Информационная мера Фишера
Как мы уже отмечали ( разд. 1), метрологическая(измерительная) информация формируется (вырабатывается) в процессе измерения некоторой (в частности – действительной) величины посредством измерительной аппаратуры (например, с помощью аналого-цифрового преобразователя аналоговых сигналов), а на результаты измерения оказывают случайные воздействия различные непреднамеренные помехи.
Если измерительный прибор предварительно откалиброван, то в процессе измерения не возникает систематических погрешностей, а точность результата измерения характеризуется известной дисперсией Dп = σп2 случайных погрешностей измерений.
Как охарактеризовать количество измерительной информации, вырабатываемой в процессе измерения некоторой величины, например напряжения u0 (в Вольтах), которая может принимать произвольное значение x = x0 на множестве действительных чисел (– ∞ < x < ∞)?
К. Шеннон не проводил отдельного анализа этой ситуации, а постулировал ([46], с. 296):
«Энтропия дискретного множества вероятностей p1, …, pn была определена как
H = – 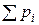 log pi. (11.1)
log pi. (11.1)
Аналогичным образом определим энтропию непрерывного распределения с функцией плотности распределения p(x) как
H = – 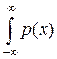 log p(x) dx ». (11.2)
log p(x) dx ». (11.2)
Н. Винер при введении «разумной меры количества информации» для «непрерывных сообщений» типа (11.1) ссылается на личное сообщение Дж. фон Неймана ([10], с. 121) и вводит её как H = + 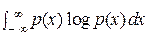 .
.
При этом Н. Винер отмечает ([10], с. 122):
«Величина, которую мы здесь определяем как количество информации, противоположна по знаку величине, которую в аналогичных ситуациях обычно определяют как энтропию. Данное здесь определение не совпадает с определением Р. А. Фишера для статистических задач, хотя оно также является статистическим определением и может применяться в методах статистики вместо [выделено мною – Г. Х.] определения Фишера».
В дальнейшем в математической теории информации приняли определение (11.2) К. Шеннона. Однако формально-математическое обобщение выражения (11.1) на непрерывные распределения pα(x) случайной величины α приводят к следующему противоречию:
H(x) = 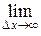 {
{ 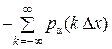 Δ x log [ pα(k Δ x) Δ x]} =
Δ x log [ pα(k Δ x) Δ x]} =
= – { 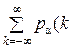 Δ x) log [ pα(k Δ x)] Δ x} – [log Δ x Δ x) Δ x],
Δ x) log [ pα(k Δ x)] Δ x} – [log Δ x Δ x) Δ x],
или H(x) = – 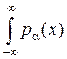 log [ pα(x)] dx – [log Δ x ],
log [ pα(x)] dx – [log Δ x ],
или H(x) = – log [ pα( x)] dx + ∞. (11.3)
Бесконечность в выражении (11.3) обычно («из практических соображений») отбрасывают, аинтегралh(x) = – 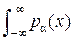 log [pα(x)] dx называютдифференциальной(относительной, сведённой) энтропией.
log [pα(x)] dx называютдифференциальной(относительной, сведённой) энтропией.
Например, при гауссовском распределении pα(x) погрешностей измерений
h(x) = 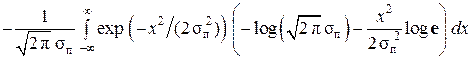 ,
,
или h(x) = log 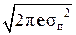 = log
= log 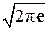 + log σп.
+ log σп.
Поскольку величина (2 π e) играет большую роль в ПТИ, введём для неё специальное обозначение μ0 = 2 π e ≈ 17,1. Поэтому дифференциальную энтро-
пию h(x) гауссовского распределения pα(x) будем записывать в виде
h(x) = log 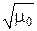 + log σп =
+ log σп = 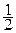 log (μ 0 Dп).
log (μ 0 Dп).
Зависимость h(x) от величины σп представлена на рис. 12. Там же приведена зависимость от σп информационной меры Неймана-Винера.


 I
I

 3
3 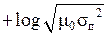
2
1 σn–2

 0,242 σn
0,242 σn
 0 1 2 3
0 1 2 3
– 1
– 2
– 3 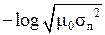
Рис. 12. Зависимость количества информации I,
вырабатываемой при однократном измерении величины u0,
от среднеквадратического значения погрешностей измерений σn
Дифференциальная энтропия h(x) имеет следующие особенности.
а) Она может быть как положительной, так и отрицательной:
h(x) = 0 при σп = (2 π e) – 1/2 ≈ 0,242.
б ) Она растёт с увеличением дисперсии Dп = σп2 погрешностей измерений (то есть чем точнее измерительный прибор, тем меньше информации получается в результате его использования). Правда, мера Неймана-Винера имеет «правильную зависимость»: она даёт уменьшение количества измерительной информации с увеличением дисперсии Dп.
в) Она имеет «странную» размерность; например [log (Вольт)].
г) Она изменяется при формальном изменении масштаба по оси O x.
д) Она не обладает свойством аддитивности относительно дисперсии Dп.
Действительно. Если в нашем распоряжении имеются результаты двух независимых измерений x1 и x2, обладающих дисперсиями погрешностей D1 и D2, то их совместная плотность вероятности есть: p(x1, x2) = p(x1) p(x2). Дифференциальная энтропия в этом случае формально определяется как
h(x) = – 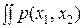 log p(x1, x2) dx1 dx2 =
log p(x1, x2) dx1 dx2 =
= – 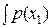 log p(x1) dx1 –
log p(x1) dx1 – 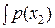 log p(x2) dx2
log p(x2) dx2
и при гауссовских законах распределения p(x1) и p(x2) она равна:
h(x) = log 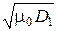 + log
+ log 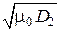 , или h(x) = log μ 0 + log σ1 + log σ2.
, или h(x) = log μ 0 + log σ1 + log σ2.
Если рассуждать «негэнтропийно», то следует полагать, что доизмерения (априори) мы имели некоторую большую неопределённость измеряемой величины x0, характеризуемую дифференциальной энтропией h(x) = log σ0 + log ,
где величина σ0 определяется нашими предположениями относительно ожидаемого значения величины x0.
Если мы провели измерение неизвестной нам величины x0 и получили апостериорное значение x1 со среднеквадратической погрешностью σ1, то, согласно негэнтропийной точки зрения, мы получили количество измерительной информации: I1 = h(x0) – h(x1) = log σ0 – log σ1 = log (σ0 /σ1) > 0.
Если мы имеем результаты двух независимых измерений x1 и x2 величины x0 со среднеквадратическими погрешностями измерений соответственно σ1 и σ2, то мы должны считать, что получили количество измерительной информации
I1 + I2 = log (σ0 /σ1) + log (σ0 /σ2) = log [σ02/(σ1 σ2)].
Суммарное количество информации (IΣ = I1 + I2) должно быть выражено через дифференциальную энтропию, то есть иметь вид IΣ = log (σ0 /σΣ). Однако из теоретической метрологии, как будет показано ниже, следует, что при оптимальном способе точечного оценивания величины x0 по результатам двух независимых измерений x1 и x2 дисперсия оптимальной оценки 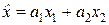 будет минимально возможной и составлять величину DΣ = σΣ2 = 1/(σ1–2 + σ2–2).
будет минимально возможной и составлять величину DΣ = σΣ2 = 1/(σ1–2 + σ2–2).
Значит, при негэнтропийной трактовке процесса выработки измерительной (метрологической) информации имеем:
IΣ = log(σ0 /σΣ) = 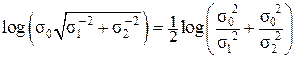 ,
,
или IΣ = 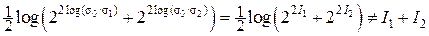 .
.
Если же считать, что результат второго измерения x2 является апостериорным по отношению к первому x1, то при втором измерении мы получим количество информации I21 = log (σ1 /σ2). При σ1 = σ2 ( равноточные измерения): I21 = log (σ1 /σ1) = 0, а если σ2 > σ1, то I21 = log (σ1 /σ2) < 0.
Это явно противоречит интуитивному понятию о количестве информации, получаемой в процессе измерений, то есть в процессе выработки измерительной (метрологической) информации.
Как видим,формально-математическое обобщение меры знаковой (семиотической, дискретной) информации на измерительную (метрологическую, «непрерывную») информацию приводит к нарушению основных постулатов теории информации.
Вернёмся к основным постулатам теории информации и попытаемся непротиворечивым образом ввести информационную меру для измерительной (метрологической) информации.
Пусть измеряется некоторая величина x0, которая может принимать любые значения из множества действительных чисел (– ∞ < x < ∞). Откалиброванный измерительный прибор не имеет систематической погрешности измерений ( 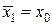 ) и имеет дисперсию погрешностей измерений D1 = σ12. Какое количество информации формирует (вырабатывает) этот измерительный прибор, если в результате одного измерения получено значение x = x1?
) и имеет дисперсию погрешностей измерений D1 = σ12. Какое количество информации формирует (вырабатывает) этот измерительный прибор, если в результате одного измерения получено значение x = x1?
Очевидно, что измеряемая величина x0 с некоторой вероятностью P ≈ 1 лежит в пределах (x1 – c σ1) < x 0 < (x1 + c σ1), где c > 1 (интервальное оценивание: Ежи Нейман, 1937 г., или «остаточная неопределённость» результата измерения).
По аналогии со знаковой (семиотической) информацией (см. разд. 3) мы должны потребовать следующее.
а) Полученная в результате однократного измерения информация I(x1) должна быть неотрицательной: I(x1) ≥ 0.
б) Чем меньше дисперсия погрешностей D1 измерительного прибора, тем точнее интервальная оценка (меньше «остаточная неопределённость») и тем больше информации мы получаем в результате однократного измерения x1;
в) Если мы получили второе измерение x2 другим прибором, характеризующимся большей дисперсией D2 погрешностей (D2 > D1), то I ( x2) < I ( x1).
г) Для обеспечения свойства аддитивности измерительной (метрологической) информации рассмотрим максимальное количество информации, которое можно извлечь из результатов двух независимых неравноточных измерений x1 и x2.
Будем искать оценку 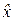 величины x0 в линейном виде:
величины x0 в линейном виде: 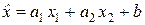 .
.
Чтобы оценка 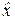 была несмещённой, то есть чтобы выполнялось равенство
была несмещённой, то есть чтобы выполнялось равенство 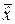 = x0, нужно, чтобы математическое ожидание
= x0, нужно, чтобы математическое ожидание 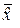 оценки
оценки 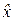 было равным измеряемой величине x0:
было равным измеряемой величине x0: 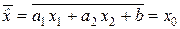 .
.
Отсюда a1 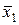 + a2
+ a2 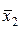 + b = x0, или ( a1 + a2 ) x0 + b = x0.
+ b = x0, или ( a1 + a2 ) x0 + b = x0.
Значит, для несмещённости оценки следует положить:
b = 0 и a1 + a2 = 1.
Определим дисперсию DΣ оценки :
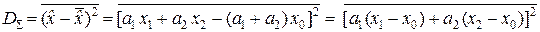 ,
,
или DΣ = a12 D1 + a22 D2, поскольку 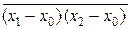 = 0 – в силу независимо-
= 0 – в силу независимо-
сти погрешностей результатов измерений x1 и x2.
Введём обозначение a = a1; тогда a2 = 1 – a и DΣ = a 2 D1 + (1 – a) 2 D2.
Кроме несмещённости оценки разумно также потребовать, чтобы она имела дисперсию, наименьшую из возможных значений дисперсии для линейных оценок вида = a1 x1 + a2 x2 (эффективность оценки).
Для этого нужно решить уравнение
dDΣ /da = 2 a D1 – 2(1 – a) D2 = 0,
в результате чего находим: a = D1–1/(D1–1 + D2–1) = a1; a2 = D2–1/(D1–1 + D2–1);
DΣ–1 = D1–1 + D2–1, или σΣ–2 = σ1–2 + σ2–2.
Методом математической индукции можно доказать, что при произволь-
ном значении n > 2 оценки = 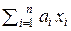 будет иметь следующие величины оптимальных весовых коэффициентов {ai}
будет иметь следующие величины оптимальных весовых коэффициентов {ai} 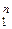 и минимальной дисперсии DΣ:
и минимальной дисперсии DΣ:
ai = DΣ / Di; DΣ–1 = 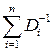 ; σΣ–2 =
; σΣ–2 = 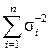 .
.
Следовательно, в общем случае n независимых неравноточных измерений
(x1, x2, …, xi, …, xn) неизвестной величины x0 её оптимальная оценка вычисляется по формуле: = 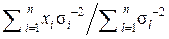 и имеет минимально возможную дисперсию DΣ =
и имеет минимально возможную дисперсию DΣ = 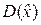 =
= 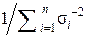 .
.
| Количественной меройIiизмерительной (метрологической) информации в одномерном случае является обратная дисперсия погрешностей измерительного прибора Ii = 1/Di, которая удовлетворяет всем четырём постулатам прикладной теории информации. |
Это и есть информационная мера Р. Фишера, которая также представлена на рис. 12.
В 1981 г. Международный комитет мер и весов (МКМВ) рекомендовал использовать как показатель качества измерительной информации неопределённость результата измерения. В 1993 г. Международная организации по стандартизации (ИСО) узаконила в качестве меры неопределённости измерительной информации не энтропию Шеннона или Неймана-Винера, а обычное среднее квадратическое отклонение измеренной величины от среднего значения [47].
Таким образом, простейшая вероятностная модель источника измерительной (метрологической) информации (ИМИ) содержит следующие пять множеств:
U = {– ∞ < x < ∞} – множество возможных значений измеряемой величины;
D= {Dk} 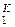 – множество дисперсий погрешностей измерений Dk (здесь k – но-
– множество дисперсий погрешностей измерений Dk (здесь k – но-
мер измерительного прибора);
I = {Ik = 1/Dk} – множество количеств информации, вырабатываемой посредством проведения независимых измерений с помощью одного из K измерительных приборов;
P = {Pk} – множество вероятностей Pk того, что данное измерение проводилось с помощью k-го прибора (или относительное количество – частотность – измерений, проведённых k-м прибором);
X = {Xl(n); n = 1, 2, …; l = 1, 2, …, K n} – множество всевозможных последовательностей (выборок) Xl(n) из n неравноточных независимых измерений.
Здесь имеет место полная аналогия со знаковой (синтактической, дискретной) информацией. Более того, так же, как и в знаковой системе, аддитивность информационной меры метрологической информации (Фишера) соблюдается в том случае, если «грамотно» обрабатывать измерительную информацию: в данном случае – правильно взвешивать результаты отдельных измерений xi, чтобы получить оптимальную оценку, для которой и соблюдаются информационные постулаты.
Это аналогично следующему. Чтобы получить на выходе канала передачи дискретной информации (при наличии в канале КПДС помех), то количество знаковой (синтактической) информации, которое соответствует шенноновским оценкам (см. разд. 9), нужно согласовать источник ДИС с каналом КПДС, выработать соответствующие правила присвоения выходным символам значения первичных знаков и провести соответствующее помехоустойчивое канальное кодирование.
Действительно. Пусть имеется l-я выборка Xl (n) = (xl1, xl2, …, xli, …, xln ) объёма n из результатов экспериментальных данных, которые получены различными авторами с помощью приборов, имеющих различную точность измерения. Какое количество метрологической информации I (Xl(n)) содержится в собранной нами выборке Xl(n)?
Очевидно, что I(Xl(n)) = 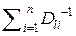 , а среднее количество информации, приходящееся на одно из n измерений,
, а среднее количество информации, приходящееся на одно из n измерений, 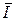 (Xl(n)) =
(Xl(n)) = 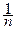 .
.
При достаточно большом значении n >> 1, аналогично выражению для (Si(n)) в разд. 8, получаем: (Xl(n)) ≈ 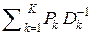 .
.
Величина не зависит от номера l выборки Xl(n) и является собственной информационной характеристикой источника измериттельной (метрологической) информации (ИМИ):{U, D, I, P, X}, которую, по аналогии с источниками знаковых («дискретных») сообщений ДИС, можно назвать средней информативностью результата одного измерения, или удельной информативностью данного источника ИМИ {U, D, I, P, X} и определять её как (U) = .
В таком случае для любой, достаточно объёмной (n >> 1), выборки Xl(n) получаем асимптотическую оценку количества метрологической информации в этой выборке: I(Xl(n)) ≈ n ( U ) = n .
Но величина I(Xl(n)) есть обратная дисперсия оптимальной линейной оценки измеряемой величины x0. Дисперсия DΣ этой линейной оценки асимптотически равна DΣ = ≈ 1/[n (U)].
Если все Dk – одинаковы и равны D, то DΣ ≈ D/n. Этот результат хорошо известен в теоретической метрологии [47] из теории независимых равноточных измерений (аналогия с семиотической мерой Хартли!) и говорит о том, что при n → ∞ дисперсия DΣ линейной оценки = 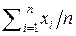 теоретически стремится к нулю.
теоретически стремится к нулю.
Если выборка (x1, x2, …, xi, …, xn) представляет собой статистически связанные между собой случайные величины, то есть результат зависимых неравноточных измерений, то при m = 2 для линейной оценки имеем: b = 0, a1 + a2 = 1 и DΣ = a12 D1 + 2 a1 a2 R12+ a22 D2, где R12 – корреляция случайных величин x1 и x2; 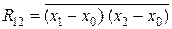 .
.
Обозначая, как и ранее, a1 = a, а a2 = 1 – a, для дисперсии DΣ получаем выражение: DΣ = a 2 D1 + 2 a (1 – a) R12+ (1 – a)2 D2.
Решая уравнение dDΣ /da = 0, получаем

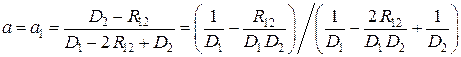 ,
,
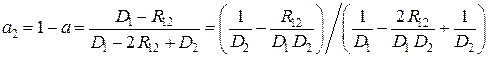 , (11.4)
, (11.4)
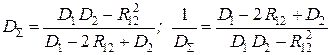 .
.
Если выборку X(2) = (x1, x2) записать в виде числового вектора-столбца x при xТ = || x1, x2 || и ввести в рассмотрение корреляционную матрицу R этого случайного вектора x как R = || 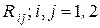 || = ||
|| = || 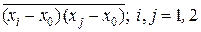 ||, то матрица R–1, являющаяся обратной к корреляционной матрице R, будет иметь
||, то матрица R–1, являющаяся обратной к корреляционной матрице R, будет иметь
вид:
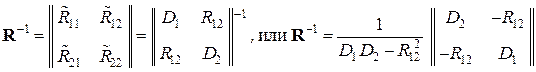 .
.
Сравнивая выражения для членов матрицы R–1 (11.5), а также для вели-
чин a1, a2 и DΣ, видим, что
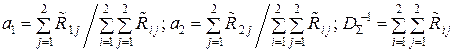 . (11.6)
. (11.6)
Вид выражения (11.6) не зависит от объёма n выборки X(n). Поэтому мы
сразу же можем записать общее решение для произвольного значения n как
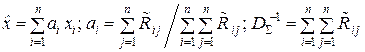 . (11.7)
. (11.7)
где 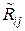 – i j-й член матрицы R–1, обратной к корреляционной матрице R выборки X(n) = (x1, x2, …, xi, …, xn), и доказать справедливость решения (11.7) методом математической индукции по n → ∞.
– i j-й член матрицы R–1, обратной к корреляционной матрице R выборки X(n) = (x1, x2, …, xi, …, xn), и доказать справедливость решения (11.7) методом математической индукции по n → ∞.
При этом каждый коэффициент ai в оптимальной оценке 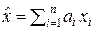 придаёт соответствующему отсчёту xi относительный вес, пропорциональный той измерительной информации, которую несёт данный отсчёт xi об измеряемой величине x0. Величина ai пропорциональна сумме членов i-й строки матрицы R–1, обратной к корреляционной матрице R выборки X(n) = (x1, x2, …, xi, …, xn), а величину
придаёт соответствующему отсчёту xi относительный вес, пропорциональный той измерительной информации, которую несёт данный отсчёт xi об измеряемой величине x0. Величина ai пропорциональна сумме членов i-й строки матрицы R–1, обратной к корреляционной матрице R выборки X(n) = (x1, x2, …, xi, …, xn), а величину 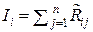 можно рассматривать как количество метрологической информации, которое несёт i-й отсчёт xi об измеряемой величине x0. Тогда в выборке X(n) об измеряемой величине x0 содержится информации
можно рассматривать как количество метрологической информации, которое несёт i-й отсчёт xi об измеряемой величине x0. Тогда в выборке X(n) об измеряемой величине x0 содержится информации 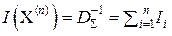 , а величину
, а величину 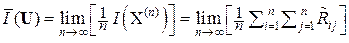 следует называть удельной информативностью данного источника метрологической информации ИМИ. Именно поэтому Р. Фишер в 1921 г. (см. разд. 1) назвал матрицу R–1 информационной матрицей выборки X(n) = (x1, x2, …, xi, …, xn) из генеральной совокупности {x}.
следует называть удельной информативностью данного источника метрологической информации ИМИ. Именно поэтому Р. Фишер в 1921 г. (см. разд. 1) назвал матрицу R–1 информационной матрицей выборки X(n) = (x1, x2, …, xi, …, xn) из генеральной совокупности {x}.
Количество измерительной информации 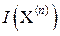 в достаточно объёмной выборке X(n) (n >> 1) асимптотически равно ≈ n
в достаточно объёмной выборке X(n) (n >> 1) асимптотически равно ≈ n 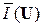 . При этом максимальной информативностью обладают (при прочих равных условиях) ис-
. При этом максимальной информативностью обладают (при прочих равных условиях) ис-
точники ИМИ с независимыми равноточными отсчётами. Проверим это утверждение для случая n = 2.
Если x1 и x2 – независимы, то R12 = 0, и при D1 = D2 = D имеем 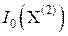 = = 1/D1 + 1/D2 = 2/D. Если R12 ≠ 0, то
= = 1/D1 + 1/D2 = 2/D. Если R12 ≠ 0, то
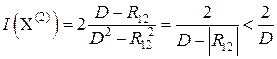 , то есть
, то есть 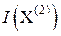 < .
< .
Как видим, имеется полная аналогия с информационной статикой дискретных (знаковых) источников сообщений ДИС (см. разд. 4-8), вплоть до удельной информативности 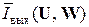 систем ССПИ при наличии в каналах КПДС помех, если
систем ССПИ при наличии в каналах КПДС помех, если
| в качествеколичественной меры Iiизмерительной (метрологической) информациидля выборки из независимых отсчётов принять обратную дисперсию погрешностей измерительного прибора Ii = 1/Di, которая удовлетворяетвсем четырём постулатам прикладной теории информации. |
Это и есть информационная мера Р. Фишера (1921 г.), которая также пред-ставлена на рис. 12.
В многомерном случае ситуация несколько усложняется. Рассмотрим результаты измерения координат объекта (x0, y0) на плоскости (x, y) – например, с помощью радионавигационной системы.
Пусть погрешности измерений распределены по двумерному гауссовскому закону p(x, y). Этот закон характеризуется дисперсиями погрешностей по осям Ox и Oy (Dx = σx2, Dy = σy2), а также коэффициентом корреляции ρxy этих погрешностей.
Самуэль Уилкс (1906-1964) в 1960 г. ввёл понятие обобщённой дисперсии [32]: Dу = | R |, где R – корреляционная матрица порядка m погрешностей измерений по переменным xj ( j = 1, 2, …, m). В двумерном случае дисперсия Уилкса Dу = σx2 σy2 (1 – ρxy2) и равна четвёртой степени радиуса круга rэ (эффективного радиуса рассеяния), равновеликого площади единичного эллипса рассеяния погрешностей измерений: rэ = 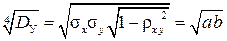 , где a и b – полуоси единичного эллипса рассеяния.
, где a и b – полуоси единичного эллипса рассеяния.
В то же время, информационная мера Неймана-Винера в этом случае
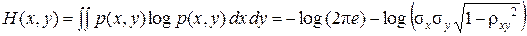 ,
,
то есть h' (x, y) = log rэ– 2.
Эта мера удовлетворяет первым трём постулатам теории информации (см. разд. 3), но не четвёртому – постулату аддитивности.
Однако можно проверить, что мера 1/DУ = rэ– 4 также не удовлетворяет постулату аддитивности.
Действительно. Пусть ρxy = 0. В этом простейшем случае, при наличии двух независимых измерений (x1, y1) и (x2, y2) координат (x0, y0) с дисперсиями (σx12, σy12) и (σx22, σy22), соответствующие оптимальные оценки по осям Ox и Oy проводятся независимо, так что дисперсии σx2 и σy2 оптимальных оценок 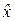 и
и 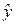 суть: σx2 = 1/(σx1– 2 + σx2– 2), σy2 = 1/(σy1– 2 + σy2– 2).
суть: σx2 = 1/(σx1– 2 + σx2– 2), σy2 = 1/(σy1– 2 + σy2– 2).
При этом эффективные радиусы рассеяния удовлетворяют равенству
rэ14 = σx12 σy12, rэ24 = σx22 σy22, rэ4 = σx2 σy2 = (σx1– 2 + σx2– 2)– 1 (σy1– 2 + σy2– 2)– 1,
или 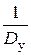 =
= 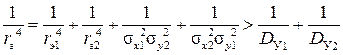 .
.
Это можно объяснить тем, что в одномерном случае из любого конечного числа отрезков произвольной длины всегда можно составить отрезок суммарной длины; в двумерном случае – из конечного числа квадратов далеко не всегда можно составить квадрат суммарной площади, а в трёхмерном случае – куб суммарного объёма.
Вернёмся к одномерной метрологической информации. Мы видели, что,
несмотря на погрешности измерений некоторой величины 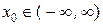 , с ростом количества n независимых измерений X(n) = ( x1, x2, …, xi, …, xn ) количество измерительной информации в выборке I(X(n)) растёт аддитивно и при оптимальной обработке результатов измерений соответствующая дисперсия оптимальной линейной оценки величины x0 уменьшается до бесконечно малой величины: → 0 при n → ∞.
, с ростом количества n независимых измерений X(n) = ( x1, x2, …, xi, …, xn ) количество измерительной информации в выборке I(X(n)) растёт аддитивно и при оптимальной обработке результатов измерений соответствующая дисперсия оптимальной линейной оценки величины x0 уменьшается до бесконечно малой величины: → 0 при n → ∞.
Однако если учесть, что шкала измерительного прибора проградуирована с определённым шагом дискретности Δx, а аналого-цифровые преобразователи имеют конечную разрядность (цену деления шкалы Δx), то возникает вопрос, c какой предельно достижимой точностью можно измерить величину x0 в результате достаточно большого количества многократных независимых измерений (проблема округления)?
Пусть некоторая действительная величина измеряется с помощью прибора, проградуированного с шагом дискретности Δ x или выдающе-го результаты измерений с округлением по правилу 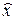 = [x/Δx + 0,5] Δ x, где символ [ y ] обозначает целую часть некоторого действительного числа y. Поскольку мы заранее, естественно, не знаем значения величины x0 с достаточной точностью, то можно считать, что в пределах цены деления xI < x0 ≤ xII априорное распределение неизвестной величины x0 является равномерным (см. рис. 13).
= [x/Δx + 0,5] Δ x, где символ [ y ] обозначает целую часть некоторого действительного числа y. Поскольку мы заранее, естественно, не знаем значения величины x0 с достаточной точностью, то можно считать, что в пределах цены деления xI < x0 ≤ xII априорное распределение неизвестной величины x0 является равномерным (см. рис. 13).
Поэтому если в качестве результата однократного измерения величины x0 мы получили значение x1 = xI, то величина x0 имеет апостериорное распределение pI(x), приблизительно равномерное в пределах промежутка:
(xI – Δ x/2) < x ≤ (xI + Δ x/2).
 p(x)
p(x)

pI(x)
p0(x)

Δ x

Дата добавления: 2015-05-16; просмотров: 1114;