Информация в Internet
В Интернете используется множество различных форматов данных. Некоторые из них используются довольно часто, некоторые реже. Как же связать это бесчисленное множество различных форматов с теорией информации? Данная лекция дает ответы на эти и другие вопросы. Дается понятие сущности компьютерного шрифта, текстов с разметкой и их применение, язык логической разметки HTML. TeX как язык программирования в академических кругах. Также рассматривается формат PDF как самый популярный формат создания, хранения и передачи электронных книг
Самый распространенный тип данных в компьютерном мире - это текстовые файлы, которые непосредственно в той или иной мере понятны для человека, в отличие от бинарных файлов, ориентированных исключительно на компьютерные методы обработки. С использованием текстовых файлов связаны две проблемы.
Первая заключается в сложности единообразного представления символов текста. Для представления английских текстов достаточно ASCII. Для работы с другими языками на основе латинского алфавита, языками на основе кириллицы и некоторыми другими нужно уже несколько десятков наборов расширенного ASCII. Это означает, что одному и тому же коду, большему 127, в каждом наборе соответствует свой символ. Ситуацию усложняет и то, что для некоторых языков, в частности, русского существует несколько наборов ASCII+. Кроме того, необходимо, чтобы все символы каждого языка помещались в один набор, что невозможно для таких языков, как китайский или японский. Таблица кодировки Unicode, предназначенная для постепенной замены ASCII, - 16-разрядная, что позволяет представить 65536 кодов. Она широко используется в Linux и Microsoft Windows. Варианты Unicode позволяют использовать 31-разрядное кодирование. Использование Unicode требует переделки всех программ, рассчитанных для работы с текстами ASCII.
Для того, чтобы увидеть символы, соответствующие кодам из текстового файла, каждому коду нужно сопоставить визуальное представление символа из выбранного шрифта.
Компьютерный шрифт - это набор именованных кодами рисунков знаков.
Таким образом, чтобы интерактивно работать с текстовым файлом необходимо знать его кодировку (из текстовых файлов, как правило, прямой информации о кодировке получить нельзя - ее надо знать или угадать!) и иметь в системе шрифт, соответствующий этой кодировке.
Вторая проблема связана с тем, что такие средства как курсивный, полужирный или подчеркнутый текст, а также графики, диаграммы, примечания, звук, видео и т.п. элементы электронных документов, выходят за рамки естественных, интуитивных элементов текста и требуют соглашений по их использованию, что приводит к возникновению различных форматов текстовых данных. Последние иногда даже не ориентированы на непосредственную работу с ними человека, фактически не отличаясь по назначению в таких случаях, от бинарных данных.
Внесение в простой текст (plain text) дополнительной информации об его оформлении или структуре осуществляется при помощи разметки текста (markup). Различают физическую или процедурную разметку и логическую или обобщенную разметку.
При физической разметке точно указывается, что нужно сделать с выбранным фрагментом текста: показать курсивным, приподнять, центрировать, сжать, подчеркнуть и т.п. При логической разметке указывается структурный смысл выбранного фрагмента: примечание, начало раздела, конец подраздела, ссылка на другой фрагмент и т.п.
Для печати документа на принтере или показе на экране используется физическая разметка. Исторически она появилась первой, но имеет очевидные недостатки. Например, в Америке и Европе существуют разные стандарты на размер писчей бумаги, наборы шрифтов и размер экрана меняются от системы к системе, - подобные обстоятельства требуют трудоемкого изменения физической разметки текста при использовании одного и того же документа на разных компьютерах. Кроме того, физическая разметка, как правило, привязана к конкретным программным средствам, время жизни которых ограничено, что не позволяет вести архивы документации без риска через несколько десятков лет остаться без средств для работы с ними.
Логическую разметку всегда можно преобразовать в физическую, используя таблицу стилей, которая представляет собойперечисление способов отображения каждого логического элемента. Таким образом, имея наборы документов в логической разметке можно всегда при печати придавать им наиболее привлекательный вид, своевременно получая от специалистов-дизайнеров новейшие таблицы стилей. Преобразование физической разметки в логическую формальными средствами практически невозможно.
Основные форматы текста с разметкой:
1. HTML - Hyper Text Markup Language, язык разметки гипертекста;
2. XML - eXtensible Markup Language, расширяемый язык разметки;
3. SGML - Standard Generalized Markup Language, стандартный язык обобщенной разметки;
4. TeX;
5. PostScript;
6. PDF - Portable Document Format, формат для переносимых документов, или Acrobat (частично бинарный).
Документы в Internet часто публикуются в обработанном программами сжатия данных виде. Наиболее используемые форматы сжатия - это zip и tgz (tar.gz). Формат tgz - это результат конвейерного применения команд: сначала tar (собирает файлы и каталоги в один файл с сохранением структуры каталогов) и затем gzip.
Часто в Internet нужно преобразовывать бинарные данные в текстовые (для отправке по электронной почте, например) и затем наоборот. Для этого, в частности, служат программы uuencode (перевести в текст) и uudecode (перевести из текста). В текстовом файле закодированный текстом бинарный файл помещается между строками, начинающимся со слов begin и end. Строка begin должна содержать атрибуты и имя бинарного файла.
HTML, XML и SGML
World Wide Web (WWW, всемирная паутина) базируется на трех стандартах: URI (Universal Resource Identifier, универсальныйидентификатор ресурса, раньше назывался URL) - предоставляет стандартный способ задания местоположения любого ресурсаInternet, HTTP (Hyper Text Transfer Protocol, протокол передачи гипертекста), HTML - язык страниц WWW.
HTML - язык логической разметки, хотя и допускающий возможность рекомендовать ту или иную физическую разметку выбранного фрагмента текста. Конкретная физическая разметка документа зависит от программы-браузера (browser), используемой для его просмотра. Документы HTML из-за содержащихся в них, как правило, большого количества ссылок на другие документы HTML, с которыми они образуют единое целое, мало приспособлены для распечатки на принтере.
Имя файла с документом HTML имеет обычно расширение html или htm. Существуют ряд программ, позволяющих создавать документы HTML в визуальном режиме и не требующих от их пользователя знания HTML. Но создать сложный интерактивный документ без такого знания непросто.
Элементы разметки HTML состоят из тегов (tag). Теги заключаются в угловые скобки, у них, как правило, есть имя и они могут иметь дополнительные атрибуты. Например, тег <A HREF="http://www.linux.org"> имеет имя A (anchor, якорь), атрибутHREF со значением "http://www.linux.org".
Некоторые теги самодостаточны, например, тег разрыва строки <BR> (break), но большинство тегов - это пары из открывающего(start tag) и закрывающего (end tag) тегов. Имя закрывающего тега отличается от имени открывающего только тем, что перед ним ставится наклонная черта (slash). Например, если имя открывающего тега A, то имя закрывающего - /A. Открывающий и закрывающий теги обрамляют некоторый фрагмент текста, вместе с которым они образуют элемент текста. Элементы текста могут быть вложенными.
Парные теги EM (emphasis, выделение), STRONG (особо выделить), CITE (цитата или ссылка), CODE (компьютернаяпрограмма), SAMP (sample, текст примера), STRIKE (зачеркнуть) и некоторые другие позволяют логически выделить фрагменты текста, а парные теги B (bold, полужирный), I (italic, курсив), U (undelined, подчеркнутый), TT (typewriter, пишущая машинка), SUB (subscript, нижний индекс), SUP (superscript, верхний индекс) и другие - рекомендовать физически выделить фрагмент текста указанным образом.
Полный документ представляет собой один элемент текста HTML. Заголовки - это элементы H1, H2, H3 и т.д. Число после H(header) - это уровень вложенности заголовка, т.е. H1 - это заголовок всего документа, H2 - заголовок раздела документа, H3- подраздела и т.д. Абзацы - это элементы P (paragraph). Элементы PRE (preformatted) должны отображаться браузером с таким же разбиением на строки как и в исходном документе.
Специальные символы можно ввести в документ, используя их имена (entity), заключенные между знаками & и точка с запятой. Например, сам знак & можно ввести как &, а знак кавычка - ".
Ссылки и маркеры, объявляются при помощи атрибутов HREF и NAME соответственно. Например, элемент <A NAME="chapter3"></A> - это метка, на которую можно ссылаться по имени chapter3, используя, например, ссылку <A HREF="\#chapter3">Глава 3</A>.
Тег IMG (image, образ) позволяет вставить графическую картинку в документ, используя два основных атрибута: SRC (source, источник) для указания URI файла с графикой и ALT (alternative, альтернатива) для указания альтернативного текста, показываемого вместо картинки, в случае, когда файл с графикой недоступен или его тип неизвестен браузеру.
Документы HTML могут быть использованы для интерактивной работы. Например, элемент FORM позволяет пользователю web-страницы передать введенную в страницу информацию на HTTP-сервер. Элемент FORM может содержать разнообразные кнопки, списки, всплывающие меню, однострочные и многострочные текстовые поля и другие компоненты. Обработкой введенных, переданных на сервер данных и созданием динамических HTML-документов в ответ на них занимаются специальные программы,CGI-скрипты (common gate interface), установленные на сервере.
Комментарии вводятся между символами <!-{}- и -{}->.
HTML содержит средства для описания данных в виде таблиц и использования таблиц стилей. HTML использует стандартныесистемные шрифты, т.е. не существует шрифтов специально для www-страниц.
Имена файлов-документов SGML, как правило, имеют расширение sgml. SGML с начала 1970-х разрабатывался фирмой IBM, а с 1986 года принят в качестве международного стандарта (ISO 8879) для формата документов с логической разметкой. Сначала документ SGML содержит описание вида кодирования и разметки текста и затем сам размеченный текст. HTML - это SGML с фиксированной разметкой. Создатели технологии WWW отказались от полной поддержки SGML только потому, что в начале 1990-х системы, которые могли работать с SGML в реальном времени были очень дороги.
Элементы SGML делятся на четыре категории:
1. описательные маркеры - определяют структуру документа - им соответствуют элементы разметки HTML типа H1, P, A,IMG и т.п.;
2. ссылки на данные - им соответствуют элементы разметки HTML типа &
3. описательные конструкции компонент документа в их структурной взаимосвязи - они не входят в HTML, но определяют его. Их рекомендуется начинать с комбинации знаков <! и заканчивать знаком >>. Примером конструкции, определяющей ссылку &ref; на словосочетание "The Reference" будет <!ENTITY ref "The Reference"> ;
4. инструкции по обработки текста - их рекомендуется заключать между знаками <? и > - они вводят элементы текста, ориентированного на конкретную, зависящую от системы обработку (физическую разметку). В HTML с их помощью, например, вставляют код для обработки на сервере WWW страниц.
Документы SGML можно конвертировать как в гипертекст, так и в любой формат, ориентированный на распечатку, например, TeX или Microsoft Word. Ведение документации в формате SGML во многих отношениях оптимально.
С 1996 официально идет разработка формата XML - подмножества SGML, которое предполагается использовать в Internet наряду сHTML. Преимущество XML перед HTML в его четкой связи с SGML, что позволяет стандартным образом вводить в документ новые конструкции, избегая тем самым неконтролируемого введения в язык новых возможностей, как это происходит с HTML.
Упражнение 53 Как на HTML описать заголовок первого уровня "Глава 2", на который можно будет ссылаться по имени "2"?
TeX
Известный американский математик и теоретик программирования Дональд Кнут (D. E. Knuth) более 10 лет с конца 1970-х годов разрабатывал систему верстки книг TeX (произносится "тех"). Существует множество расширений возможностей базового (plain) TeX. TeX популярен прежде всего в академических кругах, т.к. в целом он весьма сложен для изучения. В отличие от систем, ориентированных на интерпретацию разметки, подобных Microsoft Word или Sun Star Writer, TeX - компилирующая система. Результат компиляции документа TeX - это файл в бинарном формате dvi (device independent), который можно, используя драйверы конкретных устройств (принтеров, экрана), распечатать. TeX использует собственную систему масштабируемых шрифтов, которые масштабируются не в реальном времени, интерпретацией как шрифты True Type или PostScript, а компиляцией при помощи программы METAFONT. В Internet доступны тексты программ TeX и METAFONT - они написаны на Паскале. Шрифты METAFONT написаны на специальном языке, с декларативным синтаксисом. TeX позволяет также использовать шрифты True Type и Adobe Type 1 и Type 3. Прочитать и понять содержимое документа TeX несложно, но скомпилировать и распечатать, а тем более создать новый документ без помощи специалиста или основательной подготовки непросто. Однако TeX до сих пор является почти единственной доступной бесплатно системой, позволяющей получать документы типографского качества. В plain TeX используется физическая разметка, а в наиболее популярном его расширении LaTeX также и логическая. TeX - это язык макросов, большинство из которых начинаются с символа обратная косая черта и состоят затем из букв. Например, запись в документе plain TeX \centerline{Это {\ it мой} заголовок} означает центрировать строку-абзац "Это мой заголовок", напечатав слово "мой" в нем курсивом, а запись $$\int_1^{}x\{dt\ over t}=\ln x$$ - формулу
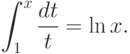
TeX - это особый язык программирования. Энтузиасты TeX написали на нем интерпретатор языка Бэйсик. Документы TeX могут иметь очень сложную структуру и из-за этого их в общем случае нельзя конвертировать в другие форматы. Документы HTML или Microsoft Word теоретически можно всегда конвертировать в формат TeX.
Система GNU texinfo основана на TeX, но использует совершенно другой набор макросов. Макросы в этой системе должны начинаться со знака @. Документы texinfo можно преобразовать как в документ HTML, так и в качественную распечатку. В отличие от SGML, средства для такого преобразования - это часть системы texinfo. Возможности texinfo для верстки документов несколько ограниченней по сравнению с другими развитыми TeX-системами.
Расширения имен файлов документов TeX - tex; LaTeX - tex, latex, ltx, sty (стили) и др.; METAFONT - mf (исходные программы шрифтов), tfm (метрики шрифтов, нужны на этапе компиляции документа TeX), pk (матрицы шрифтов, нужны при печати dvi-файла); texinfo - texi, texinfo.
PostScript и PDF
PostScript - это универсальный язык программирования (имеет много общего с языками Форт и Лисп), предоставляющий большой набор команд для работы с графикой и шрифтами. Он является фактическим международным стандартом издательских систем. Разрабатывается фирмой Adobe Systems с первой половины 1980-х. Используется, как встроенный язык принтеров для высококачественной печати, а также некоторыми системами X Window при выводе данных на экран дисплея. Существуют и программы-интерпретаторы языка PostScript. Лучшая из них - это Ghostscript. Программа GhostView предоставляет удобныйоконный интерфейс для Ghostscript и существует для большинства ОС.
PostScript-программы можно писать вручную, но обычно текст PostScript генерируется автоматически программами вывода данных. Расширения имен файлов с PostScript-программой - это, как правило, ps, eps (Encapsulated PostScript, файл-картинка с заданными размерами), pfa (шрифт), pfb (бинарное представление pfa), afm (метрики шрифта, могут быть частично получены из соответствующего pfa-файла), pfm (бинарное представление afm).
Преимущество формата PostScript в том, что он, как и формат DVI, независим от физических устройств воспроизведения. Один и тот же PostScript-файл можно выводить как на экран с разрешением 72 dpi (dot per inch, точек на дюйм) или лазерный принтер с разрешением 600 dpi, так и на типографскую аппаратуру с разрешением 2400 dpi, имея гарантии, что изображение будет наилучшего качества, возможного на выбранной аппаратуре. Возможности PostScript перекрывают возможности DVI, поэтому некоторые TeX-системы при компиляции документов производят сразу файлы в формате PostScript или PDF.
Файлы PostScript можно вручную корректировать, но из-за сложности языка - это очень не просто, особенно если используются символы, не входящие в ASCII. Фактически эти файлы можно рассматривать как "только для чтения" и использовать для распространения информации, не подлежащей изменению. Комментарии в PostScript, как и в TeX, начинаются знаком % и заканчиваются концом строки. Первая строчка PostScript-программы обычно содержит точное название формата файла. Собственно программа начинается в файле с символов %! и заканчивается символами %%EOF. PostScript-программы кроме собственной системы шрифтов могут использовать шрифты True Type фирм Apple и Microsoft.
Различают уровни (levels) языка PostScript. Уровень 1 может поддерживать только черно-белую графику. Уровень 2 может работать с цветом. Уровень 3 - это современное состояние языка.
Данные из файла PostScript можно показывать по мере их поступления, что удобно для использования в Internet. Однако есть две причины, по которым документы PostScript сравнительно редко включаются в web-страницы:
1. они весьма велики по размерам (этот недостаток снимается программами сжатия, работающими в реальном времени);
2. они могут содержать в себе шрифты, защищенные авторскими правами (шрифты их владелец может использовать при печати, но не распространять).
Файлы в формате PDF лишены двух означенных недостатков: они сжаты и из них сложно извлечь отдельные шрифты, - поэтому они стали фактическим стандартом Internet для обмена документами, не подлежащими изменению. Программы для просмотраPDF-файлов доступны бесплатно. Наиболее используемая из них - это Adobe Acrobat Reader. Первая строчка файла в формате PDFначинается со знака %, за которым следует идентификационная запись версии формата PDF, используемой в этом файле. Далее, как правило, идут бинарные данные. Расширение имени PDF-файла - pdf.
Между документами PostScript и PDF можно осуществлять взаимно-однозначное преобразование, хотя PDF в отличие от PostScript - это не язык программирования, а скорее язык описания документа.
Дата добавления: 2015-12-26; просмотров: 833;