Рассеянные таблицы (Hash)
Таблицы с прямым доступом имеют очень ограниченное применение в первую очередь из-за ограничения f(ki)¹f(kj) при i ¹ j, то есть требования взаимной однозначности преобразования ключа в адрес. Можно получить более гибкий метод, если отказаться от этого ограничения. Тогда сделается возможной ситуация f(ki)=f(kj) при i¹j, то есть более чем одна запись претендует на один и тот же адрес хранения. В этом случае ключи называют синонимами, а событие – коллизией. Чтобы таких ситуаций было меньше, функцию расстановки подбирают из соображений случайного и возможно более равномерного распределения ключей по памяти, отведенной для таблицы. Таблицы, построенные по такому принципу, называют рассеянными, рандомизированными или хешированными (hash) таблицами. Метод вычисления адреса называют хешированием. Английский глагол to hash означает нарезать, искрошить, сделать месиво. Функцию расстановки h(k) называют хеш-функцией и стремятся сделать такой, чтобы она равномерно рассеивала ключи по памяти.
Будем считать, что хеш-функция имеет не более m различных значений 0£h(k)<m. Хорошая хеш-функция должна удовлетворять двум требованиям: ее вычисление должно быть достаточно быстрым, а число коллизий минимальным. Как правило, хеш-функции используют ту же идею, что и линейные конгруэнтные генераторы псевдослучайных чисел, а именно:
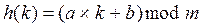 ,
,
где a и b – тщательно подобранные константы, m – число позиций в таблице. Возможное переполнение при выполнении операций умножения и сложения игнорируется.
Для разрешения коллизий существует два метода: метод цепочек переполнения и метод открытой адресации.
В методе цепочек переполнения поддерживается m линейных списков (можно деревьев) – по одному на каждый возможный хеш-адрес. После хеширования алгоритм получает адрес головы списка и производит в нем поиск простым перебором, если требуется поиск, или вставляет новую запись вслед за головой, если требуется вставка. Если имеется n ключей и m списков, то средняя длина списка m/n. На рис. 53 изображен массив списков для метода 
цепочек переполнения.
Рис.53 Метод цепочек переполнения
Метод открытой адресации состоит в том, чтобы, отправляясь от вычисленного хеш-адреса, просматривать записи до тех пор, пока не будет найден искомый ключ при поиске или свободная позиция при вставке. Если в процессе поиска алгоритм встретит свободную позицию, то это означает, что искомого ключа в таблице нет, так как механизм вставки такой, что запись вставляется в первую найденную свободную позицию. Простейшая схема открытой адресации, известная как линейное опробование, последовательно перебирает записи, отправляясь от хеш-адреса, и использует циклическую последовательность проб:
h(k), h(k)+1, h(k)+2,…,m-2, m-1, 0, 1, 2, …,h(k)-1
Эксперименты с линейным опробованием показали, что метод хорошо работает, пока таблица не слишком заполнена. Для линейного опробования характерно явление "скучивания" - скопление записей группами. Действительно, если некоторый отрезок позиций таблицы полностью занят записями, то вероятность хеш-адреса новой записи попасть в этот отрезок и тем самым увеличить его, тем больше, чем больше длина отрезка. Таким образом, куча имеет склонность к экспоненциальному росту. Изменение шага просмотра с единицы на некоторую константу С не решает проблемы – куча все равно образуется, хотя элементы кучи и не являются физическими соседями в памяти.
В методе вторичного хеширования константа С зависит от ключа k. Алгоритм вычисляет две хеш-функции: h1(k) и h2(k). Как и прежде, h1(k) это хеш-адрес, а h2(k) – это шаг опробования. Значение h2(k) должно лежать в диапазоне от 1 до m-1 и быть взаимно простым с m для того, чтобы с этим шагом можно было пройти все позиции таблицы.
Удаление из рассеянной таблицы несет с собой некоторые проблемы. Просто удалить запись, пометив занимаемую ей позицию как свободную, нельзя, так как при этом нарушится работа алгоритмов вставки и поиска. Действительно, при удалении записи с хеш-адресом L одновременно сделаются недоступными все синонимы, которые были включены в таблицу позднее. Можно выйти из положения, имея три типа позиций: свободные, занятые и удаленные. При поиске удаленные позиции трактуются как занятые, а при вставке как свободные. Однако это не решает проблему полностью, так как после длинной серии вставок и удалений в таблице не останется свободных позиций – останутся только занятые и удаленные. В этом случае любой неудачный поиск (поиск ключа, которого нет в таблице) будет приводить к полному перебору всей таблицы. Единственное известное решение этой проблемы заключается в рехешировании, то есть построении таблицы заново. После рехеширования в таблице останутся только свободные и занятые позиции.
Дата добавления: 2014-12-02; просмотров: 1313;