Обоснование и расчет выборки
Основные понятия теории выборки.Специфические требования к ОСИ – быстрота, конкретность, достоверность – порождают также особые требования к выборке исследования. Она должна быть репрезентативной (представительной), но в то же время эффективной, то есть позволяющей получить достоверную информацию быстро и относительно недорого.
Главным фактором, влияющим на репрезентативность и эффективность выборки, является способ ее формирования, который зависит от определения объекта исследования. Являясь атрибутом системы социального управления, ОСИ может иметь своим объектом некоторый коллектив (в широком смысле слова – от отрасли производства до клуба по интересам), социальную группу (например, молодежь, аудиторию телевизионного канала, электорат кандидата в депутаты, читателей библиотеки), либо население, проживающее на определенной территории (населенного пункта, района, области, государства). Каждый такой объект исследования представляет собой совокупность более мелких объектов – отдельных людей, семей, иногда академических групп или трудовых коллективов и т.п., – являющихся непосредственными источниками социологической информации. Полная совокупность объектов, имеющих отношение к изучаемой проблеме, называется генеральной совокупностью (ГС), а составляющие ее объекты – единицами или элементами ГС.
Процедура формирования выборки зависит от свойств ГС. Различают конкретные и гипотетические, конечные и бесконечные ГС. ГС является конкретной, если все ее элементы известны или могут быть легко определены, например, студенты одного или нескольких ВУЗов, жители дóма или небольшого населенного пункта, члены общественного объединения. ГС называется гипотетической, если принадлежность к ней неочевидна и для определения, принадлежит ли ей данный объект, требуется затратить определенные усилия. К гипотетическим ГС относятся, например, зрители телеканалов, читатели периодических изданий, избиратели (поскольку невозможно определить, является ли человек избирателем, до тех пор, пока он не явился на избирательный участок и не получил бюллетень) и др.
Деление ГС на конечные и бесконечные достаточно условное, оно связано с процедурами определения ошибки выборки. Конечными могут считаться ГС, насчитывающие до нескольких сотен тысяч элементов. ГС, насчитывающие очень большое количество объектов, несопоставимое с объемом выборки, рассматриваются как практически бесконечные.
И конкретные, и гипотетические ГС могут быть как конечными, так и бесконечными. Например, ГС узбеков, постоянно проживающих в Беларуси, является конечной, поскольку их количество известно достаточно точно (из результатов переписи населения) и не превышает нескольких десятков человек, но гипотетической, т.к. найти и опросить этих людей довольно сложно. ГС пенсионеров является конкретной, поскольку все они получают пенсию и, следовательно, зарегистрированы в соответствующих государственных службах, и практически бесконечной, т.к. количество пенсионеров в Беларуси составляет несколько миллионов.
Обычно предполагается, что выборка извлекается из всей ГС и поэтому может представлять ее в целом. Это в полной мере справедливо для тех выборочных процедур, которые используют более или менее полный список элементов ГС или ее структурных частей. Такой список называется основой выборки. В идеале, основа выборки должна полностью совпадать с генеральной совокупностью, однако достичь такого совпадения на практике удается лишь в отдельных случаях, для конкретных и относительно небольших ГС. Конкретными обычно являются ГС, выделяемые по месту жительства или работы (учебы, членства в общественных организациях и т.п.); они называются, соответственно, территориальными или производственными. Примерами основы территориальной выборки являются списки избирателей, оставшиеся от предшествующих выборов или предварительно составленные для очередных выборов, картотеки адресных столов, домовые книги ЖЭСов. В качестве основы производственной выборки могут использоваться картотеки отделов кадров, списки членов общественных организаций и объединений и т.п. Эти источники информации считаются достаточно, хотя и не абсолютно, точными.
Получить репрезентативную основу выборки для гипотетической ГС намного сложнее, а иногда не удается вообще. Успех в значительной мере зависит от характера ГС, критериев ее выделения, объема, компактности и т.п. Например, для аудитории канала кабельного телевидения список абонентов может стать удовлетворительной основой выборки, в то время как при использовании списков подписчиков газеты остается неохваченной значительная часть читателей, покупающих газету в киосках или на улице. Зрителями национального телеканала может, с некоторой натяжкой, считаться все население, и основу выборки для такой ГС можно составлять по территориальному принципу. Однако слушателями радио являются далеко не все, проживающие или находящиеся в сфере действия радиотранслятора. Список членов армянского культурного общества стал удачной основой выборки при исследовании армянской диаспоры в Минске благодаря высокой степени ее сплоченности. Однако такой подход совершенно неприменим для исследования русской или украинской диаспор. Учащуюся молодежь легко опрашивать по месту учебы, с использованием “производственной” основы выборки. Значительно сложнее получить репрезентативную основу выборки для молодежи, работающей в официальных структурах (в силу их различной ведомственной принадлежности и многочисленности), или для безработной молодежи (поскольку наиболее активная часть этой категории населения не регистрируется в службах занятости), не говоря уже о занятых в “серой” и “теневой” экономике.
Многие выборочные процедуры предполагают предварительное составление списка объектов, которые следует обследовать или опросить. Такой список называется целевой выборкой. Множество объектов, реально обследованных в ходе исследования, называется реальной или достигнутой выборкой. Поскольку в качестве объектов изучения в ОСИ чаще всего выступают люди, достигнутая выборка редко полностью совпадает с целевой, а чаще представляет собой некоторое ее подмножество, т.к. не все, кто включен в целевую выборку, оказываются в равной степени доступными для исследования и не все проявляют готовность участвовать в нем.
Мнение нереализованной части целевой выборки может существенно отличаться от мнения опрошенной ее части, так как доступность и готовность участвовать в опросе обычно неодинакова не только для отдельных людей, но и для целых социальных групп. Поэтому для того, чтобы результаты выборочного исследования могли быть обобщены на генеральную совокупность, необходимо, как минимум, оценить, отличается ли мнение нереализованной части целевой выборки и мнение опрошенной ее части. Для этого рекомендуется отобрать из достигнутой выборки респондентов, социально-демографические характеристики которых соответствовали бы характеристикам неопрошенной части целевой выборки, и сравнить их ответы с ответами всех остальных. Если различия несущественны, можно считать, что “недобор” респондентов не повлиял на репрезентативность выборки. Если различия значительны, необходимо компенсировать возникшие диспропорции.
Существуют две основные стратегии, позволяющие исправить диспропорции в структуре реально достигнутой выборки. Первая из них, называемая ремонтом выборки, состоит просто в дополнительном опросе (“доборе”) респондентов с нужными характеристиками. Эту стратегию традиционно применяют в отечественной социологии, однако в последние годы она неоднократно критиковалась с точки зрения качества окончательных результатов исследования. Вторая стратегия, называемая перевзвешиванием выборки, заключается в том, чтобы компенсировать возникшие диспропорции с помощью специально подобранных весовых коэффициентов, учитывающих структуру целевой и реальной выборки и используемых при статистическом обобщении данных исследования. В настоящее время предпочтение отдается именно этой стратегии, т.к. она не только позволяет получить более точные результаты, но и обходится значительно дешевле, хотя и требует определенной статистической квалификации.
Применение любой из этих стратегий предполагает наличие точной информации о том, по каким показателям достигнутая выборка отличается от целевой. Следовательно, в ходе исследования необходимо фиксировать важнейшие социально-демографические характеристики не только опрошенных респондентов, но также и тех, кто не смог или отказался участвовать в исследовании. Перевзвешивание допускается также в тех случаях, когда распределение социально-демографических показателей целевой выборки заранее неизвестно (например, при использовании метода маршрутной выборки). Тогда расчет весовых коэффициентов может производиться с использованием характеристик генеральной совокупности.
В наиболее простом случае формула для расчета весовых коэффициентов имеет вид:
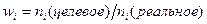 , (3.1)
, (3.1)
где i – номер группы с определенными характеристиками;
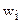 – весовой коэффициент для группы с номером i;
– весовой коэффициент для группы с номером i;
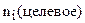 – численность группы с номером i в целевой выборке;
– численность группы с номером i в целевой выборке;
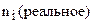 – численность группы с номером i в реальной (достигнутой) выборке.
– численность группы с номером i в реальной (достигнутой) выборке.
Если перевзвешивание производится по характеристикам ГС, в качестве и следует использовать относительные частоты, например, проценты.
Заметим, что группы могут выделяться как по отдельным критериям, так и по нескольким показателям одновременно. Например, при выделении поло-возрасто-образовательных групп необходимо располагать данными о совместном распределении целевой выборки или ГС по этим трем показателям.
Возможен также последовательный подбор частных весовых коэффициентов по каждому из контролируемых показателей отдельно; общий весовой коэффициент в таком случае вычисляется как произведение частных коэффициентов. Однако использование такой процедуры требует повышенного внимания и аккуратности, а также постоянного контроля за распределением всех контролируемых показателей.
Если рассматривать выборку как средство изучения ГС, то становится очевидным главное требование к ней – возможность обобщения результатов выборочного исследования на ГС с высокой степенью уверенности в справедливости выводов, сделанных в результате такого обобщения. Соответствие выборки этому требованию называется репрезентативностью. В зависимости от процедуры формирования выборки, которая, в свою очередь, определяется целями исследования и характеристиками ГС, применяются статистические и нестатистические методы обоснования репрезентативности.
Необходимо иметь ввиду, что результаты выборочных исследований всегда являются отчасти неопределенными. Это происходит потому, что изучается только часть ГС и измерения производятся с ошибками. Однако при отсутствии существенных просчетов в планировании и реализации выборки можно надеяться, что величина этих ошибок не выходит за некоторые допустимые пределы.
Ошибкой выборки для некоторого показателя называетсяразность междусреднимарифметическим значением этого показателя по выборке и по ГС. Поскольку генеральное среднее признака, как правило, неизвестно, в большинстве случаев невозможно вычислить точное значение ошибки выборки. Иногда ошибка выборки становится известной по истечении некоторого времени. Например, в электоральных исследованиях ошибки обычно становятся очевидными после опубликования результатов выборов.
Выделяют две составляющие ошибки выборки, одну из которых называют систематической, а другую случайной. Систематическая ошибка представляет собой некоторое смещение среднего значения признака по выборке по отношению к среднему значению по ГС, не уменьшающееся с увеличением числа опрошенных. Систематические ошибки обычно связывают с ошибками проектирования и реализации выборки, погрешностями процедур сбора информации, а также с разной степенью доступности респондентов и их готовности участвовать в исследовании. Систематические ошибки в ходе исследования трудно обнаружить, и еще труднее оценить их величину.
Случайные ошибки связаны с тем, что обследуется не вся ГС, а только некоторая ее часть, а также с ошибками измерения, не имеющими систематического характера. Ошибки такого рода неустранимы, однако важнейшее их свойство состоит в том, что они уменьшаются с увеличением объема выборки. Следовательно, увеличением объема выборки случайные ошибки можно свести к допустимому пределу и, при отсутствии систематических ошибок, обеспечить желательную степень точности результатов исследования.
Величину случайной ошибки можно контролировать методами статистики. При статистическом подходе степень точности для каждого отдельно взятого показателя задается (и измеряется) двумя количественными характеристиками – величиной случайной ошибки и вероятностью того, что эта величина не будет превышена (доверительной вероятностью). При этом предполагается, что систематическая ошибка отсутствует (равна нулю). Например, когда нам сообщают, что за кандидата Х проголосует 12% избирателей и величина ошибки с вероятностью 95% не превышает 2%, это значит, что с вероятностью 95% за данного кандидата проголосует от 10 до 14% всего взрослого населения (12%±2%). Вероятность того, что ошибка выборки выйдет за пределы ±2% (т.е. за кандидата Х проголосует менее 10% или более 14% населения), составляет 5%.
Величина случайной ошибки существенно зависит от объема выборки и способа ее извлечения. Стремление повысить точность (уменьшить величину ошибки) приводит к быстрому росту необходимого объема выборки и стоимости исследования. Таким образом, каждая реализованная выборка является компромиссом между желательной степенью точности результатов и имеющимися в распоряжении исследователя временными и материальными ресурсами.
Статистическое обоснование репрезентативности.Возможность статистического обобщения результатов выборочного исследования на ГС базируется на теоретических выводах математической статистики, которая, в свою очередь, основывается на приложениях теории вероятностей, предполагающей случайный (вероятностный) отбор изучаемых объектов из ГС. Прислучайном отборе все элементы ГС имеют одинаковую вероятность быть включенными в выборку. Для больших и неоднородных ГС обеспечить выполнение этого правила обычно бывает нелегко. Существует целый ряд выборочных методов и процедур, позволяющих более или менее успешно решать эту задачу.
Простой случайный отборпредполагает, что генеральная совокупность однородна, имеется полный список ее элементов, отбор из списка осуществляется посредством одной из специальных процедур, например, с помощью таблицы или компьютерного датчика равномерно распределенных случайных чисел. Если ГС невелика, могут применяться методы лотереи или жребия.
Основными преимуществами простого случайного отбора являются простота, относительная легкость оценивания случайных ошибок, а также объема выборки, необходимого для обеспечения репрезентативности.
Главными проблемами применения простого случайного отбора являются неочевидность однородности ГС, необходимость иметь полный список ее элементов, что не всегда возможно, неодинаковая степень доступности респондентов, высокая стоимость полевых работ, отсутствие анонимности, увеличивающее число отказов от участия в исследовании.
Весьма эффективным методом, имитирующим простой случайный отбор, является систематический отбор элементов генеральной совокупности из списка. Исходя из необходимого объема выборки n и объема генеральной совокупности N, устанавливается шаг отбора 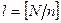 [1]. Первый элемент выборки выбирается случайным образом из первых l номеров списка: пусть это будет элемент с номером k
[1]. Первый элемент выборки выбирается случайным образом из первых l номеров списка: пусть это будет элемент с номером k 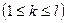 . Затем в выборку последовательно включаются объекты с номерами
. Затем в выборку последовательно включаются объекты с номерами 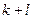 ,
, 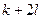 ,...,
,..., 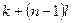 .
.
Систематическая выборка распределена по ГС более равномерно, чем простая случайная, что в некоторых случаях приводит к более точным результатам. Однако эффективность систематического отбора существенно зависит от особенностей генеральной совокупности и структуры списка.
Если в списке элементы ГС расположены случайным образом, в нем нет никаких статистических закономерностей, то можно ожидать, что систематический отбор будет, в сущности, равносилен простому случайному отбору. В этом случае к систематической выборке применим весь математический аппарат, разработанный для простого случайного отбора. Такими качествами обладают, например, списки и картотеки, составленные в алфавитном порядке.
Если элементы генеральной совокупности упорядочены по возрастанию или убыванию некоторого показателя, коррелирующего с изучаемым признаком, систематический отбор может оказаться более эффективным, чем простой случайный, т.е. при том же объеме выборки обеспечить более высокую точность результатов. Это обстоятельство делает систематический отбор особенно полезным, если генеральная совокупность неоднородна, или ее однородность не вполне очевидна.
Наконец, если генеральная совокупность содержит периодический тренд, то эффективность систематической выборки зависит от шага отбора l. Он не должен быть кратным периоду изменения значений признака; иначе выборка почти наверняка будет иметь систематическую ошибку. Например, если в качестве единицы отбора выступает квартира (домохозяйство), то при организации систематического выборочного опроса в многоквартирном доме шаг отбора не должен быть кратен числу квартир на лестничной клетке. Иначе интервьюер каждый раз будет попадать в однотипные квартиры, что, конечно, повлияет на состав выборки.
При расслоенном случайном отборе ГС предварительно разделяется на непересекающиеся части, и затем из каждой части, независимо друг от друга, извлекаются простые случайные выборки. Этот подход в отечественной специальной литературе называется также стратификацией, районированием или разукрупнением ГС. При этом под стратификацией чаще имеют в виду расслоение генеральной совокупности по уровням значений некоторого количественного признака (например, расслоение населенных пунктов в соответствии с численностью их жителей), а под районированием или разукрупнением – расслоение по значениям качественного признака (например, связанное с территориальным размещением ГС).
Расслоение генеральной совокупности рекомендуется применять в следующих случаях:
1.Если ГС слишком велика и неудобна для обследования “в один слой”. Именно к таким совокупностям относится население страны. Учет ее граждан по месту жительства ведется по областям, общегосударственного адресного стола не существует. Системы коммуникаций также имеют областную организацию и структуру. К тому же в областных центрах обычно имеются филиалы различных федеральных и республиканских служб, в том числе социологических, что может значительно упростить организацию исследования. Поэтому в абсолютном большинстве национальных исследований применяется стратификация населения по областям.
2. Если необходим сравнительный анализа разных частей ГС. В этом случае каждую из таких частей целесообразно рассматривать в качестве отдельной ГС.
3. Если в различных частях ГС необходимо применять разные процедуры отбора. Проблемы, связанные с отбором, в разных частях ГС могут существенно различаться. Это может быть обусловлено как спецификой выделяемых частей, так и особенностями организации статистической и учетной информации, необходимой для построения выборки.
4. Если расслоение может дать выигрыш в точности результатов исследования. Иногда удается разделить генеральную совокупность на слои, каждый из которых внутренне однороден, то есть результаты измерений внутри слоя изменяются от единицы к единице незначительно. Такое расслоение позволяет получить более точную оценку распределения изучаемого показателя как внутри каждого слоя, так и по генеральной совокупности в целом.
При расслоенном отборе используются две основные стратегии размещения выборки по слоям. Равномерное размещение предполагает, что в каждом слое обследуется одинаковое количество объектов. Оно обычно применяется в сравнительных и экспериментальных исследованиях. Пропорциональное размещение означает, что объем выборки в каждом слое пропорционален объему слоя в генеральной совокупности. Оно чаще используется в описательных исследованиях, к которым относится и большинство электоральных.
В условиях неопределенной (гипотетической) ГС, списки которой сложно или невозможно получить, применяются различные репрезентирующие процедуры, цель которых – обеспечить равную вероятность попадания в выборку для всех членов ГС. Наиболее часто испольщуется гнездовой или кластерный отбор, при котором респонденты выбираются не по одному, а целыми группами (кластерами). Кластерный отбор успешно применяется также в тех случаях, когда простая или расслоенная случайная выборка теоретически может быть извлечена, но не может быть обследована из-за ограниченности средств. Отбор кластерами позволяет осуществить выборку со значительно меньшими материальными и временными издержками.
При применении метода кластерного отбора ГС подразделяется на непересекающиеся подсовокупности (кластеры, гнезда) по некоторому объективному и мало зависящему от наблюдателя основанию. Эти подсовокупности, используемые в качестве промежуточных единиц отбора, могут состоять, в свою очередь, из более мелких единиц отбора или непосредственно из единиц наблюдения (например, респондентов). В качестве кластеров могут использоваться административные и административно-территориальные единицы – области, районы, населенные пункты, кварталы, улицы, отдельные дома и квартиры, трудовые коллективы, первичные организации общественных объединений, академические группы и т.п.
Структурные части ГС, используемые в качестве кластеров, должны удовлетворять следующим требованиям: 1) совокупность кластеров должна быть достаточно однородной, кластеры не должны сильно отличаться друг от друга по распределению изучаемых показателей; 2) напротив, объекты внутри кластера должны быть максимально разнообразны по своим характеристикам, и изучаемые признаки вокупностидолжны иметь максимальную изменчивость, соответствующую их вариативности в ГС; 3) желательно, чтобы кластеры имели примерно одинаковый объем.
При выполнении всех трех или хотя бы двух первых условий, исследование ГС может быть с успехом заменено исследованием некоторого количества кластеров, выбранных методом простого случайного отбора. Основу выборки при этом составляет полный список кластеров или гнезд.
Если первые два условия не выполнены, случайный отбор гнезд, особенно крупных, почти всегда приводит к значительным смещениям выборки. В этом случае лучших результатов можно достичь с помощью стратифицированного либо даже целенаправленного отбора кластеров.
Исследование кластерной выборки получается более экономичным, если обследовать небольшое количество крупных кластеров, и более точным, если обследовать много мелких кластеров. При отборе крупных кластеров из недостаточно однородной ГС можно получить значительную систематическую ошибку, не контролируемую статистически.
Существуют три основные стратегии размещения выборки при случайном отборе кластеров: отбор кластеров с равными вероятностями; отбор кластеров с вероятностями, пропорциональными их размеру; расслоение кластеров по размеру и отбор внутри слоев.
В некоторых случаях допускается также целенаправленный отбор кластеров, более удобных для анализа по каким-либо субъективным причинам.
Если отобранные кластеры обследуются полностью, выборка называется серийной. Если из каждого кластера производится дополнительный отбор единиц наблюдения, мы имеем дело с многоступенчатой выборкой. Таким образом, кластеры часто выступают в качестве промежуточных единиц отбора при построении многоступенчатой выборки. Остановимся на этих методах более подробно.
Одноступенчатый кластерный (серийный) отбор предполагает, что ГС разделена на более или менее однородные кластеры; построение выборки заключается в отборе кластеров по одной из схем случайного отбора; в выбранных кластерах обследуются все или почти все элементы (под однородностью кластеров понимается их сходство друг с другом по изучаемым показателям).
Обоснование точности серийной выборки зависит от процедуры ее извлечения.
1. Если кластеры однородны в смысле данного выше определения и имеют приблизительно одинаковые размеры, обычно используют простой случайный или систематический отбор кластеров из их полного списка (основы выборки). При этом ожидается, что результаты будут достаточно близки к результатам, полученным с помощью простого случайного отбора единиц наблюдения непосредственно ГС, и для расчета объема выборки и ее ошибок используется соответствующий математический аппарат.
Необходимое число кластеров определяется как результат деления объема выборки на среднее число объектов в кластере. Например, если в крупном городе предполагается опросить 500 студентов и в качестве кластера серийной выборки используется академическая группа со средней численностью 25 студентов, необходимо обследовать 20 (500/25) групп.
2. Если кластеры однородны, но их размеры заметно различаются, применяется либо случайный отбор с вероятностями, пропорциональными размеру кластеров, либо систематический отбор из списка кластеров, упорядоченных по размеру. В этом случае также ожидается, что результаты будут сопоставимы с результатами простого случайного отбора.
3. Если кластеры неоднородны, необходимо использовать расслоенный отбор. Отбор внутри слоев может производиться как по случайной схеме (с равными вероятностями или вероятностями, пропорциональными размеру кластеров), так и по систематической. Для исчисления необходимого объема и ошибок выборки в этом случае применяются те же методы, что и для расслоенного отбора.
Иногда расслоенный отбор применяется и в тех случаях, когда кластеры значительно (в несколько раз) различаются по размеру. Иначе в выборке наблюдается смещение в сторону крупных кластеров.
Многоступенчатый отбор. При многоступенчатом отборе кластеры обследуются не полностью, а выборочно. Каждый кластер рассматривается как совокупность более мелких кластеров. Из кластеров, отобранных на первой ступени, извлекается выборка кластеров второй ступени, и т.п. При этом выборки в каждом кластере не только строятся независимо друг от друга, но даже могут извлекаться различными, в том числе и кластерными, методами.
Заметим, что мы не оговариваем природу элементов, составляющих кластеры. Такой подход позволяет распространить выборочную процедуру на любую “глубину” многоступенчатой выборки.
Если отобранные кластеры второй ступени обследуется полностью, мы имеем дело с двухступенчатым отбором, на второй ступени которого применена серийная выборка. Если кластеры, отобранные на второй ступени, обследуются выборочно, отбор является трехступенчатым. При одинаковом размере кластеров целесообразно отбирать их с равной вероятностью и в каждом кластере обследовать одинаковое количество объектов. В случае неодинакового размера кластеров расслоенный отбор или отбор с вероятностями, пропорциональными размеру, дает лучшие результаты, чем отбор с равными вероятностями.
При построении многоступенчатой кластерной выборки могут оказаться полезными рекомендации У.Кокрена:
1. Определите, известны ли размеры кластеров точно, приближенно, или неизвестны совсем. В последнем случае выясните, можно ли получить какие-либо сведения о них.
2. Выясните, можно ли воспользоваться размером кластера как одной из переменных для расслоения. Это эффективный прием, если только он не помешает применить для расслоения некоторую другую переменную, которая могла бы дать значительный выигрыш в точности.
3. Решите, как должны отбираться кластеры внутри слоев. Если размеры кластеров хотя бы приближенно известны, то наилучшим часто будет отбор с вероятностями, пропорциональными размеру или квадратному корню из него.
4. Решите, какие должны быть доли отбора внутри слоев [27, 347-348].
Таким образом, для того чтобы разработать эффективный план многоступенчатой выборки с кластерами неодинакового размера, нужно проделать большую предварительную работу.
В большинстве национальных исследований применяется многоступенчатый отбор респондентов. Например, в электоральных исследованиях на первой ступени в качестве кластеров могут использоваться области, стратифицированные по политическим предпочтениям избирателей на предыдущих выборах. На второй ступени – населенные пункты в отобранных областях, стратифицированные по размеру (численности населения). На третьей ступени в разных населенных пунктах могут применяться различные стратегии отбора респондентов. Например, маршрутная выборка респондентов в сельских населенных пунктах и малых городах, и дальнейшая кластеризация населения больших городов (с использованием жилищно-эксплуатационных управлений, избирательных участков и т.п.).
Метод маршрутной (территориальной) выборки, наряду с кластерным отбором, представляет собой еще один способ формирования случайной выборки в условиях неопределенной ГС и при ограниченных материальных и временных ресурсах. Метод применяется в отдельных населенных пунктах или на избирательных участках, а также на последних ступенях многоступенчатой выборки. Единицей отбора при осуществлении маршрутной выборки является жилое помещение, семья или домохозяйство (группа лиц, ведущих общий бюджет).
Метод заключается в том, что интервьюер следует в населенном пункте предписанному маршруту, отбирая жилые помещения (дома, квартиры) по заданной схеме. Выбор маршрута и схемы отбора зависят главным образом от размера населенного пункта и типа застройки. В сельских населенных пунктах и малых городах с однородной застройкой маршрут может начинаться от одного из общественных зданий (исполкома, магазина, библиотеки, кинотеатра) или просто с одного из концов улицы.
В больших и средних городах необходимо обеспечить равную вероятность попадания в выборку жителям районов города с разным типом застройки. Для решения этой задачи применяются различные стратегии. Остановимся на двух наиболее популярных. Первая стратегия предполагает расслоение территории города по “функционально-застроечному” критерию – выделение административно-культурного центра, промышленной зоны, спальных районов, частного сектора и т.п. В выделенных зонах и секторах случайным образом отбираются улицы, на которых и осуществляется опрос. Недостаток этого подхода заключается в сложности и некоторой субъективности самой стратификации, а также в проблемах с получением информации о жилых помещениях, необходимой для распределения выборки по стратам.
Вторая стратегия заключается в построении кластерной выборки с использованием жилищно-эксплуатационных управлений (ЖЭУ) в качестве кластеров. Преимущества этого подхода очевидны. ЖЭУ равномерно размещены на территории города и сравнимы друг с другом по размеру (количеству жилых помещений), в них имеется наиболее достоверная информация обо всех находящихся на соответствующей территории жилых помещениях и проживающих в них людях. С точки зрения определения кластеров, ЖЭУ недостаточно однородны, тип застройки в них может радикальным образом отличаться, но этот недостаток отчасти компенсируется их относительно небольшими размерами, способствующими повышению точности исследования. Номера ЖЭУ обычно коррелируют с возрастом застройки, поэтому можно предположить, что систематическая выборка ЖЭУ по номерам обеспечит представительство всех типов застройки. В небольших городах ЖЭУ могут служить в качестве критерия расслоения жилых помещений. Если для построения выборки используются ЖЭУ, маршруты опроса могут начинаться прямо от них. Аналогичным образом могут использоваться почтовые отделения или избирательные участки.
При отборе улиц можно руководствоваться одним из следующих принципов:
– выбирать в каждой “зоне” улицы с характерными типами застройки;
– выбирать улицы из полного списка с применением методов случайного или систематического отбора;
– выбирать улицы случайным образом, не имея полного списка (например, улицы, в названии которых одновременно встречаются две заранее заданные буквы).
Реализация маршрутного метода отбора в городах, поселках городского типа или селах основывается на одинаковых принципах. Во-первых, каждый интервьюер получает задание опросить определенное количество респондентов, которых он отбирает по маршруту, который прокладывается по одной улице. Улица может иметь один из трех типов застройки: с многоквартирными, одноквартирными (частными) домами и смешанной застройки – с многоквартирными и одноквартирными домами. Улицу для опроса по особой методике отбирает для интервьюера бригадир. Если на улице находятся исключительно одноквартирные (частные) дома, то на этой улице должно быть такое количество домов, которое не меньше количества лиц, которых необходимо опросить, помноженное на 3. Например, интервьюеру необходимо опросить 10 человек. Следовательно количество домов на улице, отобранной бригадиром для опроса, не должно быть меньше 30. Если же на улице число домов меньше оговоренной нами величины, то интервьюер должен продолжить свой маршрут по улице, прилегающей к данной. Но упомянуть об этом в отчете о своей работе.
Маршрут может быть проложен и по части улицы, если эта улица является слишком длинной. Такой улицей мы считаем улицу с многоквартирной застройкой, на которой находится более 50 домов, или улицу с одноквартирными (частными) домами, число которых превышает 100.
Отбор домов. Дома отбираются исходя из количества жилых домов на улице и количества респондентов, которых необходимо опросить. Последовательность действий интервьюера и правила, которыми он должен руководствоваться, будут следующими.
Составление списка почтовых номеров всех жилых домов на улице.Интервьюер не должен пропускать дома с дополнительными буквенными изображениями в номерах или корпуса, которые имеют собственную нумерацию (например, 69-а или 24 корп.1). Ошибки при составлении списков домов будут влиять на одинаковую вероятность каждого жителя быть отобранным для опроса. А это приводит к ошибкам в информации. В список домов не должны включаться нежилые дома – магазины, школы, детские дома и ясли, организации и учреждения, больницы и поликлиники, дома, которые реконструируются или еще только сооружаются.
Упорядочение списка почтовых номеров домов в порядке их увеличения.Если номера домов имеют дополнительные буквенные или цифровые обозначения, то упорядочивать их необходимо в последовательности, которая дана в примере. Пример: 1/8, 1-а, 1-б, 2/17, 2 корп.1, 3, 4, 4-а и т.д.
Определение общего количества домов и расчет шага отбора домов.Например, на какой-то улице мы выделили 42 жилых дома. На этой улице интервьюеру необходимо опросить 10 респондентов. Чтобы определить шаг отбора домов, необходимо количество жилых домов, находящихся на данной улице, разделить на количество респондентов, которых необходимо опросить интервьюеру. Если в результате деления получается нецелое число, то оно округляется в сторону меньшего целого числа.
Для того чтобы определить номер первого дома, в котором необходимо отобрать респондента,необходимо шаг отбора домов разделить на 2. Если шаг отбора – нечетное число, то в этом случае к шагу отбора необходимо добавить 1 и полученную сумму разделить на 2. В нашем примере шаг отбора равняется 4. Определяем номер первого дома: для этого шаг отбора делим на 2 – 4:2=2. Следовательно, номер первого дома (если принять во внимание приведенный в качестве примера упорядоченный список жилых домов на улице) будет – 1-а. Это первый дом, в котором начинается поиск респондента.
Определение всех других домов, в которых отбираются респонденты.От каждого отобранного дома отсчитать, начиная с последующего дома в упорядоченном списке, количество жилых домов, которое равняется шагу отбора, в сторону увеличения почтовых номеров.
Действия интервьюеров в случае, когда в отобранном доме не удалось провести опрос.Это может случиться, если в выборку попадают одноквартирные (частные) дома. В этом случае интервьюер должен перейти в следующий по упорядоченному списку номер дома. Например, по каким-то причинам опрос в доме 1-а не состоялся. Тогда интервьюер должен перейти в дом под номером 1-б. Но в этом случае интервьюер должен действовать так, чтобы не менять схему отбора домов.
Отбор квартиры.Прежде всего необходимо определить общее количество квартир в отобранном для опроса доме. Затем количество квартир делится на число, которое указано в Инструкции для каждого исследования (это число не постоянное, а меняется в каждом исследовании). Полученное в результате деления число соответствует номеру квартиры, в которой необходимо отбирать респондента. Пример. Предположим, в отобранном доме 96 квартир, а в инструкции указывается, что количество квартир необходимо разделить на 5. Тогда, 96:5=19,2. Округляем до меньшего целого числа. Следовательно, респондента необходимо отбирать в 19 квартире.
Однако если по каким-то причинам (в квартире никто не живет, нужный для опроса респондент отсутствует на протяжении всего периода исследования — в командировке, болеет и пр., респондент отказался от опроса и пр.) опрос в данной квартире не удалось провести, то интервьюер должен перейти в следующую в порядке увеличения номеров квартиру. В нашем примере такой квартирой будет квартира под помером 20.
Отбор респондентов можно производить по различным методикам, большинство из которых достаточно подробно описано в отечественной социологической литературе.
Следующие правила регламентируют работу интервьюера по отбору респондентов:
- Интервьюер обязан отбирать респондентов, проживающих на одной улице. Исключение может быть сделано только для сельских населенных пунктов: иногда трудно реализовать квотный отбор респондентов на одной улице села. В этом случае допускается добирать респондентов, проживающих на прилегающей улице.
- Опрос проводится по месту проживания респондентов, в том числе и в общежитиях. В квартире интервьюер может опросить любого человека, который постоянно проживает в ней и характеристики которого совпадают с характеристиками, заданными в задании. Наличие прописки, форма собственности на это жилье (хозяин или квартиросъемщик) не имеют значения для интервьюера. Главное, чтобы респондент тут реально проживал.
- В одной квартире (одноквартирном доме) интервьюер имеет право опросить только одного человека.
- В общежитии интервьюер имеет право опросить только одного человека.
- В многоквартирном доме, в котором до 100 квартир, интервьюер имеет право опросить не более 2 человек.
- В многоквартирном доме, в котором более 100 квартир, интервьюер имеет право опросить не больше 3 человек.
- Интервьюер не имеет права опрашивать: граждан других стран, гостей, знакомых, родственников, которые зашли к хозяевам квартиры, где проводился опрос, а также членов этой семьи, которые учатся или работают в другом населенном пункте и имеют там жилье.
После анализа собранной первичной информации в каждом исследовании контролируются признаки, по которым квота интервьюерам не задается – национальность и социальная принадлежность респондентов. Отклонения по этим параметрам в выборочной и ГС, как правило, колеблются в пределах заданной точности – 2 – 3 %. Дважды проводился эксперимент, подтвердивший надежность квотного отбора. В опросник вводился вопрос, формулировка которого полностью совпадала с формулировкой вопроса в референдумах. Опрос завершался за день-два до референдума. Различия в данных референдума и выборочного социологического исследования как в целом по всему массиву, так и по отдельным регионам страны не превышали все те же 2-3 процента.
Таким образом, мы проанализировали несколько схем и процедур отбора респондентов на последней ступени выборки. Выбор какой-то одной процедуры отбора опрашиваемых находится в компетенции исследователя и зависит от ряда факторов: структуры сети интервьюеров, материальных возможностей, которые находятся в распоряжении исследователей, уровня добросовестности и квалификации интервьюеров, организационных возможностей исследователей и пр.
Расчет случайной репрезентативной выборки.Под расчетом случайной репрезентативной выборки принято понимать, во-первых, определение величины случайной ошибки выборки, и во-вторых, нахождение такого объема выборки, при котором случайная ошибка не превысит предельно допустимой величины с заданной доверительной вероятностью. Если выборка имеет сложный дизайн, является стратифицированной, кластерной, многоступенчатой, то расчет выборки включает также определение количества объектов, которые должны быть обследованы в каждом слое, кластере и т.п. Во многих случаях это сложная и нетривиальная задача. Здесь мы рассмотрим только некоторые, наиболее простые, ее аспекты. За более подробной информацией интересующиеся могут обратиться к специальной литературе, в частности, к монографии У.Кокрена “Методы выборочного исследования”.
Определение величиныслучайной ошибки простой случайной выборкииз бесконечной ГСбазируется на теоретическом результате, полученном в математической статистике: если из бесконечной ГС извлекать простые случайные выборки одного и того же объема n, и дисперсия изучаемой переменной по генеральной совокупности равна 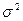 , то случайная ошибка выборки
, то случайная ошибка выборки 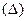 для этой переменной имеет распределение, близкое к нормальному, с математическим ожиданием, равным нулю, и дисперсией, равной
для этой переменной имеет распределение, близкое к нормальному, с математическим ожиданием, равным нулю, и дисперсией, равной 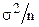 .
.
Из свойств нормального распределения следует, что значение таких ошибок почти всегда не слишком велико. С заранее заданной вероятностью они не выходят за пределы так называемого доверительного интервала, который в общем случае имеет вид:
 (3.2)
(3.2)
где 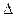 – величина случайной ошибки выборки;
– величина случайной ошибки выборки;
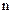 – объем выборки;
– объем выборки;
 – дисперсия признака по ГС;
– дисперсия признака по ГС;
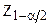 – доверительный коэффициент, соответствующий выбранному значению
– доверительный коэффициент, соответствующий выбранному значению 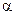 .
.
Греческой буквой принято обозначать вероятность того, что значение случайной ошибки может выти за границы интервала (3.2). Значение выбирают заранее; причем наиболее часто используют 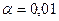 ,
, 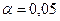 или
или 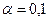 . Доверительный коэффициент
. Доверительный коэффициент  соответствует доверительной вероятности
соответствует доверительной вероятности 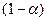 и определяется по таблице стандартного нормального распределения. Так,
и определяется по таблице стандартного нормального распределения. Так,
значению соответствует значение 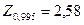 ;
;
значению соответствует значение 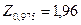 ;
;
значению соответствует значение  .
.
Соответственно, ошибка выборки не выходит за пределы интервала
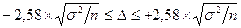 с вероятностью 99%;
с вероятностью 99%;
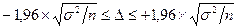 с вероятностью 95%;
с вероятностью 95%;
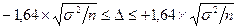 с вероятностью 90%.
с вероятностью 90%.
Заметим, что для упрощения расчетов часто принимают 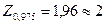 .
.
В большинстве реальных исследований неизвестна, и вместо точного значения используется ее оценка по выборке:  . В этом случае неравенство (3.2) принимает вид:
. В этом случае неравенство (3.2) принимает вид:
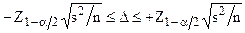 (3.3)
(3.3)
где 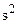 – дисперсия, рассчитанная по выборке.
– дисперсия, рассчитанная по выборке.
Используя неравенство (3.3), можно оценить ошибку простой случайной выборки после того, как исследование завершено. Поскольку используемые переменные по одной и той же выборке имеют разные дисперсии, то и длина интервала, с помощью которого оценивается ошибка выборки для разных переменных, также будут различаться: чем больше дисперсия, тем больше возможное значение ошибки. Длина интервала зависит также от выбранного значения : чем оно меньше, тем выше доверительная вероятность  и соответствующее ему значение , а значит длина интервала больше. Наконец, длина интервала и, соответственно, ошибка выборки тем меньше, чем больше объем выборки
и соответствующее ему значение , а значит длина интервала больше. Наконец, длина интервала и, соответственно, ошибка выборки тем меньше, чем больше объем выборки 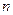 .
.
Неравенство (3.2) можно использовать также для расчета объема простой случайной выборки, при котором ее случайная ошибка с заданной доверительной вероятностью не превысит некоторой допустимой величины. Если мы считаем, что ошибка репрезентативной выборки с вероятностью не должна превышать некоторую величину 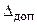 , то можем легко найти необходимый объем выборки, приравняв к половине длины доверительного интервала:
, то можем легко найти необходимый объем выборки, приравняв к половине длины доверительного интервала: 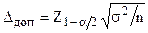 , из чего следует, что
, из чего следует, что
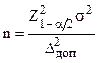 , (3.4)
, (3.4)
где – предельно допустимая величина случайной ошибки выборки;
– дисперсия признака по генеральной совокупности;
– доверительный коэффициент, соответствующий выбранному значению ;
– объем выборки, при котором случайная ошибка выборки не превысит величины с вероятностью .
Если величину и (и тем самым ) исследователь выбирает самостоятельно, то дисперсия генеральной совокупности в большинстве случаев неизвестна, и ее необходимо каким-то образом оценить до начала исследования. Существует несколько подходов к решению этой задачи.
1. Величину дисперсии можно предварительно оценить по публикациям других исследователей.
2. Можно провести специальное пилотажное исследование и использовать его дисперсию для оценивания .
3. Максимальное значение дисперсии можно приблизительно оценить по формуле 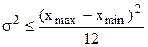 , хоть эта оценка представляется достаточно грубой.
, хоть эта оценка представляется достаточно грубой.
Из формулы (3.4) видно, что чем меньше предельно допустимая величина ошибки, чем выше доверительная вероятность и больше значение дисперсии, тем больше должен быть объем выборки для того, чтобы она могла считаться репрезентативной.
Выражения (3.3) и (3.4) предназначены для определения ошибки и объема выборки для количественных переменных. Поскольку большинство социологических переменных являются номинальными, а результаты исследования обычно выражаются в процентах респондентов, выбравших тот или иной ответ на вопрос, преобразуем выражения (3.3) и (3.4) к такому виду, чтобы их можно было использовать для номинальных шкал. Для преобразования используем то обстоятельство, что для доли респондентов (p), выбравших интересующий нас ответ, дисперсия равна произведению 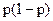 .
.
Тогда ошибка выборки с вероятностью не выходит за пределы интервала:
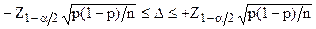 , (3.5)
, (3.5)
где – величина случайной ошибки выборки;
– объем выборки;
 – доля респондентов в выборке, выбравших данный вариант ответа;
– доля респондентов в выборке, выбравших данный вариант ответа;
– доверительный коэффициент, соответствующий выбранному значению .
Объем случайной репрезентативной выборки может быть оценен по формуле
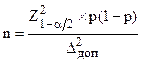 , (3.6)
, (3.6)
где – предельно допустимая величина случайной ошибки выборки, выраженная в долях единицы;
– вероятность выбора данного варианта ответа для генеральной совокупности;
– доверительный коэффициент, соответствующий выбранному значению ;
– объем выборки, при котором случайная ошибка выборки не превысит величины с вероятностью .
Величину и исследователь выбирает самостоятельно, но значение 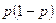 для генеральной совокупности в большинстве случаев неизвестно, и его необходимо каким-то образом оценить до начала исследования. Возможные решения этой задачи аналогичны подходам к оцениванию дисперсии. Можно воспользоваться опубликованными данными или провести пилотажное исследование. Однако на практике чаще всего используют максимально достижимое значение
для генеральной совокупности в большинстве случаев неизвестно, и его необходимо каким-то образом оценить до начала исследования. Возможные решения этой задачи аналогичны подходам к оцениванию дисперсии. Можно воспользоваться опубликованными данными или провести пилотажное исследование. Однако на практике чаще всего используют максимально достижимое значение 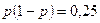 , которое достигается при
, которое достигается при 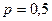 .
.
Все полученные до сих пор результаты относились к бесконечным ГС. Если ГС конечна, и ее объем сопоставим с объемом выборки, то для вычисления ошибки и объема выборки вводится поправка на конечность ГС, равная 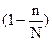 , где n – объем выборки, N – объем генеральной совокупности.
, где n – объем выборки, N – объем генеральной совокупности.
Для количественных переменных ошибка выборки с вероятностью находится в интервале:
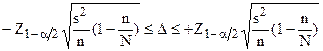 . (3.3а)
. (3.3а)
Объем выборки, при котором ошибка выборки с вероятностью не превысит заданной величины , равен
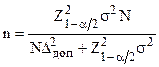 . (3.4а)
. (3.4а)
Аналогичные формулы для номинальных шкал, с поправкой на объем ГС, примут вид:
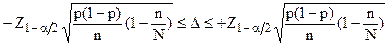 (3.5а),
(3.5а),
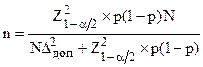 , (3.6а).
, (3.6а).
Если для номинальных шкал в качестве максимальной оценки принять значение 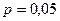 , то можно рассчитать объем выборки в зависимости от объема генеральной совокупности по следующей схеме:
, то можно рассчитать объем выборки в зависимости от объема генеральной совокупности по следующей схеме:
| Объем ГС | 
| ||||||||
| Объем выборки |
Мы рассмотрели только наиболее простой случай – ошибку и объем простой случайной репрезентативной выборки. При более сложном дизайне выборки сложность расчетов многократно возрастает. Детально с ними можно познакомиться в специальной литературе.
Напомним, что для разных переменных значения дисперсии и количество респондентов, выбравших определенный ответ, будут различаться и, соответственно, будут различаться значения ошибки выборки и объема выборки, обеспечивающего ее репрезентативность. В этой сложной ситуации мы рекомендуем ориентироваться, в первую очередь, на достижение удовлетворительной точности результатов для признаков, наиболее важных с точки зрения целей исследования.
Нестатистическое обоснование репрезентативности.Как уже упоминалось, в ОСИ используются не только статистические, но и нестатистические методы формирования выборок и обоснования репрезентативности. Нестатистические методы применяются главным образом тогда, когда невозможно получить надежную основу для вероятностной выборки или когда вероятностная выборка не может быть реализована из-за недостатка временных и материальных ресурсов. Поскольку нестатистические методы часто используются при исследовании неопределенных (гипотетических) случайных совокупностей, они могут быть направлены не только на отбор респондентов, но и на поиск трудно определяемых или малодоступных социальных целевых групп. Поэтому иногда их также называют целевыми.
Отбор квотами представляет собой нестатистическую разновидность расслоенного отбора. В “чистом” виде он предполагает субъективный отбор единиц наблюдения в пределах квоты, заданной для слоя, определенного некоторой комбинацией значений квотируемых признаков.
В качестве квотируемых признаков чаще всего используются место жительства, пол, возраст, образование, расовая или национальная принадлежность, отдельные характеристики имущественного положения. Техническая проблема квотного отбора заключается в том, что для определения квот должно использоваться совместноераспределение всех квотируемых показателей, в то время как официальная статистика предлагает, в лучшем случае, данные о распределении населения по полу, возрасту и образованию.
Многие авторы отмечают, что при квалифицированном использовании квотная выборка часто является более тонким инструментом социологического анализа, чем вероятностная. Так, У. Кокрен указывает, что хотя для таких характеристик, как доход, образование или род занятий, метод квот дает смещенные выборки, при изучении мнений и психологических установок он часто приносит результаты, которые хорошо согласуются с результатами вероятностного отбора [27, 155]. Преимущества квотного отбора заключаются в более низкой, по сравнению со случайным отбором, стоимости и сохранении анонимности, важной для самочувствия респондента.
Главными недостатками квотного отбора являются субъективность в подборе респондентов и невозможность статистического обоснования репрезентативности полученной выборки. Ошибка квотной выборки может быть оценена только в тех случаях, когда среднее значение признака по ГС в конце концов становится известным. Математических способов оценивания ошибки или необходимого объема квотной выборки не существует, хотя иногда в практических целях используют формулы, предназначенные для случайных выборок.
Метод квот нередко применяется в сочетании с маршрутной выборкой: интервьюер определяет, есть ли среди членов семьи удовлетворяющие условиям квот, и если таковых не находится, продолжает движение по маршруту. Сочетание этих двух методов позволяет в значительной мере компенсировать недостатки каждого из них. Применение метода квот не требует составления списка членов семьи и тем самым создает у респондента большую уверенность в анонимности опроса, что в конечном счете снижает количество отказов от участия в исследовании. Следование заданному маршруту препятствует субъективному отбору респондентов, характерному для квотного метода. Главным недостатком такого подхода является неконтролируемая возможность систематической ошибки. Поскольку квоты по полу, возрасту, образованию и другим важным признакам в любом случае будут выполнены, постольку оценить мнение тех, кто отказался отвечать, не представляется возможным. Ошибка такой выборки не может быть оценена статистически.
Метод основного массива состоит в том, чтобы подвергнуть обследованию основную часть относительно небольшой ГС. Как правило, речь идет о достаточно гипотетичных ГС. Так, в приведенном выше примере, члены армянского культурного общества могут рассматриваться как достаточно полная часть армянской диаспоры в Минске. Метод может применяться только тогда, когда у исследователя есть уверенность, что мнение опрошенной части ГС в целом совпадает с мнением неопрошенной ее части. Если такой уверенности нет, метод применять нельзя.
Частным случаем метода основного массива является метод снежного кома, или цепной выборки. От метода основного массива его отличает способ поиска представителей малочисленной и труднодоступной ГС, например, экспертов по узкой проблеме или коллекционеров, собирающих какие-либо редкие предметы. Поиск начинается с нахождения одного или нескольких представителей такой ГС, которых затем спрашивают, кого из авторитетных коллег они могли бы назвать. Опрос продолжается “по цепочке”. Все названные фамилии заносятся в список, который растет как снежный ком. Когда фамилии в списке начинают повторяться, считается, что основная часть ГС исследованием охвачена.
Пожалуй, наименее обоснованным и наиболее чреватым систематическими ошибками является метод стихийного отбора или доступной выборки. Это метод применяется, например, при уличных опросах (в этом варианте он может называться также методом “первого встречного”), при исследовании аудитории СМИ (читателей, телезрителей и т.п.) непосредственно через СМИ и в других подобных случаях. Проблема репрезентативности стихийной выборки заключается в том, что в разных точках города “первыми встречными” оказываются разные категории людей, также как весьма специфична та часть аудитории, которая откликается на опросы в прессе и электронных медиа, включая Интернет.
Прямо противоположный подход используется в выборках так называемых качественных исследований, в которых участвует очень небольшое число респондентов, и отбор этих распондентов производится крайне тщательно и действительно является целевым. К ним относятся выборка экстремальных или девиантных случаев, интенсивная выборка, выборка максимальной вариации, гомогенная выборка, выборка типичных случаев, стратифицированная выборка типичных случаев, выборка критических случаев, критериальная выборка [26, 83-90].
Выбор экстремальных или девиантных случаев сфокусирован на тех случаях, которые необычны или в некотором смысле специальны. Они трудны для изучения, но часто высокоинформативны, так как необычные условия или объекты могут нести в сжатом виде всю информацию о ГС. Проблема состоит в том, что девиантные случаи могут оказаться столь неожиданными, что способны исказить представления об изучаемом явлении.
Интенсивная выборка состоит из информационно значимых случаев, которые в значительной, но не экстремальной, степени представляют изучаемое явление. Интенсивная выборка включает некоторую предварительную информацию и предварительные суждения, необходимые для отбора информативных случаев.
Выборка максимальной вариации предназначена для описания центральных аспектов, характерных для большей части ГС. Для того, чтобы максимизировать вариацию в небольшой выборке, следует начать с определения критериев, важных для конструирования выборки. Например, у исследователя может не быть средств, достаточных для реализации национальной случайной выборки, но, включив в выборку городские и сельские поселения, он тем не менее не упустит те аспекты изучаемой проблемы, которые связаны с поселенческой структурой. Анализ данных, полученных на небольшой выборке, построенной методом максимальной вариации, обычно включает два пункта. Во-первых, это детальное описание каждого случая, его уникальности, и во-вторых, описание общей модели, которая проявляется во всех случаях, несмотря на их гетерогенность.
Гомогенная выборка является прямой противоположностью стратегии выборки максимальной вариации. Цель создания таких выборок заключается в том, чтобы описать определенную социальную группу с наибольшей полнотой. На г
Дата добавления: 2015-09-11; просмотров: 5787;