Задание для самопроверки 7.1 17 страница
Задание для самопроверки 16.2
Представьте себе, что некто, имеющий уровень способностей, равный 1,0, ответил на три задания, характеристические кривые которых (ХКЗ) даны на рис. 16.3. Каковы приблизительно шансы, что он смо-
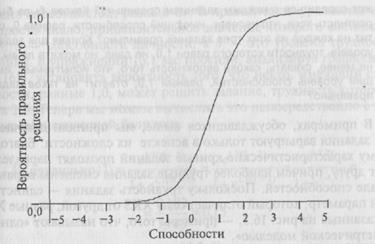
Рис. 16.2. Характеристическая кривая задания, уровень трудности которого составляет 1,0.
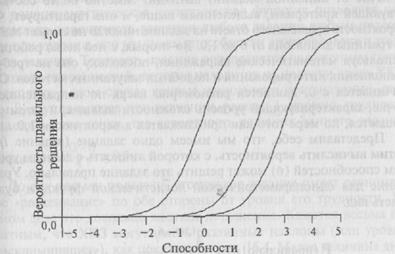
Рис. 16.3. Три характеристических кривых заданий, уровень трудности которых составляет 0, 2, 3.
жет справиться с каждым заданием правильно? Какова была бы вероятность того, что человек, имеющий способности, равные 0, ответит на каждое из этих трех заданий правильно? Кривая для задания, уровень трудности которого равен 1,0, не дана, но можете ли вы, тем не менее, сказать, какова вероятность того, что испытуемый, имеющий уровень способностей, равный 1,0, ответит на такое задание правильно?
В примерах, обсуждавшихся выше, мы приняли допущение, что задания варьируют только в аспекте их сложности. Благодаря этому характеристические кривые заданий проходят параллельно друг другу, причем наиболее трудные задания смещены вправо по шкале способностей. Поскольку трудность задания — единственный параметр, который отличает одну ХКЗ от другой, разные ХКЗ, показанные на рис. 16.3, — примеры того, что называют «однопа-раметрической моделью».
Графики, изображенные на рис. 16.2 и 16.3, могут быть описаны довольно простым математическим уравнением, известным как «логистическая функция». Существует две главные причины для работы с логистической функцией. Во-первых, форма кривой (в отличие от линейной модели) выглядит заметно более соответствующей критериям, выделенным выше, и она гарантирует, что вероятность правильного ответа на задание никогда не сможет выйти за границы диапазона от 0 до 1,0. Во-вторых, с ней легко работать, используя математические выражения, поскольку она не требует выполнения интегрирования и подобных запутанных методов. Она начинается с 0, двигается равномерно вверх по направлению к точке, характеризующей уровень сложности задания, и затем уплощается, по мере того как приближается к вероятности 1,0.
Представим себе, что мы имеем одно задание (задание /) и хотим вычислить вероятность, с которой личность с данным уровнем способностей 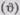 может решить это задание правильно. Уравнение для однопараметрической логистической функции будет иметь вид:
может решить это задание правильно. Уравнение для однопараметрической логистической функции будет иметь вид:
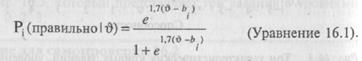
На самом деле оно не так страшно, как кажется на первый взгляд. Левая часть уравнения читается так: «вероятность того, что человек решит задание / правильно при условии, что он имеет
уровень способностей,' равный тЗ». В правой части уравнения е -это просто .число, приблизительное значение которого составляет 2,718; и — способности личности, а Ь. — это уровень трудности задания /'. В упражнении 16.1 вас просили, анализируя графики на рис. 16.3, установить вероятность того, что некто, имеющий способности, равные 1,0, может решить задание, трудность которого равна 2,0. Теперь мы можем вычислить это непосредственно с помощью логистической функции.
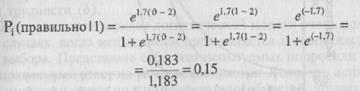
Результат согласуется с рис. 16.3. Единственное, что может создать здесь для вас некоторые проблемы, — это оценка е~''7. Это число можно вычислить с помощью калькулятора или же можно обратиться к математическим таблицам значений ех.
Важный момент, который необходимо усвоить, состоит в том, что однопараметрическая логистическая функция позволяет нам вычислить вероятность решения любого задания любым человеком при условии, что мы знаем способности этого человека и трудность задания. Трудность задания определяется положением точки на шкале способностей, которая находится на полпути вдоль ХКЗ. Поскольку в эхом случае кривые начинаются при значении, равном 0, и уплощаются при значении, равном 1, уровень трудности задания — это точка, где вероятность решения данного задания
составляет 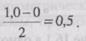
До сих пор мы полагали, что каждое задание имеет равномерное «рассеивание» по обе стороны от уровня его трудности. На самом деле это довольно жесткое допущение. Кажется весьма вероятным, что ХКЗ могут иметь различные наклоны (или уровни «дискриминации»), как показано на рис. 16.4. Малая величина дискриминации указывает на то, что индивидуумы с широким диапазоном способностей имеют обоснованные шансы ответить на задание правильно. Большая величина дискриминации говорит о том, что ХКЗ в значительно большей степени ориентирована вертикально. (Математически искушенный читатель может, вероят-
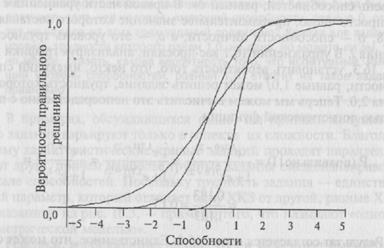
Рис. 16.4. Характеристические-кривые трех заданий.
но, рассматривать параметр дискриминации как точку перегиба на ХКЗ.)
Задание для самопроверки 16.3
Два задания на рис. 16.4 имеют уровни трудности, равные 0. Из них одно задание имеет показатель дискриминации, равный 0,5, а второе имеет показатель дискриминации, равный 1,0. Последнее задание имеет уровень трудности, равный 1,0, и показатель дискриминации, равный 2,0. Можете ли вы установить, какая из кривых связана с каждым из заданий?
Очень легко модифицировать уравнение 16.1 в однопараметри-ческое логистическое уравнение, чтобы принять в расчет второй параметр дискриминации, который обычно обозначается как а,. Модифицированная формула выглядит так:
Рi (правильно 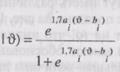 (уравнение 16.2),
(уравнение 16.2),
и, таким образом, вероятность того, что человек, имеющий способности (и), равные 3,0, ответит правильно на задание, имею-
щее трудность (Ц), равную 2,0, и показатель дискриминации (а), равный 0,5, будет составлять:
Pi (правильно 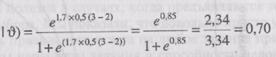
Не следует удивляться, узнав, что эта функция называется двух-параметрической логистической функцией, в которой два параметра определяют каждое задание — показатели дискриминации (аi) и трудности (bi).
Окончательный вариант логистической модели очень полезен в тех случаях, когда испытуемым предъявляется тест множественного выбора. Представьте себе, что испытуемых попросили выбрать правильный ответ из четырех возможных. Ясно, что испытуе-|мый, имеющий очень низкий уровень способностей, угадает правильный ответ (при условии, что четыре альтернативы равно привлекательны) с вероятностью приблизительно 25%, и, таким образом, уровень ХКЗ не должен иметь вероятность, равную 0, а должен находиться на уровне, в большей степени соответствующем указанному выше. Проблема состоит в том, что мы не можем принять утверждение, согласно которому эта величина будет точно равна 0,25, поскольку на практике различные (неправильные) альтернативы не будут обладать абсолютно равной привлекательностью для тех, кто проходит тестирование. Поэтому более предпочтительным будет использование фиксированной величины типа 1/п (где п — число предлагаемых альтернатив), с ее помощью можно точнее установить для каждого задания лучшее положение точек перегиба. «Трехпараметрическая логистическая модель» позволяет нам, таким образом, принимать в расчет вероятность угадывания. Ее вид таков:
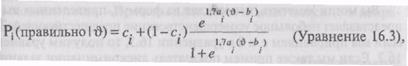
где, как и прежде, а. представляет показатель дискриминации задания, bt — его трудность, а с;. представляет вероятность, с которой респондент, имеющий очень низкий уровень способностей, ответит на это задание правильно. На рис. 16.5 показаны три ХКЗ: одна с величинами д. = 1,0; Ъ. = 0,5 и с. = 0,2, другая с величинами

Рис. 16.5, Три характеристических кривых заданий для трехпараметри-ческой модели.
а.i ~ 0,5; bi — 1,0 и ct — 0,25 и третья — с величинами at = 2,0; bt = 0 к с, «0,125.
Вы можете видеть, как каждая кривая растягивается с левой стороны до значения с., которое, разумеется, допускает вероятность «везения в угадывании». Вам следует с осторожностью устанавливать уровень трудности заданий при работе с трехпарамет-рической моделью, поскольку в этой модели начало ХКЗ не совпадает с вероятностью, равной 0. Если кривая начинается на уровне 0,3 и уплощается при значении, равном 1,0, уровень трудности задания обозначается точкой, в которой вероятность реше-
1,0-0,3 ния задания 0,3 + ——— = 0,65.
Вы могли заметить, что каждая из формул, приведенных выше, представляет небольшое усовершенствование предшествующей. Так, если мы приравняем с. к 0 в уравнении 16.3, то получим уравнение 16.2. Если мы также примем показатель дискриминации задания я, равным 1,0, тогда мы получим уравнение 16.1.
В этом разделе были введены три математические модели, которые, как можно обоснованно ожидать, описывают связи между способностями человека и его вероятной успешностью при решении отдельных заданий теста. Двухпараметрическая модель, воз-
можно, является наиболее подходящей для данных, полученных в тестах свободных ответов, в то время как трехпараметрическая модель может быть полезна в случаях, когда предъявляются тесты множественного выбора. Мы показали, что довольно просто установить вероятность правильного ответа на любое задание при условии, что известны параметры задания и способности человека. Основная цель теории сложности заданий состоит в том, чтобы реализовать эту логику в обратном порядке. Получив ответы индивидуумов на задания теста, теория заданий пытается установить наиболее вероятные значения:
• одного, двух или трех параметров, связанных с каждым заданием, и
• способностей каждого человека.
Определение способностей и параметров задания
Как упоминалось выше, основная цель теории сложности заданий — установить уровень трудности каждого задания в тесте и (одновременно) оценить способности каждого человека, проходящего тестирование. Таким образом, если тест состоит из 20 заданий и анализируются ответы 100 детей, нам необходимо установить 20 показателей трудности заданий, 100 показателей способностей по однопараметрической модели плюс 20 показателей дискриминации, если мы применяем двухпараметрическую модель, и дальше плюс 20 индексов угадывания, если мы выбираем трехпараметри-ческую модель. Каким образом мы должны все это выполнить?
Одна возможность заключается в том, чтобы просто взглянуть на данные. В табл. 16.1 представлены ответы восьми испытуемых на пять заданий теста. «Правильный» ответ обозначается 1, а неправильный — 0.
Упражнение
Потратьте около 5 минут, рассматривая данные в табл. 16.1. Постарайтесь выделить самое трудное и самое легкое задания, а также наиболее способного и наименее способного из испытуемых.
Таблица 16.1 Оценки восьми испытуемых по пяти заданиям теста
| Задание 1 | Задание 2 | Задание 3 | Задание 4 | Задание 5 | |
| Джеймс | |||||
| Шэрон | |||||
| Брайан | Л | ||||
| Линда | |||||
| Майкл | |||||
| Сьюзен | |||||
| Уильям | |||||
| Фиона |
Кажется вероятным, что если мы игнорируем уровни трудности отдельных заданий, то Шэрон и Брайан (с четырьмя правильно решенными заданиями) имеют более высокие оценки по обсуждаемому признаку по сравнению с другими, а Уильям, Линда и Сьюзен имеют низший балл (по одному правильному ответу). Теперь рассмотрим колонки. Какие задания кажутся наиболее трудными? Только один человек (Брайан) ответил правильно на задание 5 и только двое (Джеймс и Шэрон) ответили правильно на задание 4, поэтому логично предположить, что эти два задания — наиболее трудные, а задание 3 (которое только два человека не смогли решить правильно) — легкое.
Теперь рассмотрим способности людей, принимавших участие в решении теста. Оба — и Шэрон, и Брайан — имеют общую оценку 4, и, согласно классической теории тестов, следует считать, что они имеют равные способности. Однако вы можете видеть в табл. 16.1, что это допущение излишне упрощает ситуацию, поскольку мы утверждали раньше, что задание 5 несколько сложнее, чем задание 4. Брайан, таким образом, справился с ответом на более сложное задание правильно, но не смог решить более простое. Шэрон ответила на более легкий тест правильно, но не смогла решить более сложный. Поэтому кажется оправданным считать, что Брайан должен иметь более высокую оценку по этой черте, чем Шэрон.
Упражнение
Сравните оценки, полученные Джеймсом и Фионой. Как вы думаете, кто'из них более способный и почему?
Критический пункт, который необходимо иметь в виду в этом случае, состоит в том, что, когда мы оцениваем уровень трудности заданий, мы пытаемся учитывать способности респондентов, и наоборот. Приблизительным и неформализованным способом мы пытаемся установить (разумеется, разобравшись в сути дела) -будет ли оценка способностей человека независимой от уровня трудности заданий теста, которые предъявлялись. Подобным образом мы пытаемся установить трудность каждого задания, принимая в расчет различия в способностях респондентов.
Принципиально важно помнить следующее положение: теория сложности заданий ставит целью измерять способности независимо от трудности конкретных заданий, которые предъявлялись. Она также стремится установить параметры задания — трудность/ дискриминацию/угадывание — способом, который совершенно не зависит от особенностей выборки индивидуумов, которым пришлось проходить тестирование. Это значительно контрастирует с классической теорией тестирования, в которой оценка человека рассматривается как показатель его способностей, и это полностью смешивается с различиями в трудности заданий теста. Один и тот же показатель может быть получен высокоспособным студентом, которому предъявлялись трудные задания теста, или студентом с низким уровнем способностей, которому предъявлялись легкие задания.
Выше я доказывал, что характеристическая кривая задания (ХКЗ) показывает вероятность выполнения определенного задания теста индивидуумами с различными уровнями способностей. По-видимому, можно написать компьютерную программу, которая проводила бы грубую прикидочную оценку способностей различных людей (возможно, на основе количества правильно выполненных заданий) и затем, зная эти способности, устанавливала бы уровни трудности каждого задания. Тот же процесс можно было бы в последующем повторить в обратном порядке, когда способности студентов устанавливаются на основе статистических данных о трудности заданий. Этот процесс можно было бы повторять раз за разом, добиваясь лучших оценок способностей и параметров задания на каждой стадии до тех пор, пока оценки спо-
собностей студентов и трудности заданий дальше уже нельзя будет улучшить. Другими словами, такая программа могла бы попытаться найти наиболее подходящие величины для всех параметров задания и способностей. Сваминатан ч Гилфорд (Swaminathan, Clifford, 1983) показали, что, когда количество заданий и испытуемых достаточно велико, оценки параметров, получаемых таким способом, весьма близки к их подлинным значениям в одно-и двухпараметрической моделях, но в трехпараметрической модели это весьма проблематично.
Представленная подобным образом, эта процедура выглядит довольно просто, хотя статистическое и численное установление этих параметров может быть чрезвычайно сложным процессом. Вам не следует слишком беспокоиться по поводу деталей. Для выполнения подобного анализа было написано несколько компьютерных программ. LOGIST (Wingersky et al.t 1982), RASCAL, RSP, XCalibre ASCAL (Assessment Systems Corporation, 1989) являются программами, которые пытаются установить эти личностные параметры и параметры заданий с помощью разнообразных методов. Важным моментом, который необходимо усвоить, является то, что эти программы могут одновременно оценивать и способности индивидуумов, и параметры различных заданий. Они также обеспечивают статистику, которая показывает, насколько близко определенная модель соответствует полученным данным, например, они позволяют определить, будет ли адекватной двухпараметри-ческая логистическая модель или необходимо также вычислить параметры угадывания для каждого задания.
Продемонстрировать, что эти программы действуют в значительной степени так же, как и анализ, основанный на нашем здравом смысле, можно, обратившись к табл. 16.2. Она представляет оценки способностей и трудности заданий, которые были получены при анализе данных, взятых из табл. 16.1, с использованием двухпараметрической логистической модели. ХКЗ, соответствующие данным табл. 16.2, представлены на рис. 16.6. Не принимайте эти результаты слишком серьезно — обычно считается необходимым основывать такой анализ на выборках из нескольких сотен человек и на тестах, включающих более пяти заданий.
Однако из табл. 16.2 действительно следует, что программы, по-видимому, дают результаты, которые в широком плане соответствуют нашим предшествующим ожиданиям. Вам следует самим убедиться, что результаты таблицы совпадают с нашим более ранним «визуальным» анализом данных.
Рис. 16.6. Характеристические кривые заданий, данных в табл. 16.2.
Таблица 16.2
Оценки трудности заданий и способностей по данным,
представленным в табл. 16.1, базирующиеся на
двухпараметрической логистической модели
| Способности | Задание | Трудность | Дискриминация | |
| Джеймс | 0,424 | -0,534 | 1,440 | |
| Шэрон | 0,915 | -0,531 | 1,004 | |
| Брайан | 1,026 | -0,956 | 1,609 | |
| Линда | -0,943 | 0,970 | 1,317 | |
| Майкл | -0,376 | 1,474 | 1,565 | |
| Сьюзен | -0,733 | |||
| Уильям | -0,79 | |||
| Фиона | 0,264 |
Заканчивается этот раздел предостережением. Как и многие другие статистические методики, программы, которые оценивают параметры заданий и способности, почти всегда выдают только
ответы, и среди пользователей существует сильно выраженная тенденция просто сообщать эти ответы, не слишком заботясь о том, насколько выбранная модель (т.е. одно-, двух- или трехпараметри-ческая логистическая модель) действительно соответствует полученным данным. Если такого соответствия нет, тогда все, что мы говорили выше об инвариантности (независимости) способностей относительно параметров задания, просто оказывается неприменимым и задания теста будут непригодны. Хэмблтон с соавторами (Hambleton et а/., 1991, ch. 4) представляет хорошее обсуждение этого принципиально важного вопроса.
Преимущества
теории сложности заданий
Замечательной особенностью теории сложности заданий является то, что оценки способностей индивидуумов отделены от характеристик (сложности, дискриминации и угадываемости) конкретного набора заданий, который предъявлялся. Мы ожидаем получить совершенно те же оценки способностей, независимо от того, какие именно наборы заданий предъявлялись испытуемым. Это очень непохоже на традиционное тестирование, в котором тестовые оценки можно интерпретировать только по сравнению с нормами, получение которых является дорогостоящей процедурой, кроме того, трудность задания и т.п. также зависит от характеристик выборки, которой предъявляется тест.
Например, представим себе, что задание словарного теста предъявлялось случайной выборке людей. Мы можем обнаружить, что правильно отвечают на задание 50% выборки. Теперь вообразите себе, что мы присоединили к выборке довольно большое количество студентов университета — людей с высоким уровнем способностей, большинство из которых смогут ответить на задание правильно. Поскольку выборка включает непропорционально большое количество испытуемых с высоким уровнем развития вербальных навыков, мы можем теперь обнаружить, что во второй выборке правильно ответят на задание 80% испытуемых. Таким образом, традиционные показатели трудности задания (р-значе-ния) могут изменяться соответственно составу выборки. С теорией сложности заданий такого не случается. При условии, что в выборке существует хорошее распределение способностей, оцен-
ки трудности задания совсем не будут зависеть от того, сколько испытуемых приходится на каждый уровень способностей. Именно это и означает — оценить трудность задания независимо от способностей. Точно такая же логика сохраняется и для других показателей задания — дискриминации (а) и угадывания (с.). Это делает весь процесс конструирования теста намного более легким, поскольку исчезает необходимость тратить время на прослеживание случайных выборок испытуемых, в которых производится оценка параметров задания. Любая удобная группа людей подойдет при условии, что в ней имеется необходимый разброс способностей. Количество же людей, находящихся на каждом уровне способностей, не будет влиять на оценки параметров задания.
Что можно сказать о процессе оценивания способностей индивидуумов на основе заданий теста? В значительной степени то же самое. Используя теорию сложности заданий, мы можем предъявлять любой подходящий набор заданий, чтобы получить оценки способностей респондентов, при условии, что все характеристические кривые заданий не собираются в пучок в одной точке, т.е. при условии, что некоторые из заданий различаются на каждом уровне способностей. Если дело обстоит так (как оно обычно и бывает при условии, что задания значительно варьируют по трудности и имеют низкие или умеренные параметры дискриминации), можно оценить способности респондентов, совсем не беспокоясь по поводу количества заданий на каждом уровне трудностей.
Когда оценка способностей проводится с помощью традиционного теста, где количество заданий, на которые были получены правильные ответы, определяет оценку способностей респондентов, очевидно, что количество легких и трудных заданий в тесте будет влиять на оценки способностей. Респонденты, выполняющие тест, в котором большинство заданий легкие, будут получать более высокие общие оценки," чем респонденты, выполняющие тест, в котором большинство заданий трудные. Это не составляет проблему для показателей способностей, получаемых в теории сложности заданий. Поскольку эти показатели способностей статистически отделены от показателей трудности заданий теста, число вопросов на каждом уровне трудности реально не имеет значения.
Тем не менее некоторые задания оказываются более полезными по сравнению с другими для сбора информации о способно-
стях конкретного человека. Рассмотрим рис. 16.7. Представьте себе, что кто-то не выполнил задания С и D, но справился с заданиями А и В. Кажется закономерным предположить, что способности испытуемого находятся где-то между 0 и 1, но будет трудно установить точно, где именно, поскольку в этом диапазоне способностей вероятность правильного ответа испытуемого на любые задания в каждом случае очень близко приближается либо к 1, либо к 0. Следовательно, должна быть значительная по величине ошибка измерения, связанная с оценкой способностей в этом диапазоне.
Можно показать, что задания теста, уровни трудности которых более всего соответствуют способностям человека, задания, которые имеют крутые наклоны (т.е. высокие параметры дискриминации) и у которых параметр угадывания оказывается наиболее низким, обеспечивают наиболее полную и точную информацию о способностях респондента. Лорд и Новик (Lord, Novick, 1968) показали, что можно вычислить «информационную функцию задания», статистическую характеристику, описывающую диапазон способностей, для которого каждое задание обеспечивает полезную информацию. Если вы когда-либо захотите вычислить ее, то формула такова:
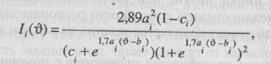
где левая часть уравнения читается; «информация, полученная с помощью задания i (имеющего показатели дискриминации, трудности и угадывания аi, bi, и сi)при уровне способности г?». Таким образом, если мы установили три параметра задания, мы можем теперь выяснить, насколько вероятно получить какую-либо полезную информацию об определенном уровне способностей. Более того, достаточно легко установить уровень способностей, при котором определенное задание выдает наибольшую информацию о способностях.
Следовательно, если бы мы вычислили информационную функцию для четырех заданий, представленных на рис. 16.7, это показало бы, что ни одно из них не способно дать существенную информацию в интервале от 0 до 1. Таким образом, информационные функции заданий являются удобным способом вычисления
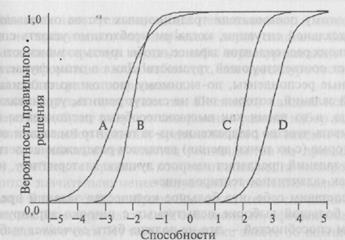
Рис. 16.7. Четыре ХКЗ, дающие мало информации о способностях в диапазоне между 0 и 1.
того, что очевидно из рис. 16.7: чтобы получить точные оценки способностей, требуются сильно различающиеся задания с уровнями сложности, близкими к подлинному уровню способностей человека, проходящего тестирование. Установление уровня способностей человека включает определение того, какие задания (известной трудности и т.д.) он может обычно выполнить правильно и какие ему точно не удастся выполнить. Уровень его способностей находится где-то между показателями трудности этих двух наборов заданий. Отсюда следует, что как очень трудные, так и очень легкие задания скажут нам о подлинных способностях человека немного. Но задания, которые подвергают человека испытанию на пределе возможностей, позволяют нам точно установить, каковы его способности.
Адаптивное тестирование
Традиционные тесты способностей обычно адресуются относительно узкому диапазону оценок способностей, чтобы избежать возникновения у респондентов чувства подавленности, когда предъявляется много очень трудных заданий, или скуки при столкновении с большим количеством слишком легких заданий. Бла-
годаря этому пользователи традиционных тестов оказываются в парадоксальной ситуации, когда им необходимо угадать способности своих респондентов заранее, чтобы иметь возможность выбрать тест соответствующей трудности! Даже в этом случае менее способные респонденты, по-видимому, постоянно сталкиваясь с чередой заданий, которые они не смогут решить, утрачивают мотивацию, в то время как высокоспособные респонденты могут испытывать чувство раздражения из-за того, что им задают вопросы, которые (с их точки зрения) являются раздражающе легкими. Теория заданий предлагает намного лучшую альтернативу, известную как «адаптивное тестирование».
Представим себе, что большое количество заданий предъявляется большой выборке испытуемых с широко варьирующим уровнем способностей — это не должна быть случайная выборка. Параметры заданий устанавливаются с помощью одной из программ, упоминавшихся выше, возможно, использующих двухпа-раметрическую или трехпаhаметрическую логистическую модель. Предположим также, что выбранные модели обеспечивают хорошее общее соответствие данным. Теперь мы располагаем большими возможностями, поскольку сравнительно просто перевести задания теста в компьютер и написать компьютерную программу, которая будет предъявлять испытуемому по одному заданию теста за один раз.
Сначала мы можем предъявить задание небольшой или умеренной трудности. Если конкретный респондент окажется не в состоянии выполнить его правильно, можно выбрать другое, более легкое. Если испытуемый ответит на него правильно, программа может идентифицировать более трудную задачу, используя информационную функцию задания, чтобы определить, какие задания будут давать максимальную информацию о способностях человека, — и это будет продолжаться до тех пор, пока программа, наконец, точно не определит, какие задания испытуемый может выполнить правильно, а какие (более трудные) ему просто не по силам. По мере того как будет собираться все больше и больше данных, компьютерная программа сможет предугадывать с возрастающей точностью, какие из еще не использованных заданий испытуемый будет способен выполнить правильно, а какие выполнить не удастся. Такая процедура позволяет установить способности человека очень быстро. Опыт проведения такого рода тестов показывает, что задания обычно должны быть близки к пределу
Дата добавления: 2015-03-03; просмотров: 657;