Статистическая гипотеза. Статистический критерий
Задачи статистической проверки
Одна из часто встречающихся на практике задач, связанных с применением статистических методов, состоит в решении вопроса о том, должно ли на основании данной выборки быть принято или, напротив, отвергнуто некоторое предположение (гипотеза) относительно генеральной совокупности (случайной величины).
Например, новое лекарство испытано на определенном числе людей. Можно ли сделать по данным результатам лечения обоснованный вывод о том, что новое лекарство более эффективно, чем применявшиеся ранее методы лечения? Аналогичный вопрос логично задать, говоря о новом правиле поступления в вуз, о новом методе обучения, о пользе быстрой ходьбы, о преимуществах новой модели автомобиля или технологического процесса и т. д.
Процедура сопоставления высказанного предположения (гипотезы) с выборочными данными называется проверкой гипотез.
Задачи статистической проверки гипотез ставятся в следующем виде: относительно некоторой генеральной совокупности высказывается та или иная гипотеза Н. Из этой генеральной совокупности извлекается выборка. Требуется указать правило, при помощи которого можно было бы по выборке решить вопрос о том, следует ли отклонить гипотезу Н или принять ее.
Следует отметить, что статистическими методами гипотезу можно только опровергнуть или не опровергнуть, но не доказать. Например, для проверки утверждения автора, что «в рукописи нет ошибок», рецензент изучил несколько страниц рукописи.
Если он обнаружил хотя бы одну ошибку, то гипотеза отвергается, в противном случае - не отвергается, говорят, что «результат проверки с гипотезой согласуется».
Выдвинутая гипотеза может быть правильной или неправильной, поэтому возникает необходимость ее проверки.
Статистическая гипотеза. Статистический критерий
Под статистической гипотезой (или просто гипотезой) понимают всякое высказывание (предположение) о генеральной совокупности, проверяемое по выборке.
Статистические гипотезы делятся на гипотезы а) о параметрах распределения известного вида, это так называемые параметрические гипотезы; б) гипотезы о виде неизвестного распределения - непараметрические гипотезы.
Одну из гипотез выделяют в качестве основной (или нулевой) и обозначают Н0, а другую, являющуюся логическим отрицанием H0, т.е. противоположную Н0 - в качестве конкурирующей (или альтернативной) гипотезы и обозначают Н1.
Гипотезу, однозначно фиксирующую распределение наблюдений, называют простой (в ней идет речь об одном значении параметра), в противном случае - сложной.
Например, гипотеза Н0, состоящая в том что математическое ожидание случайной величины Х равно 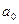 , т.е.
, т.е. 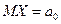 , является простой. В качестве альтернативной гипотезы можно рассматривать одну из следующих гипотез: Н1:
, является простой. В качестве альтернативной гипотезы можно рассматривать одну из следующих гипотез: Н1: 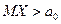 - сложная гипотеза, или Н1:
- сложная гипотеза, или Н1: 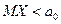 - сложная, Н1:
- сложная, Н1: 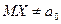 - сложная или Н1 :
- сложная или Н1 : 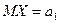 - простая гипотеза.
- простая гипотеза.
Имея две гипотезы Н0 и Н1, надо на основе выборки 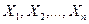 принять либо основную гипотезу Н0, либо конкурирующую Н1.
принять либо основную гипотезу Н0, либо конкурирующую Н1.
Правило, по которому принимается решение принять или отклонить гипотезу Н0 (соответственно, отклонить или принять Н1), называется статистическим критерием (или просто критерием) проверки гипотезы Н0.
Проверку гипотез осуществляют на основании результатов выборки , из которых формируют функцию выборки 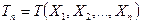 , называемой статистикой критерия.
, называемой статистикой критерия.
Основной принцип проверки гипотез состоит в следующем. Множество возможных значений статистики критерия 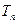 разбивается на два непересекающихся подмножества: критическую область S, т.е. область отклонения гипотезы Н0 и область
разбивается на два непересекающихся подмножества: критическую область S, т.е. область отклонения гипотезы Н0 и область 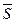 принятия этой гипотезы. Если фактически наблюдаемое значение статистики критерия попадает в критическую область S, то основная гипотеза Н0 отклоняется и принимается альтернативная гипотеза Н1, если же попадает в , то принимается Н0, а Н1 отклоняется.
принятия этой гипотезы. Если фактически наблюдаемое значение статистики критерия попадает в критическую область S, то основная гипотеза Н0 отклоняется и принимается альтернативная гипотеза Н1, если же попадает в , то принимается Н0, а Н1 отклоняется.
При проверке гипотезы может быть принято неправильное решение, т.е. могут быть допущены ошибки двух родов:
Ошибка первого рода состоит в том, что отвергается нулевая гипотеза Н0, когда на самом деле она верна.
Ошибка второго рода состоит в том, что отвергается альтернативная гипотеза Н1, когда она на самом деле верна.
Рассматриваемые случаи наглядно иллюстрирует следующая таблица.
| Гипотеза Н0 | Отвергается | Принимается |
| верна | ошибка 1-го рода | правильное решение |
| неверна | правильное решение | ошибка 2-го рода |
Вероятность ошибки 1-го рода (обозначается через 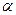 ) называется уровнем значимости критерия.
) называется уровнем значимости критерия.
Очевидно, 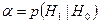 . Чем меньше , тем меньше вероятность отклонить верную гипотезу. Допустимую ошибку 1-го рода обычно задают заранее.
. Чем меньше , тем меньше вероятность отклонить верную гипотезу. Допустимую ошибку 1-го рода обычно задают заранее.
В одних случаях считается возможным пренебречь событиями, вероятность которых меньше 0,05, т.е. 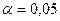 означает, что в среднем в 5 случаях из 100 испытаний верная гипотеза будет отвергнута. В других случаях, когда речь идет, например, о разрушении сооружений, гибели судна и т.п., нельзя пренебречь обстоятельствами, которые могут появиться с вероятностью, равной 0,001.
означает, что в среднем в 5 случаях из 100 испытаний верная гипотеза будет отвергнута. В других случаях, когда речь идет, например, о разрушении сооружений, гибели судна и т.п., нельзя пренебречь обстоятельствами, которые могут появиться с вероятностью, равной 0,001.
Обычно для используются стандартные значения: , 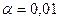 ,
, 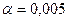 ,
, 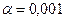 .
.
Вероятность ошибки 2-го рода обозначается через 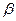 , т.е.
, т.е. 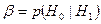 .
.
Величина 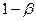 - вероятность недопущения ошибки 2-го рода (т.е. отвергнуть неверную гипотезу Н0, принять верную Н1), называется мощностью критерия.
- вероятность недопущения ошибки 2-го рода (т.е. отвергнуть неверную гипотезу Н0, принять верную Н1), называется мощностью критерия.
Очевидно, 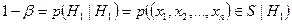 .
.
Чем больше мощность критерия, тем вероятность ошибки 2-го рода меньше, что, конечно, желательно (как и уменьшение ).
Последствия ошибок 1-го, 2-го рода могут быть совершенно различными: в одних случаях надо минимизировать , в другом - .
Например, а) применительно к радиолокации говорят, что - вероятность пропуска сигнала, - вероятность ложной тревоги;
б) применительно к производству, к торговле можно сказать, что - риск поставщика (т.е. забраковка по выборке всей партии изделий, удовлетворяющих стандарту), - риск потребителя (т.е. прием по выборке всей партии изделий, не удовлетворяющей стандарту);
в) применительно к судебной системе, ошибка 1-го рода приводит к оправданию виновного, ошибка 2-го рода - осуждению невиновного.
Отметим, что одновременное уменьшение ошибок 1-го и 2-го рода возможно лишь при увеличении объема выборок. Поэтому обычно при заданном уровне значимости отыскивается критерий с наибольшей мощностью.
Методика проверки гипотез сводится к следующему:
1. Располагая выборкой , формируют нулевую гипотезу H0 и альтернативную Н1.
2. В каждом конкретном случае подбирают статистику критерия , обычно из перечисленных ниже: U - нормальное распределение, 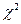 - распределение хи-квадрат (Пирсона), t - распределение Стьюдента, F - распределение Фишера-Снедекора.
- распределение хи-квадрат (Пирсона), t - распределение Стьюдента, F - распределение Фишера-Снедекора.
3. По статистике критерия и уровню значимости а определяют критическую область S и . Для ее отыскания достаточно найти критическую точку 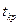 , т.е. границу (или квантиль), отделяющую область S от .
, т.е. границу (или квантиль), отделяющую область S от .
Границы областей определяются, соответственно, из соотношений: 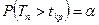 , для правосторонней критической области S (рис. 10.1);
, для правосторонней критической области S (рис. 10.1); 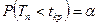 , для левосторонней критической области S (рис. 10.2);
, для левосторонней критической области S (рис. 10.2); 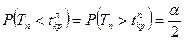 , для двусторонней критической области S (рис. 10.3).
, для двусторонней критической области S (рис. 10.3).
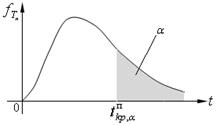
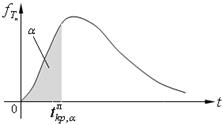
Рис. 10.1. Рис. 10.2
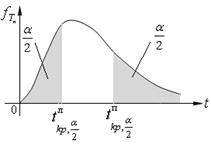
Рис. 10.3
Для каждого критерия имеются соответствующие таблицы, по которым и находят критическую точку, удовлетворяющую приведенным выше соотношениям.
4. Для полученной реализации выборки 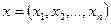 подсчитывают значение критерия, т.е.
подсчитывают значение критерия, т.е. 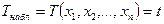 .
.
5. Если 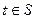 (например,
(например, 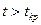 для правосторонней области S), то нулевую гипотезу Н0 отвергают; если же
для правосторонней области S), то нулевую гипотезу Н0 отвергают; если же 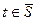 (
( 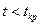 ), то нет оснований, чтобы отвергнуть гипотезу Н0.
), то нет оснований, чтобы отвергнуть гипотезу Н0.
Дата добавления: 2017-03-29; просмотров: 255;