Кодирование переменных
После того как в файл SPSS помещена таблица с данными по исследованию, следует перейти к очередному этапу формирования базы данных — кодированию переменных.
Если данные вводились в SPSS методом импорта, вы увидите только имена переменных и их значения. В этом случае кодирование переменных является обязательным шагом и должно проводиться сразу после процедуры импорта. Если для
ввода данных в SPSS использовалась программа Data Entry, все переменные и их значения окажутся, скорее всего, уже закодированными (на этапе генерирования пользовательских форм). При ручном вводе картина может быть такой, как при импорте данных из других источников (если вы предварительно не производили кодирование), либо аналогичной использованию Data Entry. Тем не менее, независимо от способа ввода, на этапе кодирования необходимо произвести ревизию имеющихся переменных и меток их значений — чтобы удостовериться, что в будущем при проведении статистического анализа все используемые величины будут названы осмысленными именами.
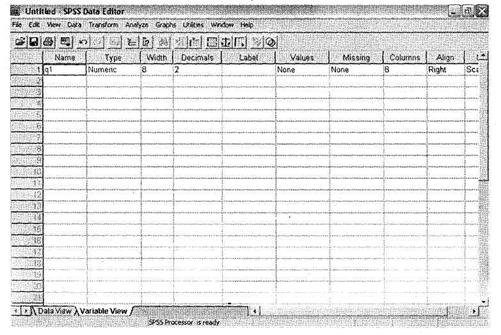
Основное рабочее окно SPSS (см. рис. 1.1) содержит специальные вкладки для перемещения между видом файла данных (Data View) и таблицы переменных (Variable View). Кодирование переменных осуществляется на вкладке Variable View. Общий вид окна программы после щелчка на вкладке Variable View показан на рис. 1.121.
 |
|
Если в данную таблицу ввести какую-либо переменную (поле Name), все остальные ее поля будут заполнены автоматически значениями по умолчанию. После импорта данных из другой программы все полученные переменные будут представлены также значениями по умолчанию (сохранятся только имена переменных). Рассмотрим более детально структуру таблицы Variable View.
Первое поле таблицы Name предназначено для ввода имени переменной, которое должно состоять только из латинских букв и цифр; имя переменной не может начинаться с цифры. При импорте данных из другого источника данное поле заполняется теми значениями, которые были указаны в исходной базе данных. Все остальные поля рассматриваемой таблицы заполняются программой автоматически, причем SPSS сама определяет, к какому типу относится та или иная переменная, а в качестве меток дублирует имена переменных.
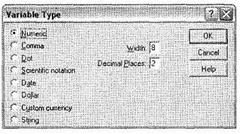
Поле Туре служит для указания типа переменной. Установленный по умолчанию тип Numeric можно изменить, установив курсор в данную ячейку и щелкнув на появившейся кнопке со значком .... Доступные типы переменных представлены на рис. 1.13. Для некоторых из них (например, Numeric) необходимо задать количество используемых разрядов (или букв — для текстовых переменных) и цифр после запятой, а для других (например, Date) — шаблон, по которому отражаются значения.
 |
|
Поле Width служит для указания количества разрядов (для числовых переменных) или букв (для текстовых переменных), если они не были указаны в диалоговом окне указания типа переменной. Следующее поле Decimals позволяет указать количество цифр после запятой для числовых переменных.
Поле Label служит для задания метки переменной. Данное поле важно, так как именно указанные в нем значения появляются на графиках и в таблицах при проведении всех видов статистического анализа. В анкетах, используемых при проведении маркетинговых исследований, содержатся как одновариантные вопросы (респонденты могут указать только один вариант ответа), так и многовариантные (респонденты могут указать несколько вариантов ответа). При этом если одновариантные вопросы обычно представляются одной переменной, которая может принимать столько значений, сколько имеется вариантов ответа, то многовариантные вопросы, как правило, кодируются количеством одновариантных переменных, равным числу вариантов ответа. Каждая такая одновариантная переменная всегда принимает только два значения (дихотомии) — отмечено/не отмечено, которые кодируются соответственно двумя цифрами (обычно 1 и 0). Более подробно схема работы с многовариантными переменными описана в разделе 2.2, мы отметим лишь способ кодирования различных переменных.
Так, при кодировании одновариантных переменных поле Label используется для указания формулировки вопроса анкеты (варианты ответа кодируются в другом поле). При кодировании многовариантных переменных, представленных вариантами ответа, формулировка самого вопроса не отражается в рассматриваемой таблице: кодируются только варианты ответа (дихотомические переменные).
Приведем пример. У нас есть одновариантный вопрос Укажите пол респондента — это формулировка данного вопроса, и она отражается в поле Label, а переменной присваивается имя по принципу ql. Формулировка многовариантного вопроса Что для Вас наиболее важно при выборе велосипеда? не будет фигурировать в таблице Variable View. Вместо нее будет указан набор одновариантных дихотомических переменных (по числу вариантов ответа). В поле Label будут указаны названия вариантов ответа, а в поле Name — имена переменных, кодирующие каждый из вариантов ответа (например, переменная q2_l — Цена велосипеда; q2_2 — Качество велосипеда и т. д.).
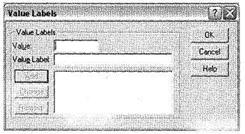 |
Поле Values предназначено для указания вариантов ответа в одновариантных вопросах. Общий вид соответствующего диалогового окна представлен на рис. 1.14. Данное поле не заполняется для многовариантных переменных. В окне Value Labels в поле Value указываются числовые коды вариантов ответа, а в поле Value Label — вербальные формулировки вариантов ответа. При задании меток необходимо предлагать разумные варианты ответов, учитывая, что впоследствии именно эти названия (в том же виде) будут фигурировать на графиках и в аналитических таблицах. Например, вариант ответа на вопрос о половой принадлежности респондента следует называть не Мужской или Женский, а Мужчины или Женщины. Также при наименовании переменных и вариантов ответа следует избавляться от лишних слов, как то: предлоги в начале предложения, междометия, вводные слова. Это, с одной стороны, позволит сократить само название, что в дальнейшем облегчит его восприятие, а с другой стороны, избавит таблицы и диаграммы от массы ненужной информации. Итак, наша основная рекомендация при наименовании переменных — формализация названий.
|
Поле Missing используется редко, так как не несет существенной смысловой нагрузки. В нем можно указать, какие коды следует исключить из анализа (присвоить им статус System Missing). По умолчанию все отсутствующие значения (пропущенные одновариантные вопросы или неотмеченные варианты ответа многовариантных вопросов) представляются в SPSS как System Missing и отражаются для числовых переменных символом,.
Также при помощи поля Missing можно наглядно продемонстрировать разницу между различными типами пропущенных значений — типа «user missing» (значения, специально пропущенные исследователем) и типа «system missing» (значения, которые в принципе должны были присутствовать, но которых не оказалось в базе данных в связи с причинами случайного характера, — в том числе и динамически, не меняя структуры базы данных. Предположим, что для исследования нам нужны только люди с доходом свыше $ 500. Тогда в начале анкеты мы зададим респондентам фильтрационный вопрос (закрытый): Укажите Ваш примерный среднемесячный доход в расчете на 1 члена семьи. При этом респондент может выбрать один из пяти вариантов ответа:
1. до $500;
2. от $ 500 до $ 1000;
3. от $1000 до $1500;
4. свыше $1500;
5. отказываюсь отвечать.
Очевидно, что для дальнейшего анализа нам подходят только те респонденты, которые указали варианты ответа 2-4. Теперь эти три варианта ответа, которые необходимы нам для построения линейных и перекрестных распределений, мы заносим в поле Values, а оставшиеся два — 1 и 5 — в поле Missing. Два последние варианта исключаются из дальнейшего анализа и будут представляться как значение System Missing. Впоследствии, если мы захотим, например, построить общее линейное распределение по всему фильтрационному вопросу (включая все категории), нужно будет просто убрать два пропущенных (в терминологии SPSS — User Missing) значения из поля Missing и добавить их в поле Values. Поле Columns служит для указания ширины столбца при отображении переменной в окне Data View. Следующее поле Align предназначено для выбора выравнивания значений переменной в столбце: по правому краю (Right), по левому краю (Left) или по центру (Center).
Поле Measure является для SPSS единственной возможностью определить тип шкалы имеющихся переменных: номинальная (Nominal), порядковая (Ordinal) или интервальная (Scale). Как показано далее в разделе 2.5 «Статистический анализ данных», важно знать, к какому типу шкалы относится та или иная переменная в базе данных. От этого во многом зависит выбор используемой статистической процедуры. Ниже приведена краткая характеристика трех типов шкалы переменных, используемых в SPSS.
1. Номинальные переменные (Nominal) могут принимать дискретные, не связанные друг с другом значения. Вопросы анкеты, кодируемые номинальными переменными, могут быть как закрытыми (с вариантами ответов), так и открытыми (с текстовым полем вместо прямого указания вариантов ответа). Например, вопрос анкеты Каких производителей мясных полуфабрикатов Вы знаете? с вариантами ответа Царицыно, Черкизовский, Браво и Другое будет закодирован в базе данных SPSS номинальной переменной, так как между вариантами ответа на данный вопрос не существует логического порядка, это просто названия компаний-производителей.
2. Особое место среди номинальных переменных занимают переменные, являющиеся вариантами ответа на многовариантные вопросы или имеющие только два варианта ответа. Тип шкалы данных переменных называется дихотомическим (Dichotomous). Данным переменным в SPSS отводится особая роль, так
как их варианты ответа могут рассматриваться в статистических процедурах как вероятность выбора одной категории или не выбора другой. В качестве вопросов анкеты дихотомические переменные могут кодировать как открытые, так и закрытые вопросы.
3. Порядковые переменные (Ordinal) кодируют такие закрытые вопросы, варианты ответа на которые подчиняются логическому числовому порядку. То есть варианты ответа на такие вопросы представляют собой связанные между собой группы значений. Например, вопрос Как часто Вы покупаете мясные полуфабрикаты? с вариантами ответа: Чаще раза в неделю, Примерно раз в неделю и Реже раза в неделю — кодируется переменной с порядковой шкалой.
4. Интервальными (Scale) являются переменные, не имеющие выделенных категорий. Они содержат числовые данные (например, номер анкеты в базе данных) и кодируют чаще всего открытые вопросы. Интервальные переменные (или другие типы переменных, приводимые к интервальному виду) используются практически во всех статистических процедурах. Они являются основным ресурсом для SPSS.
Дата добавления: 2015-04-25; просмотров: 1340;