Рестрикционное картирование
Сейчас известно и доступно для применения множество типов рестрикционных ферментов. Они разрезают ДНК на различные последовательности, и их можно использовать для анализа структуры ДНК и составления хромосомных карт методом рестрикционного картирования. На рестрикционной карте отмечено относительное расположение участков {сайтов рестрикции), которые вырезают различные нуклеазы. С помощью других методов можно сопоставить эту карту с генетической картой. В данном случае применяют технологию электрофореза, описанную во вставке (с. 216—218), с помощью которой разделяют ДНК на фрагменты и определяют их относительный размер. Рестрикционное картирование лучше объяснить на примере. У многих вирусов животных имеются маленькие кольцевые ДНК. Предположим, мы выделили ДНК вируса длиной в четыре килобазы (kb) и порезали ее ферментом ЕсоRI на фрагменты. Пропустив их через гель, мы определили их длину: 0,4; 0,8; 1,3 и 1,5 kb. Это значит, что в геноме находится четыре участка рестрикции EcoRl, которые могут располагаться по-разному.
Порежем вирусную ДНК снова при помощи EcoRI, но на этот раз уменьшим время обработки ДНК ферментом, чтобы некоторые ДНК были порезаны не полностью. Наряду с прежними четырьмя фрагментами получаем новые фрагменты длиной 1,7; 1,9; 2,1 и 2,3 kb. Небольшой перебор вариантов показывает, что эти фрагменты располагаются в следующем порядке:
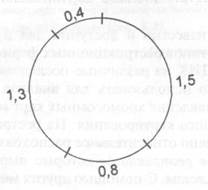
Можно подтвердить такое расположение, выделив более крупные фрагменты, порезав их EcoRIи убедившись, что они в итоге разрезаются на те же малые фрагменты.
Далее обработаем ту же вирусную ДНК ферментом SaiI, в результате чего получим фрагменты длиной 0,95; 1,25 и 1,8 kb. Получается, что в этой ДНК три участка SaiI. Затем выделим эти фрагменты и порежем их EcoRI:
фрагмент 0,95 kb → 0,1 kb + 0,85 kb;
фрагмент 1,25 kb→0,2 kb + 0,4 kb + 0,65 kb;
фрагмент 1,8 kb→0,7 kb + 1,1 kb.
Перебор вариантов показывает, что участки SaiIрасполагаются относительно участков EcoRIследующим образом: 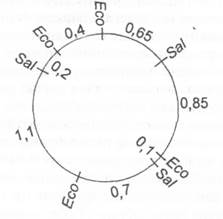
Если полученных данных недостаточно для определения взаимного расположения участков, то можно еще раз порезать фрагменты одним ферментом, а затем другим, или, допустим, порезать ДНК при помощи сначала EcoRI, а затем SaiI. После этого можно применить третий фермент и определить расположение его участков рестрикции относительно первых двух. Это очень простой пример. На практике дело обстоит гораздо сложнее даже в случае с самыми маленькими вирусами, которые требуют более сложных схем анализа, но принцип анализа сохраняется.
Эту же технологию можно применять для диагностики наследственных нарушений по ДНК зародышевых клеток. Обнаружилось, что фермент Hpal режет нормальную ДНК на фрагменты одной длины, а ДНК с аллелями серповидноклеточной анемии гена бета-гемоглобина — на фрагменты другой длины; в 87% случаев серповидноклеточной анемии получаются более длинные фрагменты. Это значит, что дефектный участок гена с мутацией HbS не соответствует последовательности фермента Hpal. При помощи этого метода возможно определять 87% случаев серповидноклеточной анемии непосредственно на стадии эмбрионального развития.
Рестриктазы используют и в других анализах. Во всех биологических видах наблюдается некоторое разнообразие в последовательности ДНК различных особей, и иногда такое разнообразие приводит к удалению или вставке дополнительных участков рестрикции. Обычно это нейтральные вариации, не оказывающие влияния на фенотип (в отличие от вариации гена гемоглобина). Такие вариантные участки оказываются весьма полезными при составлении карт, потому что они говорят об альтернативной форме хромосомы с наличием или отсутствием дополнительного участка рестрикции:

Молекулярный анализ легко обнаружит эти различия, потому что если эту последовательность ДНК разных индивидов порезать рестриктазой, то в одном случае получится один длинный фрагмент, а в другом — два коротких, общая длина которых соответствует длине первого. Таким образом выявляются два морфа в популяции: у некоторых индивидов имеется дополнительный участок рестрикции, а у других его нет. Такое явление называется полиморфизмом длины рестрикционных фрагментов (RFLP— restriction fragment length polymorphism). Его полезно учитывать при составлении карт, потому что этот полиморфизм служит нейтральным гетерозиготным маркером, с помощью которого можно определять близлежащие гены, особенно при составлении карт маркеров, приводящих к разным фенотипам. Кроме того, если RFLP расположен близко от дефектного аллеля, то его можно использовать для обнаружения этого аллеля подобно участку рестрикции внутри гена гемоглобина. В геноме встречаются и другие типы нейтральных вариаций последовательности, и RFLP оказался первым среди открытых учеными. Все они могут быть использованы для составления карт и обнаружения рецессивных дефектных аллелей.
Глава девятая РАСШИФРОВКА КОДА ЖИЗНИ
Как только Уотсон и Крик предложили свою модель ДНК, ученые поняли, что линейная последовательность оснований ДНК составляет ряд ключевых слов, или кодонов, соответствующих линейной последовательности аминокислот в белках. Кроме того, как заметил Крик, поскольку и ДНК, и белки представляют собой линейные последовательности элементов, обе последовательности должны быть колинеарными. Это значит, что первый кодон гена должен кодировать синтез первой аминокислоты, второй ген — второй аминокислоты и т. д. Оставалось только логически выяснить, какие именно сочетания четырех оснований A, G, С и Т образуют эти кодоны.
Белки состоят из 20 видов аминокислот. Предположим, что кодону соответствуют последовательности из двух оснований, например АА или СТ. Так как оснований всего четыре, получается: 4 х 4 = 16 сочетаний. Этого недостаточно для 20 аминокислот. Далее предположим, что кодон — это триплет, то есть последовательность из трех оснований. Теперь получается: 4 х 4 х 4 = 64 сочетания, то есть больше 20. В таком случае либо 44 триплета являются бессмысленными, либо мы имеем вырожденный код. Термин «вырожденный код» обозначает код, в котором разные знаки могут иметь одно и то же значение. Некоторое время серьезно обсуждался и другой механизм кодирования, в котором одни основания могли передавать код, а другие — служить «запятыми», отделяющими одни ко-доны от других.
Как узнать, какая из предложенных схем верна? Крик с коллегами провел серию блестящих опытов на мутантах rII фага Т4, потому что мутанты и дикие типы фагов отличить друг от друга легко (вспомним, что мутанты rII не растут на штамме К). В экспериментах применялся мутагенный краситель профлавин, молекулы которого вставляются между парными основаниями двойной спирали ДНК. При репликации и рекомбинации получаются молекулы со вставкой или с удалением нескольких нуклеотидов. Для простоты будем считать, что каждая мутация в результате действия профлавина вставляет или удаляет только одно основание.
Не осознавая этого при чтении текста, мы пользуемся так называемой рамкой считывания. Это своего рода прямоугольник, который передвигается вдоль слов, определяя их границы, обозначенные пробелами. Рамка постоянно сужается или раздвигается в зависимости от длины слова, но если предположить, что все слова состоят, например, из 3 букв, то ширина рамки будет постоянной. С помощью такой рамки легко прочитать следующие осмысленные слова:
КОТ ТОМ ЕЩЕ МАЛ УХО УСЫ НОС,
даже если между ними не будет пробелов. Теперь предположим, что в одно из слов попала лишняя буква; тогда рамка считывания сдвинется и получатся слова:
КОТ ТОМ СЕЩ ЕМА ЛУХ ОУС ЫНО С
и так далее. После вставки получаются бессмысленные слова, но какой-то смысл восстановить можно, если компенсировать вставку удалением другой буквы, возвращающим рамку считывания в нормальное положение:
КОТ ТОМ СЕЩ ЕМЛ УХО УСЫ НОС.
По крайней мере, можно прочитать слова «ухо», «усы» и «нос», несмотря на бессмыслицу в середине фразы.
Приблизительно так же в ДНК строится последовательность кодонов из трех оснований, и мутация со сдвигом рамки может переместить рамку считывания в том или другом направлениях, которые мы обозначим как П и Л (правая и левая стороны). Именно из этого исходили Крик и его коллеги, приступая к экспериментам. Они начали с одного вызванного профлавином мутанта под названием FC0, произвольно обозначив его как вызывающий сдвиг в направлении П. Потом они смогли выделить компенсирующих мутантов Л. Так как FC0 является мутантом гII, он не может расти на штамме К; но если фаги FC0 еще раз подвергнуть мутации посредством профлавина и поместить их в среду со штаммом К, то некоторые фаги образуют стерильные пятна, потому что у них произошла компенсирующая мутация Л. Такую вторую мутацию называют супрессорной (подавляющей), или супрессором. Супрессор — это мутация, которая компенсирует эффект другой мутации. Так ученые выделили ряд супрессоров (обозначив их как FC1, FC2 и т. д.) и скрестили двойные мутанты (имеющие одновременно мутации П и Л) с дикими фагами, изолировав Л-мутантов. Так как FC1, FC2 и другие все были Л-мутантами, то их супрессоры по определению должны были быть П-мутантами. Так, передвигаясь «взад» и «вперед», Крик с коллегами получили ряд П-мутантов и ряд Л-мутантов.
Уже сама возможность выделять таких мутантов подтверждает истинность модели, но нужно было провести еще два важных опыта. Во-первых, любой Л-мутант должен был подавлять любого П-мутан-та (по крайней мере, если их участки располагаются близко друг от друга), а группа Крика получила много таких парных комбинаций. Ученые обнаружили, что за несколькими исключениями двойные мутанты, содержащие по одной П- и Л-мутации походили на фагов дикого типа. Но самым впечатляющим был эксперимент с получением тройной Л- или П-мутации. Легко доказать, что если код действительно состоит из триплетов, то сдвиг на три буквы влево или право восстанавливает рамку считывания. Именно так и получилось: тройной П- или Л-мутант обычно имели дикий фенотип, если мутации происходили близко друг от друга. Эти опыты послужили убедительным доказательством того, что генетический код состоит из триплетов и читается без «запятых», посредством рамки считывания.
Более того, эта система функциональна только в случае с вырожденным кодом, так как между участками мутаций П и Л или между тремя П-мутациями подряд образовывалось несколько неправильных триплетов. Но фенотип в общем случае оказывался «диким», потому что 64 триплета (или, по меньшей мере, их большинство) кодируют производство какой-либо аминокислоты. Даже если в двойном или тройном мутанте оказывалось несколько неправильных кодов, белки с несколькими «неправильными» аминокислотами получались вполне функциональными. Если бы кодонами были только 20 триплетов, а остальные 44 оказались бессмысленными, то случайная мутация, вероятнее всего, создавала бы бессмысленные кодоны, и синтез белка останавливался бы всякий раз,подходя к такому «пустому месту». Поскольку обычно этого не происходит, код должен быть вырожденным. В действительности, как мы увидим, бессмысленными являются только три из 64 кодонов.
Дата добавления: 2015-02-28; просмотров: 2036;