Модель и реализация
Прежде чем двигаться дальше, я хочу остановиться на одном моменте, существенном для всего, что будет обсуждаться ниже. Разумеется, реляционная модель – это модель данных. Но, к сожалению, последний термин имеет в мире баз данных два совершенно разных значения. Пер- вое и наиболее фундаментальное таково:
Определение: Модель данных (в первом смысле) – это абстрактное, независимое, логическое определение структур данных, операторов над данными и прочего, что в совокупности составляет абстрактную систему, с которой взаимодействует пользователь.
Именно это значение слова мы имеем в виду, когда говорим о реляционной модели. И, вооружившись этим определением, мы можем провести полезное, и важное, различие между моделью данных в первом смысле и ее реализацией, которая определяется следующим образом.
Определение: Реализацией данной модели данных называется физическое воплощение на реальной машине тех компонентов абстрактной системы, которые в совокупности составляют модель.
Я проиллюстрирую эти определения в терминах реляционной модели.
Прежде всего, само понятие отношения является частью модели данных: пользователи должны знать, что такое отношение, понимать, что оно состоит из кортежей и атрибутов, уметь их интерпретировать и т. д.
Все это части модели. Но пользователям необязательно знать, как отношения физически хранятся на диске, как физически кодируются отдельные значения данных, какие существуют индексы или другие пути доступа к данным – это части реализации, а не модели.
Или возьмем концепцию соединения: пользователи должны знать, что такое соединение, как его осуществить, как выглядит результат со- единения и т. д. Опять-таки, все это части модели. Но совершенно ни к чему знать, как физически реализуется соединение, какие при этом производятся трансформации выражений, какие используются индексы или иные пути доступа к данным, какие требуются операции ввода/ вывода – это части реализации, а не модели.
И еще один пример: потенциальные ключи (для краткости просто ключи) – часть модели, и пользователям определенно необходимо знать, что представляют собой ключи. На практике уникальность ключей часто гарантируется посредством так называемого уникального индекса; но индексы вообще и уникальные индексы в частности не являются частью модели, это часть реализации. Таким образом, не следует путать индекс с ключом в реляционном смысле, даже если первый применяется для реализации второго (точнее, для реализации некоторого ограничения ключа, см. главу 8).
Короче говоря:
- Модель (в первом смысле) – это то, что пользователь должен знать.
- Реализация – это то, что пользователю знать необязательно.
Я вовсе не хочу сказать, что пользователям запрещено знать о реализации; я лишь говорю, что это необязательно. Иными словами, все касающееся реализации должно быть, по крайней мере потенциально, скрыто от пользователя.
Из данных выше определений вытекают некоторые важные следствия. Прежде всего (и вопреки чрезвычайно распространенному заблуждению), все связанное с производительностью принципиально является деталью реализации, а не модели. Например, мы часто слышим, что «соединение – медленная операция». Но такое замечание лишено вся- кого смысла! Соединение – это часть модели, а модель как таковая не может быть ни медленной, ни быстрой; такими качествами может обладать только реализация. Поэтому допустимо сказать, что в некотором продукте X конкретная операция соединения реализована быстрее или медленнее, чем в продукте Y, – но это и все.
 |
Я не хочу, чтобы у вас в этом месте сложилось ложное впечатление. Да, производительность принципиально является деталью реализации; однако это не означает, что хорошая реализация будет работать быстро, если модель используется неправильно. На самом деле, это как раз одна из причин, по которым вы должны знать устройство модели: чтобы не использовать ее неправильно. Написав выражение S JOIN SP, вы вправе ожидать, что реализация сделает все необходимое и сделает хорошо; но если вы настаиваете на ручном кодировании соединения, например таким образом (в виде псевдокода):
то рассчитывать на достижение высокой производительности было бы глупо. Рекомендация: Не поступайте так. Реляционные системы не следует использовать в качестве простых методов доступа.1
Кстати, эти замечания по поводу производительности относятся и к SQL. Утверждения о быстроте или медленности точно так же бессмысленны в применении к SQL, как и к реляционным операторам (соединению и прочим); в этих терминах имеет смысл говорить только о реализациях. Однако использовать SQL можно и так, что это гарантированно приведет к плохой производительности. Хотя в этой книге тема производительности почти не затрагивается, иногда я все же буду отмечать последствия своих рекомендаций с этой точки зрения.
Отступление
Я хотел бы ненадолго задержаться на вопросе о производительности. Вообще говоря, приводя в этой книге ту или иную рекомендацию, я не руководствовался соображениями производительности; в конце концов, реляционная модель всегда ставила целью передать заботу о производительности от пользователя системе. Однако не стоит и говорить, что эта задача так и не была решена в полной мере, и потому (как я уже отмечал) поставленной целью – реляционное использование SQL – иногда приходится жертвовать в интересах достижения приемлемой производительности. И это еще одна причина, по кото- рой действует универсальное правило: можете делать все, что хотите, если только знаете, что делаете.
Но вернемся к различию между моделью и реализацией. Второй момент, как вы, вероятно, догадались, состоит в том, что именно разделение модели и реализации позволяет добиться физической независимости от данных. Физическая независимость от данных – термин, пожалуй, не слишком удачный, но он уже устоялся, – означает, что мы можем как угодно изменять способ физического хранения и доступа
к данным, не внося соответствующих изменений в то, как данные представляются пользователю. Причина, по которой может возникнуть желание изменить детали хранения и доступа, как правило, связана
с производительностью; а тот факт, что такие изменения можно производить, не меняя способа представления данных пользователю, означает, что существующие программы, запросы и прочее будут продолжать работать. Таким образом, – и это очень важно – физическая независимость от данных позволяет уменьшить капиталовложения в обучение пользователей и разработку приложений и, добавлю еще, капиталовложения в проектирование логической структуры базы данных.
Из всего сказанного следует, что (как отмечалось выше) индексы, да и вообще все виды физических путей доступа, являются составной частью реализации, а не модели; их место «под капотом», где они не видны пользователю. (Отмечу, что пути доступа как таковые вообще не упоминаются в реляционной модели.) По тем же причинам их, строго говоря, следовало бы исключить и из SQL. Рекомендация: Избегайте любых конструкций SQL, нарушающих эту заповедь. (Насколько я знаю, в стандарте нет ничего, вступающего в противоречие с этой рекомендацией, чего нельзя сказать о некоторых продуктах на основе SQL.)
Как бы то ни было, из приведенных выше определений видно, что различие между моделью и реализацией в действительности является частным – хотя и очень важным – случаем всем знакомого общего различия между логической и физической организацией. Однако, как это ни печально, в большинстве современных SQL-систем оно не проводится так четко, как следовало бы. Отсюда немедленно следует, что они в гораздо меньшей степени физически независимы от данных, чем хотелось бы, и не обеспечивают тех свойств, которые должны присутствовать в реляционной системе. В следующем разделе я еще вернусь к этой теме.
А теперь я хочу обратиться ко второму значению термина модель данных, с которым, смею предположить, вы отлично знакомы. Его можно определить следующим образом:
Определение: Моделью данных (во втором смысле) называется модель данных (особенно сохраняемых) конкретного предприятия.
Иными словами, модель данных во втором смысле – это просто (логическая и, возможно, до некоторой степени абстрактная) структура базы данных. Например, можно говорить о модели данных банка, больницы или правительственного учреждения.
Объяснив оба смысла, я хочу привлечь ваше внимание к аналогии, которая, как мне кажется, отлично иллюстрирует соотношение между ними.
- Модель данных в первом смысле – аналог языка программирования, конструкции которого применимы для решения многих конкретных задач, но сами по себе не связаны ни с какой отдельной за- дачей.
- Модель данных во втором смысле – аналог конкретной программы, написанной на этом языке, – в ней используются средства, предоставляемые моделью в первом смысле, для решения конкретной задачи.
Кстати говоря, из сказанного выше следует, что если мы ведем речь
о моделях данных во втором смысле, то можем без опасения говорить
о «реляционных моделях» во множественном числе или о «некоторой» реляционной модели. Но модель данных в первом смысле только одна, и это та самая реляционная модель, которую придумал Кодд. Последнюю мысль я еще разовью в приложении A.
Далее в книге я буду употреблять термин модель данных, или для крат- кости просто модель, исключительно в первом смысле.
Свойства отношений
Теперь вернемся к изучению основных понятий реляционной теории. В этом разделе я хочу остановиться на некоторых свойствах самих отношений. Прежде всего, у каждого отношения есть заголовок и тело. Заголовком называется множество атрибутов (здесь под атрибутом я понимаю пару имя-атрибута/имя-типа), а телом – множество кортежей, согласованных с заголовком. Так, у отношения «поставщики» на рис. 1.3 заголовок состоит из четырех атрибутов, а тело – из пяти кортежей. Таким образом, отношение не содержит кортежей – оно содержит тело, которое, в свою очередь, содержит кортежи, – но обычно мы для простоты говорим, что кортежи содержит само отношение.
Попутно отмечу, что хотя правильно было бы говорить, что заголовок состоит из пар имя-атрибута/имя-типа, обычно имена типов на рисунках, подобных рис. 1.3, опускаются, из-за чего создается впечатление, будто заголовок состоит только из имен атрибутов. Например, атрибут STATUS имеет тип, – допустим, INTEGER, – но на рис. 1.3 он не показан. Однако не следует забывать, что он все-таки существует!
Далее, количество атрибутов в заголовке называется степенью (или арностью), а количество кортежей в теле – кардинальностью. Например, для отношений S, P и SP на рис. 1.3 степень равна соответственно 4, 5 и 3, а кардинальность – 5, 6 и 12. Примечание: термин степень применяется также к кортежам. Так, все кортежи в отношении S имеют степень 4 (как и само отношение S).
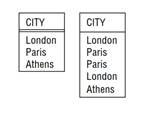
Отношения никогда не содержат кортежей-дубликатов. Это следует из того, что тело определяется как множество кортежей, а математическое множество по определению не содержит дубликатов. В этом от ношении SQL, как вы, конечно, знаете, отступает от теории: таблицы в SQL могут содержать строки-дубликаты и потому в общем случае не являются отношениями. Хочу подчеркнуть, что в этой книге термином отношение я всегда называю истинное отношение – без кортежей- дубликатов, – а не таблицу SQL. Кроме того, вы должны понимать, что реляционные операции всегда порождают результат без кортежей- дубликатов, в полном соответствии с определением. Например, проекция отношения «поставщики» на рис. 1.3 на атрибут CITY дает результат,
 |
показанный ниже на левом, а не на правом рисунке:
(Изображенный на левом рисунке результат можно получить SQL-запросом SELECT DISTINCT CITY FROM S. Если опустить слово DISTINCT, то получится нереляционный результат, показанный справа. Особо отметим, что в таблице справа нет двойного подчеркивания, поскольку в ней нет никакого ключа, а уж тем более первичного.)
Далее, кортежи отношения не упорядочены. Это свойство также следует из того, что тело определено как множество, а элементы математического множества не упорядочены (стало быть, {a,b,c} и {c,a,b} в математике считаются одним и тем же множеством, и, естественно, то же справедливо и для реляционной модели). Конечно, когда мы рисуем отношение на бумаге в виде таблицы, мы должны располагать строки сверху вниз, но в таком порядке нет ничего реляционного. Так, строки отношения «поставщики» на рис. 1.3 я мог бы расположить в любом по- рядке, скажем, сначала S3, потом S1, потом S5, S4 и S2, и это было бы то же самое отношение. Примечание: Тот факт, что отношения не упорядочены, еще не означает, что в запрос нельзя включать фразу ORDER BY, но означает, что результат, возвращенный таким запросом, не является отношением. Фраза ORDER BY полезна для представления результатов, но сама по себе не является реляционным оператором.
Аналогично, не упорядочены и атрибуты отношения, поскольку заголовок также является математическим множеством. Изображая отношение в виде таблицы на бумаге, мы по необходимости располагаем столбцы в некотором порядке – слева направо, но в таком порядке нет ничего реляционного. Так, для отношения «поставщики» на рис. 1.3 я мог бы расположить столбцы в любом другом порядке, скажем, STATUS, SNAME, CITY, SNO, и с точки зрения реляционной модели это было бы то же самое отношение (это еще одна причина, по которой таблицы SQL вообще говоря не являются отношениями). Например, на обоих рисунках ниже представлено одно и то же отношение, но разные таблицы SQL:
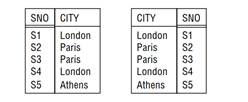 |
(В SQL эти представления порождаются соответственно запросами SELECT SNO, CITY FROM S и SELECT CITY, SNO FROM S. Возможно, вам кажется, что различие между этими двумя запросами и таблицами несущественно, но на самом деле последствия весьма серьезны, и о некоторых из них я расскажу в последующих главах. См., например, об- суждение SQL-оператора JOIN в главе 6.)
Наконец, отношения всегда нормализованы (или, что то же самое, находятся в первой нормальной форме, 1НФ). Неформально это означает, что в табличном представлении отношения на пересечении любой строки и любого столбца мы видим только одно значение. Более формально – каждый кортеж отношения содержит единственное значение соответствующего типа в позиции любого атрибута. В следующей главе я буду говорить об этом гораздо более подробно.
И в заключение я хотел бы еще раз акцентировать ваше внимание на моменте, о котором упоминал неоднократно: существует логическое различие между отношением как таковым и его изображением, например, на рис. 1.1 и 1.3. Повторю, что конструкции, показанные на рис. 1.1 и 1.3, вообще не являются отношениями, а лишь изображения- ми отношений, которые я обычно называю таблицами, несмотря на то, что это слово уже наделено определенной семантикой в контексте SQL. Конечно, между отношениями и таблицами есть определенное сходство, и в неформальном контексте о них обычно говорят, как об одном и том же, – и, пожалуй, это допустимо. Но если требуется точность – а как раз сейчас я пытаюсь быть точным, – то необходимо понимать, что эти два понятия не идентичны.
Попутно отмечу, что и в более общем плане существует логическое различие между произвольной сущностью и изображением этой сущности. Эта мысль замечательно проиллюстрирована на знаменитой картине Магритта. На картине изображена обычная курительная трубка, но под ней Магритт написал Ceçi n’est pas une pipe… – смысл, конечно, в том, что рисунок – это не трубка, а лишь изображение трубки.
Ко всему вышесказанному я хочу добавить, что на самом деле тот факт, что основной абстрактный объект реляционной модели – отношение – имеет такое простое представление на бумаге, составляет важное достоинство этой модели; именно наличие простого представления и делает реляционные системы простыми для понимания и использования и позволяет без труда рассуждать об их поведении. Но, к сожалению, это же свойство может приводить к неверным выводам (например, о существовании некоего порядка кортежей – сверху вниз).
И еще один момент: я сказал, что существует логическое различие между отношением и его изображением. Концепция логического различия вытекает из следующего афоризма Виттгенштейна:
Любое логическое различие является существенным различием.
Это замечание необычайно полезно; как «мыслительный инструмент»
оно весьма способствует четким и ясным рассуждениям и очень помогает при выявлении и анализе некоторых путаных мест, которые,
к несчастью, так часто встречаются в мире баз данных. Я еще не раз вернусь к нему на страницах этой книги. А пока позвольте мне выделить те логические различия, с которыми мы уже столкнулись:
- SQL и реляционная модель
- Модель и реализация
- Модель данных (в первом смысле) и модель данных (во втором смысле) В последующих трех разделах будут описаны и другие различия.
Дата добавления: 2017-01-17; просмотров: 1122;