFD описывает:
- функции обработки информации (работы, activities);
- документы (стрелки, arrows), объекты, сотрудников или отделы, которые участвуют в обработке информации;
- внешние ссылки (external references), которые обеспечивают интерфейс с внешними объектами, находящимися за границами моделируемой системы;
- таблицы для хранения документов (хранилище данных, data store).
В BPwin для построения диаграмм потоков данных используется нотация Гейна-Сарсона (табл. 4).
Нотация Гейна – Сарсона
Таблица 4
| Компонент | Обозначение | ||
| Поток данных | 
| ||
| Процесс | 
| ||
| Хранилище | 
| ||
| Внешняя сущность |
| ||
| Система | 
|
На диаграммах функциональные требованияпредставляются с помощью процессов и хранилищ, связанных потоком данных.
Внешняя сущность– материальный предмет или физическое лицо, т.е. сущность вне контекста системы, являющуюся источником или приемником системных данных (например, заказчик, персонал, поставщики, клиенты, склад и др.). Ее имя должно содержать существительное. Предполагается, что объекты, представленные такими узлами, не должны участвовать ни в какой обработке.
Система и подсистема при построении модели сложной ИС она может быть представлена в самом общем виде на контекстной диаграмме в виде одной системы как единого целого, либо может быть декомпозирована на ряд подсистем. Номер подсистемы служит для ее идентификации. В поле имени вводится наименование системы в виде предложения с подлежащим и соответствующими определениями и дополнениями.
Процессыпредназначены для продуцирования выходных потоков из входных в соответствии с действием, задаваемым именем процесса. Это имя должно содержать глагол в неопределенной форме с последующим дополнением (например, вычислить, проверить, создать, получить). Номер процесса служит для его идентификации, а также для ссылок на него внутри диаграммы. Этот номер может использоваться совместно с номером диаграммы для получения уникального индекса процесса во всей модели.
Потоки данных– механизмы, использующиеся для моделирования передачи информации из одной части системы в другую. Потоки на диаграммах изображаются именованными стрелками, ориентация которых указывает направление движения информации. Иногда информация может двигаться в одном направлении, обрабатываться и возвращаться назад в ее источник. Такая ситуация может моделироваться либо двумя различными потоками, либо одним - двунаправленным.
Хранилище (накопитель данных) данныхпозволяет на определенных участках определять данные, которые будут сохраняться в памяти между процессами. Информация, которую оно содержит, может использоваться в любое время после ее определения, при этом данные могут выбираться в любом порядке. Имя хранилища должно идентифицировать его содержимое и быть существительным. Накопитель данных является прообразом будущей базы данных и описание хранящихся в нем данных должно быть увязано с информационной моделью.
 Для того чтобы дополнить модель IDEF0 диаграммой DFD, нужно в процессе декомпозиции в диалоге Activity Box Count (рис. 15) выбрать радиокнопку DFD.
Для того чтобы дополнить модель IDEF0 диаграммой DFD, нужно в процессе декомпозиции в диалоге Activity Box Count (рис. 15) выбрать радиокнопку DFD.
Рис. 15
В палитре инструментов на новой диаграмме появляются кнопки:
 - добавить в диаграмму внешнюю ссылку. Внешняя ссылка является источником или приемником данных извне модели;
- добавить в диаграмму внешнюю ссылку. Внешняя ссылка является источником или приемником данных извне модели;
 - добавить в диаграмму хранилище данных. Хранилище данных позволяет описать данные, которые необходимо сохранить в памяти прежде, чем использовать в работах;
- добавить в диаграмму хранилище данных. Хранилище данных позволяет описать данные, которые необходимо сохранить в памяти прежде, чем использовать в работах;
 - ссылка на другую страницу. В отличие от IDEF0 инструмент off-page reference позволяет направить стрелку на любую диаграмму (а не только на верхний уровень).
- ссылка на другую страницу. В отличие от IDEF0 инструмент off-page reference позволяет направить стрелку на любую диаграмму (а не только на верхний уровень).
Дата добавления: 2016-01-07; просмотров: 3335;