Эффективность и правильность алгоритмов.
Хотя современные машины способны выполнять миллионы команд в секунду, эффективность остается главной проблемой при построении алгоритмов. Один из разделов вычислительной техники называется анализ алгоритмов и занимается изучением ресурсов, таких как время, объем памяти, требующихся для выполнения алгоритмов. Такие исследования применяются при оценке относительных преимуществ использования того или иного алгоритма.
Рассмотрим задачу, стоящую перед секретарем университета, которому нужно просмотреть и обновить данные некоторого студента. Пусть файл студентов содержит информацию более чем о 30 000 человек. Предположим, что эти данные хранятся в компьютере секретаря в виде списка, упорядоченного по идентификационному номеру (номеру зачетки) студента. Для того чтобы найти информацию о каком-либо студенте, секретарь должен отыскать в этом списке заданный идентификационный номер.
При заданном идентификационном номере алгоритм последовательного поиска сравнивает этот номер с элементами списка с самого начала списка. Не зная ничего о происхождении искомого значения, мы не может сделать вывод, как далеко от начала списка оно находится. Однако можно сказать, что средняя глубина поиска составляет половину списка, потому что некоторые номера находятся ближе к началу, другие ближе к концу списка. Мы заключаем, что за некоторый промежуток времени алгоритм последовательного поиска изучит примерно 15 000 записей. Если для извлечения идентификационного номера каждой записи требуется 10мс, то поиск одного номера займет в среднем 150с или 2,5мин. Для секретаря это означает достаточно долгое ожидание, пока информация появится на экране.
Алгоритм двоичного поиска начинает работу со сравнения заданного значения с элементом, находящимся в середине списка (список должен быть упорядочен). Если они не совпадают, то при дальнейшем поиске можно ограничиться только половиной списка. Следовательно, после рассмотрения среднего элемента списка, состоящего из 30 000 элементов, алгоритм должен обработать список из 15 000 записей. После второго запроса остается список из 7500 записей, а после третьего извлечения номера рассматриваемый список сократится до 3750 элементов. Таким образом, искомая запись будет найдена (или не найдена) после извлечения не более 15 элементов списка. Следовательно, если извлечение номера выполняется за 10мс, то процесс поиска отдельной записи займет только 0,15с. То есть доступ к отдельной записи секретарю покажется мгновенным. Из этого можно сделать вывод, что выбор между алгоритмами последовательного и двоичного поиска является существенным для решения данной прикладной задачи. [1]
В примере сравнивали средний случай работы алгоритма последовательного поиска с наихудшим случаем работы алгоритма двоичного поиска. Несмотря на то, что мы анализировали список определенной длины, не составит труда применить наши рассуждения к списку произвольной длины. В частности, если применить алгоритм последовательного поиска к списку, состоящему из N элементов, то в процессе работы он рассмотрит в среднем N/2 элементов. В то время как алгоритм двоичного поиска в наихудшем случае извлечет максимально lоg2N элементов.
Рассмотрим также алгоритм сортировки методом вставки. Этот алгоритм выбирает из списка элемент, который называется ведущим элементом, сравнивает его с предшествующими элементами, пока не поместит его в правильную позицию. Поскольку главным действием в алгоритме является сравнения двух элементов, мы будем подсчитывать число сравнений, которые выполняются в процессе сортировки списка, имеющего длину N.
Сначала алгоритм выбирает в качестве ведущего второй элемент списка, затем извлекает последовательно все элементы до тех пор, пока не достигнет конца списка. В наилучшем случае каждый ведущий элемент уже находится на своем месте и, следовательно, его нужно сравнить только с одним элементом. Таким образом, в наилучшем случае для сортировки списка методом вставки потребуется (N-1) сравнений. В наихудшем случае каждый ведущий элемент сравнивается со всеми элементами, расположенными до него. Так происходит в том случае, когда элементы сортируемого списка расположены в обратном порядке. В этом случае общее число сравнений в процессе сортировки списка из N элементов, равно 1 + 2 + 3 + ... + (N-1)=1/2(N2-N). В среднем в случае сортировки методом вставки каждый ведущий элемент сравнивается с половиной элементов, предшествующих ему. В результате требуется в два раза меньше сравнений, чем в наихудшем случае, чтобы упорядочить список.
Полученные нами результаты имеют большое значение, поскольку по количеству сравнений, выполненных в процессе работы алгоритма, можно определить приблизительное количество времени, необходимое для его выполнения. Зависимость времени выполнения сортировки методом вставки от длины списка показана на рисунке 1.4. Этот график построен с помощью данных, полученных при анализе наихудшего случая, когда мы пришли к выводу, что для сортировки списка, имеющего длину N, потребуется, по большей мере, 1/2(N2-N) сравнений. На графике через равные промежутки отмечены несколько значений длины списка и значения интервала времени, соответствующего каждой длине. Из графика видно, что при изменении длины списка на одинаковое количество элементов промежуток времени, необходимый для его сортировки, возрастает на значительно больший интервал. Следовательно, при увеличении длины списка эффективность алгоритма снижается.
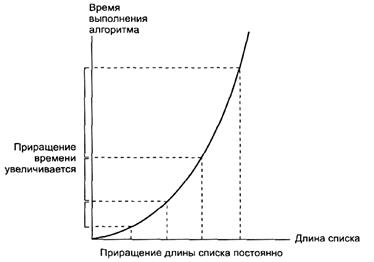
Рис. 2.4. График зависимости времени сортировки методом вставки от длины списка.
|
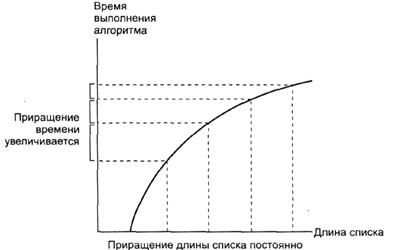
Рис. 2.5. График зависимости времени поиска с помощью алгоритма двоичного поиска от длины списка
Рассматривая алгоритм двоичного поиска, мы пришли к выводу, что для нахождения какого-либо элемента в списке, длина которого равна N, нужно рассмотреть максимально lоg2N элементов. График зависимости времени поиска от длины списка изображен на рис. 1.5. В данном случае время выполнения алгоритма увеличивается на меньшие интервалы при возрастании длины списка на равное количество элементов. То есть при увеличении длины списка эффективность алгоритма двоичного поиска повышается.
Главное различие между этими двумя графиками (рис. 1.4 и 1.5) состоит в форме кривой, которая в свою очередь определяется типом функции, изображенной на графике, а не ее параметрами. Форма графика, получаемого путем соотнесения времени, необходимого для выполнения алгоритмом задачи, и количества входных данных, отражает эффективность алгоритма. Поэтому принято классифицировать алгоритмы согласно форме графика, который обычно строится на анализе наихудшего случая. Система представления, которая используется для определения вышерассмотренных классов алгоритмов, иногда называется «Q-представлением» (тета-представлением). По этому представлению можно разделить алгоритмы на два класса: Q(N2) и Q(lgN). Зная класс, к которому относится алгоритм, который предполагается использовать при решении задачи, можно предсказать его эффективность и сделать выбор в пользу того или иного алгоритма. [1]
Дата добавления: 2017-01-29; просмотров: 907;