ТЕХНИКА БЫСТРОГО ЧТЕНИЯ 7 страница
После выяснения природы заболевания девочка была успешно излечена, а анализ заболевания дал интересный материал для разработки проблемы “грамматика и смысл”. Как установил Н. И. Жинкин в ходе этого исследования, на стадии обработки поступающей информации в человеческом мозге есть специальный функциональный алгоритмический фильтр, который не пропускает для дальнейшей обработки бессмысленные словосочетания. Пока никто еще не измерил эффективности использования этого тонкого механизма в человеческом мышлении. Однако есть основания полагать, что потенциальные возможности этого фильтра большинство людей использует очень слабо. При чтении человек должен мгновенно оценить смысловую сторону сообщения и наметить пути дальнейшей его обработки. Причем характерно, что формальная грамматика текста данного языка не имеет существенного значения для восприятия смысла. Так, если составить бессмысленную фразу, хотя грамматически и правильную, то она не будет обрабатываться. Например: “Зеленые идеи яростно спят”. И наоборот, словосочетание, даже построенное с нарушением грамматических норм, но легко поддающееся осмыслению, мозгом воспринимается и обрабатывается успешно. Например: “Моя твоя не понимай”.
Это обстоятельство было отмечено и выдающимся советским психологом Л. С. Выготским, который говорил, что необходимо уметь различать законы развития смысловой стороны речи и ее внешнего физического оформления, выражающегося в правилах построения предложений, правил грамматики и т. п. То, что с точки зрения грамматики языка является ошибкой, “может иметь психологическую ценность на уровне мышления”. В доказательство этого он приводил пушкинские строки:
Как уст румяных без улыбки,
Без грамматической ошибки
Я русской речи не люблю.
|
| Суп из чулок, чулки из супа |
Знаменитое чеховское предложение: “Подъезжая к сией станции... у меня слетела шляпа”, — также дает пример такого психологически понятного, но грамматически неправильного предложения.
Из сказанного следует, что для развитого взрослого человека естественно использовать более информативный язык, хотя иногда и в ущерб строгим грамматическим правилам. Однако это последнее утверждение вовсе не отрицает необходимости самого глубокого изучения грамматики. Исследования, проведенные в последние годы, показали, что линейность внешней речи, фиксируемой в текстах, не доказывает линейного восприятия текста по принципу “слева направо” и элемент за элементом. Как убедительно доказали Д. Миллер, Ю. Галантер и К. Прибрам, “для того, чтобы ребенок обучился всем правилам этой грамматической последовательности ... он должен был бы выслушать приблизительно 3020 предложений в секунду, для того чтобы воспринять всю информацию, необходимую для формирования грамотного предложения”[15]
Рассмотренная закономерность работы мозга объясняет и тот факт, что человек в любом, даже, казалось бы, в самом бессмысленном, выражении: пытается отыскать смысл. Здесь можно напомнить читателям об известном психологическом эксперименте академика Л. Щербы. На одной из лекций по языкознанию он предложил студентам изложить содержание следующей фразы: “Глокая куздра штеко будланула бокра и курдячит бокренка”.
Несмотря на кажущуюся бессмысленность этого предложения, большинство студентов нашли, что в этой фразе говорится о том, что какое-то существо женского пола “наподдало” другому существу мужского пола и продолжает те же действия по отношению к его детенышу. Мы также повторили этот опыт. В одном из наших экспериментов предложили испытуемым следующую фразу: “Швыдкая чурла незденко сигла по донку и одвырла чурта с чурятами”.
И в этом случае большинство испытуемых правильно осмыслили структуру этого текста.
Еще более интересный факт приводит проф. А. А. Реформатский в одной из последних своих работ, которая называется — “Компрессивно-аллегровая речь”: “Мы заметили, что часто, выйдя из нашего домика, Ф. И. Шаляпин... громким раскатистым басом что-то кричал на всю улицу. Слов мы понять не могли, и нам слышалось лишь:
— В-о-о!
После этого странною возгласа со всех концов съезжались таратайки...” Далее А. А. Реформатский пишет: “Как же извозчик в этом „В-о-о!” смог опознать слово „извозчик”? Ведь тут и слоговость не та, и нет ни головы, ни хвоста, да еще такого „характерного” для русского языка, как ,,-щик”... остался только один ударный двухфонемный слог, и это не корень, не основа. А все-таки извозчик приехал. Он услышал и понял. “ ... ” В этом, собственно, и содержится секрет компрессивно-аллегровой речи. А понял извозчик потому, что этого возгласа, где остальное „компрессировано”, достаточно для речевого общения благодаря известности ситуации речи.

|
| Человек в любом, даже, казалось бы, в самом бессмысленном выражении пытается отыскать смысл |
Данный случай — исключительный и даже не вполне точно отвечающий данным параметрам явления. Но очень показательный и убедительный. В нашем ежедневном речевом общении мы постоянно пользуемся этой компрессивно-аллегровой манерой, и это безусловно интересный факт лингвистики речи”.
В самом общем случае можно сказать, что живой язык стремится свести к минимуму усилия акта коммуникации: пишем четыре, а говорим “четые”, пишем “пожалуйста”, а говорим “пожалста”. Этот принцип реализуется не только в речи, но и при чтении — это необходимо знать и уметь использовать при быстром чтении.
ДЕНОТАТ - ЗНАЧЕНИЕ И СМЫСЛ
О чем говорят разобранные примеры? Они свидетельствуют о том, что осмысление текста — это сложный процесс. Вместе с тем он подчиняется определенным законам, обусловленным феноменальными особенностями работы человеческого мозга. Как же использовать эти законы для нашей задачи: научиться при быстром чтении глубоко и полно понимать текст? Чтобы найти пути решения этой проблемы, необходимо вначале решить вопрос о том, что следует понимать в читаемом тексте? Очевидно, некоторым читателям сам вопрос может показаться бессмысленным: ясно — все, что содержится в нем. И вот здесь нас ожидает интересное открытие: текст весь, целиком читать не надо. Чтобы понять его, достаточно прочесть только некоторую его часть, которую можно условно назвать “золотым ядром” содержания.
Это именно те 25% содержания текста, которые остаются после исключения избыточности.
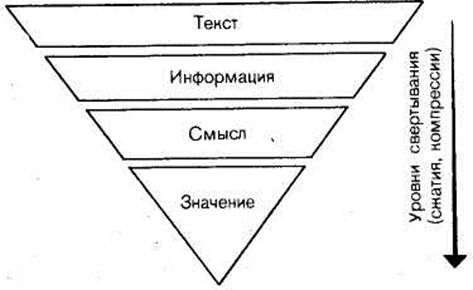
Что же представляет собой “ядро”? Чтобы понять это, рассмотрим основные семантические принципы построения текста. Как установила современная лингвистика, тексты обладают единством внутренней логической организации. Они строятся по единым логическим правилам связности изложения. Кроме того, как мы уже знаем, избыточность текстов весьма велика и доходит до 75% . Очевидно, “золотое ядро”, о котором мы говорим, и несет основную смысловую нагрузку. А если это так, то целевой процесс преобразования текста на сжатие при чтении можно условно считать выделением и формированием этого “ядра”. На рис. 8 приведена блок-схема последовательности выполнения этой операции. Текст содержит определенную информацию, которую читатель в нем видит. Таким образом, первый шаг на пути преобразования текста — выделение интересующей информации. Здесь под информацией мы понимаем то, что данный текст передает конкретному читателю.
|
| РИС. 8 |
Будем исходить при описании дальнейших преобразований из семантической теории информации, разработанной советским математиком и лингвистом Ю. А. Шрейдером. Согласно этой теории, читатель, изучай информацию, сравнивает ее с тем объемом знаний (тезаурусом), которым он располагает в данный момент. В результате такого сравнения читатель дает оценку поступающей информации. Это означает, что если вначале читатель не понял текста, то текст не несет для него никакой информации, Если затем, спустя даже длительное время, получив новые знания, читатель вторично обращается к этому же тексту, то на этот раз он уже извлекает из него нужную информацию. Что же происходит с ней дальше? В результате изучения текста читатель выделяет смысл, который преобразуется затем в значение. Здесь мы ввели два новых термина и, прежде чем разбирать сущность происходящего далее процесса, необходимо дать им объяснение. Что же такое смысл и значение? Впервые изучение понятий “смысл” и “значение” предпринял известный немецкий математик и логик Готлоб Фреге.
В 1892 г. вышла его работа “О смысле и значении”, которая до настоящего времени не потеряла своей актуальности и по-прежнему популярна среди математиков, лингвистов и логиков.
Г. Фреге определяет смысл как содержание языкового выражения, т. е. это мысль, содержащаяся в словах. Значением языкового выражения является тот сущностный предмет, который словесно зафиксирован в сознании человека. Например, значением слова “Луна” по существу является определенное небесное тело или естественный спутник Земли, вращающийся вокруг нее и видимый нами каждую ночь.
Согласно концепции Г. Фреге, отношение имени к тому, что оно называет или обозначает, является отношением называния, а вещь, которая называется, является значением этого имени. Всякое имя всегда что-то называет (это функция номинации) и это что-то — определенная вещь. Естественно, что могут быть и неназванные вещи.
Таким образом, значение — это сущностное свойство имени, которое реализуется путем многообразного называния вещей. Смыслом Г. Фреге называет различие в способе формального обозначения предметов именами. Имена типа: “А. Пушкин”, “Великий русский поэт”, “Поэт, убитый Дантесом” — различны по смыслу, но одинаковы по значению. В текстах можно найти разные способы использования имен: педагог — преподаватель; врач — доктор; разведчик — шпион и т. д. Эти примеры сообщают разные сведения об одном и том же предмете. Таким образом, смысл имени есть то, что передается и понимается в сообщении как социально значимая информация и что при приеме сообщения должно быть понято однозначно. Два выражения могут иметь одно и то же значение, но разный смысл, если эти выражения различаются по структуре реализации текста. Например, рассмотрим выражения: “5” и “3 + 2”.
Смысл в каждом из них различный, а значение и в первом и во втором одинаковое.
Теперь вновь обратимся к рис. 25. Заключительные этапы преобразования фрагмента текста включают выделение из полученного смысла значения. Означает ли это, что всегда, в любом тексте есть все компоненты этой схемы? Совсем нет. Однако вероятность наличия каждого ее элемента идет по убывающей. В самом деле, тексты всегда содержат информацию. Немного можно найти бессмысленных текстов. Но очень много текстов осмысленных и тем не менее не содержащих значения. В литературе по логике обычно приводят пример такого пустого выражения. Понятие, выраженное словами “король Франции”, имеет смысл, но применительно к XX в. значения не имеет. Возможны ли научные тексты подобного содержания?
Для ответа на этот вопрос достаточно самим узнать, есть ли значение в ниже цитируемом тексте?
“Рассмотрим некоторый тотальный и, следовательно, уникальный экземпляр ,,А”. Установление тождества экземпляра с самим собою можно рассматривать как отображение, приводящее образы „ А” в соответствии с прообразом ,,А”. Экземпляр ,,А” по определению может быть сопоставлен только с самим собою. Поэтому отображение является внутренним и, согласно теореме Стилова, может быть представлено в виде суперпозиции: топологического и последующего аналитического отображения. Совокупность образов ,,А” составляет точечную систему, элементы которой являются эквивалентными точками...”[16]

|
| Выражения: “5” и “3 +2“. Смысл каждого из них различный, а значения в первом и втором случае одинаковые |
Как показал анализ, проведенный И. П. Севбо, формальная связанность и наукообразное звучание не уменьшают пустоты этого текста.
Здесь полезно также вспомнить книгу физика А. И. Китайгородского “Реникса”, убедительно доказавшего пустоту поисков “Ауры биополя” и всех “феноменов” парапсихологии. Все тексты по парапсихологии имеют смысл, но не имеют научного значения, так как эти “феномены” не физичны.
Очевидно, теперь мы можем ответить на вопрос о том, что же следует читать в текстах: нужно уметь находить значение.
Быстрое чтение и выявляет смысл и значение мыслей автора. Как же практически научиться выделять значение? И здесь мы рассмотрим еще одно интересное явление. Как показал проф. Н. И. Жинкин, мозг каждого человека уже обладает этой способностью, так как содержит программу выделения значения в любом читаемом тексте, имеющем смысл. Эксперименты психологов подтвердили, что при обработка текста человеческий мозг всегда выделяет ядерное значение, независимо от способа его формального выражения или смысла. Так, в одном из опытов группе испытуемых предлагалось нажимать специальную кнопку каждый раз, как только на экране появлялось слово “доктор”, и не реагировать на сигнал, если появлялись другие слова, даже сходные по начертанию: например “диктор”. Большинство испытуемых справилось с этим заданием. Затем без предупреждения на экране была показана надпись “врач”. И что же?
Практически все нажали кнопку, хотя по начертанию это слово никак не походило на слово “доктор”.
Этот пример — доказательство того, что при восприятии текстовой информации мозг реагирует не на языковую структуру слова, а на его содержательную часть.
ДИФФЕРЕНЦИАЛЬНЫЙ АЛГОРИТМ ЧТЕНИЯ
Итак, при чтении текста мозг формирует “свою трактовку содержаниях того, что читается. Происходит перекодирование сообщения на язык собственных мыслей читателя. Мозг выделяет ядерное сущностное значение из читаемого текста. Однако всегда ли эта программа используется эффективно? Есть основания считать, что большинство людей возможности этой программы используют слабо. Вместе с тем только при осмысленном внимательном чтении текст понимается глубоко и полно.
Из этого следует, что при обучении методам быстрого чтения учат произвольно использовать эту принципиально важную программу работы мозга. Как показали наши эксперименты, знание и умелое применение некоторых упражнений дают возможность извлекать ядерное значение в тексте быстро и достаточно надежно. Эти упражнения основаны на использовании дифференциального алгоритма чтения.
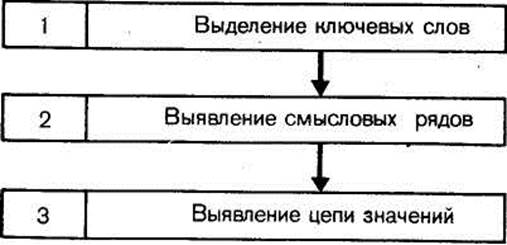
В третьей главе мы говорили об интегральном алгоритме чтения, который облегчает поиск нужной информации в тексте в целом. Для каждого отдельного предложения и абзаца подобную программу, конечно, составить нельзя. Однако для активизации чтения нужно заранее знать, что прежде всего следует отыскивать в каждом смысловом отрезке текста. Для этого и разработан дифференциальный алгоритм чтения (рис. 9). С его помощью можно разбивать каждый формально самостоятельный фрагмент текста на отдельные логические элементы (потому алгоритм и назван дифференциальным).
|
| РИС. 9 |
В соответствии с этой схемой формальные единицы печатного текста вначале ставятся нами в соответствие с языковыми нормами, а затем языковые единицы превращаются в означаемые единицы мыслительного уровня. Образуется своеобразная пирамида понятий, являющаяся одновременно и классификационной системой для опознания смысловой фильтрации каждого нового фрагмента текста и для определения его места в уже сложившейся системе наших представлений. Любая единица этой мнемонической пирамиды абстракций и представляет собой часть алгоритма или структурной модели тех определяющих характеристик, которые являются общими признаками для любого текста.
При такой связи между мыслительными единицами верхняя часть пирамиды абстракции является универсальной для автора и для читателя в понятийном смысле.
Работу по интегральному алгоритму чтения мы с вами сравнивали с отбором товаров в универсаме. По аналогии с этим примером и дифференциальный алгоритм можно сравнить с отбором товара какого-либо вида на одной полке отдела универсама; чтобы успешней и быстрее отобрать из однородного товара необходимую вещь, надо заранее знать, что именно нужно, и суметь быстро оценить предлагаемое.
Представим себе, что мы сфотографировали мыслительный процесс быстро читающего человека на кинопленку и теперь прокручиваем ее в замедленном темпе. Кадры фильма покажут, что сначала в предложениях абзаца выделяются ключевые слова (первый блок дифференциального алгоритма), несущие основную смысловую нагрузку. Заметим, что под абзацем в данном случае понимается законченный в смысловом отношении отрезок текста, состоящий, как правило, из нескольких предложений (смысловой и печатный абзацы могут и не совпадать).
Ключевое слово, как правило, предметно, т. е. обозначает какой-либо объект, его признак, состояние или действие. Предлоги, союзы, междометия и частицы почти никогда не бывают ключевыми словами. Очень редко выступают в этой роли и местоимения, которые лишь замещают уже употребляемое ранее в тексте предметное (ключевое) слово. Если абзац играет второстепенную роль, ключевых слов в нем может и не быть.
Затем, опираясь на ключевые слова, в тексте выявляются смысловые ряды (второй блок дифференциального алгоритма). Что такое Смысловые ряды? Это непрерывные ряды пар слов, состоящие из комбинаций ключевых слов и некоторых определяющих и дополняющих их вспомогательных, которые помогают в сжатом виде понять его содержание. Именно смысловые ряды и составляют “золотое ядро” содержания текста.
Смысловые ряды бывают трех основных видов: именные, предикативные и фактографические.
Именной смысловой ряд обеспечивает функцию так называемой номинации — он дает название основному действующему лицу, предмету, например: “старый мастер”. По нашему определению, смысловой ряд — это всегда пара слов. Именной смысловой ряд — это такая свернутая логическая конструкция, которая состоит из имени существительного и имени прилагательного. Имя прилагательное дает дополнительное определение: “мастер хороший”, “мастер молодой”, “мастер веселый”, — обычно в сообщении бывает до трех прилагательных-определителей при одном существительном — это норма русского языка.
Предикативный смысловой ряд показывает, что делает или что делается с предметом: “мастер чеканит”. Предикативный смысловой ряд — это всегда глагольная конструкция и она бывает трех видов.
Одноместный предикат: “Мастер чеканит”. Двухместный: “Мастер чеканит монету”, — действие перешло на второй предмет, от мастера на монету. Трехместный: “Мастер чеканит монету заказчику”, — действие переходит на третий предмет, на заказчика.
Фактографический смысловой ряд дает четкие количественно-размерные, весовые и другие физические технико-экономические параметры о предмете сообщения: “Мастеру 30 лет”, “У мастера семья из 4 человек”. Таким образом, при чтении любого текста сознание соединяет ключевые слова в лаконичные, свернутые выражения смысловых рядов, несущие основной замысел автора. Текст как бы сжимается, мгновенно мысленно конспектируется — в нем остаются только зерна смысла, “золотое ядро” на уровне непрерывных цепочек пар слов.
Здесь необходимо подчеркнуть, что в соответствии с концепцией проф. А. А. Леонтьева[17] с помощью только что изложенной модели смысловых рядов можно наглядно показать принципиальное различие двух способов свертки текста:
— порождение стандартной и всегда постоянной конструкции смысловых рядов;
— “наполнение” этого каркаса конкретными словами — вариантами. Подбор слов-вариантов происходит на основе реализации ассоциативных признаков читаемых слов.
Но это только промежуточный этап свертки текста. Ключевые слова и смысловые ряды выявляются нами в самом тексте, который пока претерпевает лишь как бы количественные преобразования, — он сжимается, компрессуется. Однако, кроме этого количественного анализа, сообщение всегда подвергается нами и качественному преобразованию. Эта интеллектуальная операция соответствует третьему блоку алгоритма — выявлению значения. Замечено, что содержание прочитанного при пересказе люди почти никогда не излагают слово в слово. Мозг быстро перекодирует воспринятое сообщение в согласии с собственным опытом, собственной программой. Такое перекодирование происходит уже в самом процессе чтения.
Этим как раз и отличается активное, осмысленное продуктивное восприятие текста от механической зубрежки.
На основе смысловых рядов мозг как бы формулирует сообщение самому себе, придавая ему собственную, наиболее удобную и понятную форму. Таким образом, третий блок алгоритма отражает заключительный процесс перекодирования — выявление ядерного значения содержания текста. Решить эту задачу — значит для самого себя сформулировать и усвоить действительное значение того, что хотел сказать автор в конкретном отрывке.
|
| Мозг быстро перекодирует воспринятое сообщение в согласии с собственным опытом, собственной программой |
Посмотрим на примере, как используется дифференциальный алгоритм чтения.
Текст[18]:
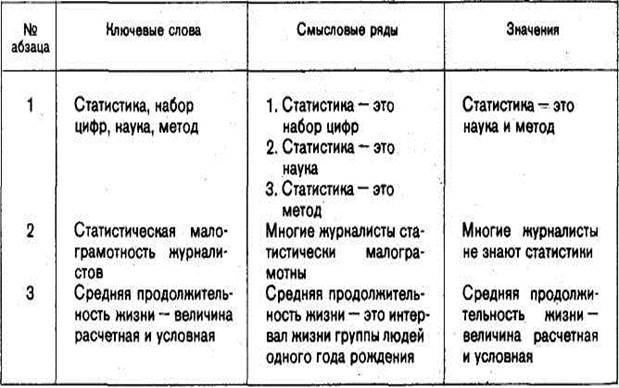
Наш век не без основания называют веком статистики. “Статистика” — слово многозначное. Это и набор цифр, полученных определенным образом и характеризующих некоторое явление, и специальная социально-экономическая наука, и научный метод, широко применяемый как в общественных, так и в естественных науках.
В журналистской работе ко многим темам без статистики совершенно невозможно подойти. В частности, все, относящееся к вопросам народонаселения, прямо-таки основано на статистике. Относительная редкость статей на демографические темы (при громадном интересе к ним читателей и общественной важности этих тем) в немалой мере объясняется статистической малограмотностью многих журналистов, незнанием, как и с какого боку к этим вопросам можно подступиться.
Очень часто смысл цифр читателям непонятен. Один пример. Кто не слышал и не употреблял слов “средняя продолжительность жизни”? Для подавляющего большинства значение их таково: это средний возраст смерти в данное время. Однако истинный смысл их совсем иной: это средняя продолжительность жизни тех, кто родился в данном году, при условии, что на всем протяжении жизни данного поколения возрастные коэффициенты смертности будут такими же, как в год рождения. Таким образом, это величина расчетная и условная.
В этом отрывке подчеркнуты ключевые слова. Порядок обработки абзацев этого текста по алгоритму показан в табл. 2.
ТАБЛИЦА 2
Нужно иметь в виду, что, выполняя упражнения в соответствии с блоками дифференциального алгоритма, мы тренируем мыслительные процессы как бы расчлененно, замедленно и по частям. При чтении они, разумеется, протекают иначе — быстро, одновременно и в значительной мере подсознательно. Но, чтобы навык такого чтения стал автоматизированным и мгновенным, тренировать его нужно дифференцированно. Иными словами, мы поступаем, как спортсмен, который, разучивая комбинацию, разбивает ее на элементы и тренирует каждый из них в отдельности.
Как же практически пользоваться дифференциальным алгоритмом? Прежде всего необходимо запомнить его содержание и порядок использования.
Подобрав несложную научно-популярную статью объемом не более 6 тыс. знаков и медленно читая ее с карандашом в руке, сделать разметку текста в соответствии с алгоритмом. В результате выявления цепи значений должно сформироваться ядерное содержание текста, которое мы называем доминантой. Что же такое доминанта? Доминанта - это главная смысловая часть текста, его истинное значение. Доминанта выражается своими словами читателем, на языке его собственных мыслей. Она результат качественной переработки текста на основе анализа цепи значений по всему тексту статьи в целом.
ГЛАВА ПЯТАЯ ПОДАВЛЕНИЕ АРТИКУЛЯЦИИ ПРИ ЧТЕНИИ
ЧТЕНИЕ - ЭТО ПРИЕМ И ВЫДАЧА РЕЧИ
Исследования проф. Н. И. Жинкина показали, что чтение — по существу одновременно процесс приема и выдачи речи; это означает, что при чтении письменную речь — текст — человек принимает и перерабатывает. По окончании чтения читатель формирует свое представление о прочитанном, т. е. как бы выдает результат обработки текста, и здесь, в усвоении, непременно принимают участие речевые процессы. Именно от того, как они организованы, зависит скорость нашего чтения.
Наблюдения показали, что возможны три основных способа чтения. Первый способ — артикуляция, или проговаривание вслух (или почти вслух) того, что читается. Как мы отмечали, скорость такого чтения невелика. Второй способ — чтение про себя, при котором речевой процесс проявляется в форме внутренней речи, т. е. открытой артикуляции нет. Текст при этом усваивается более эффективно. Способ в принципе допускает быстрое чтение. И наконец, наиболее совершенный, третий способ, тоже молча, но — чтение в условиях максимального сжатия внутренней речи, при котором она проявляется в виде коротких залпов ключевых слов и смысловых рядов, адекватно отражающих смысл текста.
Итак, артикуляция замедляет процесс зрелого чтения взрослого человека и от нее необходимо избавиться. В то же время правомерно поставить вопрос: не приведет ли подавление артикуляции при заметном повышении скорости чтения к снижению качества восприятия и осмысления получаемой информации?
Здесь уместно привести хорошо всем известный факт: в тех случаях, когда нужно запомнить что-либо глубоко и надолго, человек обычно несколько раз проговаривает про себя необходимое сообщение. Он попросту заучивает его. Анализируя этот вопрос, сошлемся на результаты исследований проф. А. Н. Соколова, изучавшего характер внутренней речи при чтении. Как мы уже отмечали, под ней понимается беззвучная, мысленная речь, которая возникает в тот момент, когда мы сосредоточенно думаем о чем-либо или решаем в уме какие-либо задачи, или молча читаем и пишем. Внутренняя речь, как следует из самого названия, есть речевой процесс, однако, в отличие от внешней, звучной речи, речедвижения здесь носят свернутый и беззвучный характер. Иначе говоря, внутренняя речь — это как бы кванты нашей мысли, но реализуемые другим кодом.
Исследования проф. А. Н. Соколова показали, что иногда при чтении текста слова могут быть заменены наглядными зрительными представлениями, пространственными схемами, когда целые группы слов заменяются одним словом, обобщающим смысл всей фразы: “Материнство”, “Мир”, “Свобода”.
Замечено, что быстрочитающие люди обладают способностью, не проговаривая читаемого текста, сразу улавливать и фиксировать замысел автора, а затем усваивать его именно на уровне внутренней речи. В этом случае, несмотря на высокую скорость чтения, происходит глубокое понимание и усвоение надолго прочитанного, так как основная идея понята с самого начала, а все последующее чтение является этапом уточнения основной идеи. Как же научиться такому чтению?
Решается эта задача в два этапа. Первый — сократить артикуляцию, если она ярко выражена, а второй — овладеть приемами чтения, при которых текст воспринимается крупными информативными блоками. В этой главе будет рассмотрена возможность реализации первого этапа.
Мы уже знаем, что все люди по способу восприятия и переработки информации делятся в общем случае на два типа: зрительный и слуховой. Люди зрительного типа при чтении используют код наглядных образов, тогда как люди слухового типа применяют менее производительный код речедвижений. Наблюдения за людьми, читающими быстро, показывают, что они, как правило, относятся к зрительному типу. Вот, например, как описывает О. Бальзак в одном из своих произведений процесс быстрого чтения: “Впитывание мысли в процессе чтения достигло у него способности феноменальной. Взгляд его охватывал семь-восемь строчек сразу, и разум постигал смысл со скоростью, соответствующей скорости глаз. Часто одно-единственное слово позволяло ему усвоить смысл целой фразы”.
Еще более интересны наблюдения Альберта Эйнштейна над механизмом своего мышления. Они позволяют считать, что он являет собой яркий пример человека зрительного типа. В письме к известному математику Жаку Адамару А. Эйнштейн писал: “Слова или язык, как они пишутся или произносятся, не играют никакой роли в моем механизме мышления. Психические реальности, служащие элементами мышления, — это некоторые знаки или более или менее ясные образы, которые могут быть „по желанию” воспроизведены и комбинированы”.

|
| Люди по способу восприятия делятся на два типа: зрительный и слуховой |
Наши наблюдения показали, что направленным обучением можно практически любого здорового человека научить в процессе чтения использовать код наглядных зрительных образов при соответствующем уровне подавления артикуляции.
Как же это сделать? Проявление речедвижений при выполнении различных форм умственной деятельности было замечено давно (например, счет в уме). Делались попытки исследовать, как влияет подавление речедвижения на различные формы умственной деятельности, в частности на чтение.
Дата добавления: 2015-02-03; просмотров: 875;