Автоматическое доказательство теорем
Автоматическое доказательство теорем является основой логического программирования, одним из способов построения систем искусственного интеллекта.
Алгоритм, который проверяет соотношение G |-T S для формулы S, множества формул G и теории T называется алгоритмом автоматического доказательства теорем.
Для достаточно простых формальных теорий, например, прикладных исчислений первого порядка такой алгоритм существует. Автоматическое доказательство проводится методом резолюций, в основе которого лежит способ доказательства от противного. Часто логическим программированием называют автоматическое доказательство методом резолюций, однако этот метод лишь наиболее разработанный его частный случай.
Теорема 7.1. Если G, ØS |- F, где F – любое противоречие, то G |- S.
Доказательство. Если G, ØS |- F, то GÙ(ØS)|- F, так как GÙ(ØS)|- G и GÙ(ØS)|- ØS. Следовательно, |- GÙ(ØS) ® F. Так как
GÙ(ØS) ® F º 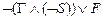 º
º 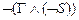 º
º 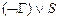 º
º 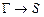 ,
,
то |- и, следовательно, G |- S.
Метод резолюций работает со стандартной формой формул, называемой предложениями. Предложением называется бескванторная дизъюнкция литералов. Любая формула исчисления предикатов может быть преобразована в множество предложений по следующему алгоритму.
1. Построить предварённую нормальную форму формулы. Напомним, что для этого нужно:
a) преобразовать формулу к приведённому виду, т.е. исключить операцию ® и спустить операцию отрицания до атомарных формул;
b) провести разделение связанных переменных;
c) вынести операции связывания переменных в начало формулы.
2. Преобразовать предварённую нормальную форму в предклазуальную, т.е. привести матрицу U нормальной формы к КНФ.
3. Провести сколемизацию нормальной формы (построить клазуальную нормальную форму, исключив операции связывания переменных).
4. Удалить операции Ù (дизъюнкции клазуальной нормальной формы составят искомое множество предложений).
Далее к предложениям, полученным из формул множества G и из формулы ØS, применяется правило резолюции. Сформулируем это правило для исчисления высказываний, а, затем, обобщим его для исчисления предикатов.
Определение. Пусть 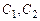 – предложения исчисления высказываний, такие что
– предложения исчисления высказываний, такие что  ,
, 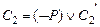 . Правило вывода
. Правило вывода
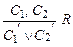
называется правилом резолюции исчисления высказываний, предложения – резольвируемыми, а 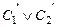 – резольвентой.
– резольвентой.
Замечание. Многие рассмотренные ранее правила вывода являются частными случаями правила резолюции. Например, основное правило исчисления ИВ – правило заключения 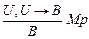 можно представить в виде
можно представить в виде 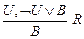 .
.
Таким образом, множество предложений будет являться противоречивым, если в результате последовательного применения правила резолюции, получим пустую формулу, которую будем обозначать š. Действительно, если резольвента пуста, то резольвируемые предложения – взаимно противоположные высказывания и система предложений противоречива.
Задание 1. Доказать методом резолюций |- 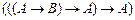 .
.
Решение. В данном примере G – пусто, 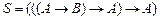 . Преобразуем формулу
. Преобразуем формулу 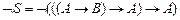 в множество предложений.
в множество предложений.
º 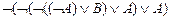 º
º
º 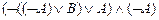 º
º 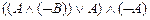 º
º
º 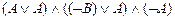 º
º 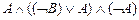
1. A
2. 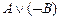
3. ØA
4. š
Применив к предложениям 1, 3 правило резолюции, получим пустую формулу, то есть противоречие. Следовательно, формула S является выводимой из пустого множества посылок или теоремой рассматриваемой теории.
Для того чтобы сформулировать правило резолюции для исчисления предикатов введём понятие унификатора.
Определение.Подстановкой q сигнатуры s называется конечное множество вида 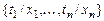 , где
, где 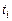 – терм сигнатуры s, отличный от переменных
– терм сигнатуры s, отличный от переменных 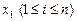 и все переменные
и все переменные 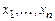 различны.
различны.
Например, множества 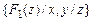 и
и 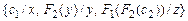 являются подстановками сигнатуры
являются подстановками сигнатуры 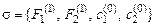 .
.
Пусть U – формула, а q – подстановка сигнатуры s. Обозначим через  формулу, полученную заменой всех вхождений на термы .
формулу, полученную заменой всех вхождений на термы .
Определение. Подстановка q сигнатуры s называется унификатором для множества 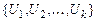 формул сигнатуры s, если
формул сигнатуры s, если 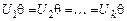 . Множество формул сигнатуры s, называется унифицируемым, если для него существует унификатор сигнатуры s.
. Множество формул сигнатуры s, называется унифицируемым, если для него существует унификатор сигнатуры s.
Например, множество формул 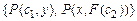 сигнатуры
сигнатуры 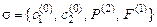 унифицируемо, так как подстановка
унифицируемо, так как подстановка 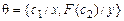 является его унификатором.
является его унификатором.
Определение.Пусть 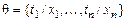 и
и 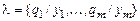 – подстановки сигнатуры s. Композицией подстановок q и l (обозначается q ° l) называется подстановка, которая получается из множества
– подстановки сигнатуры s. Композицией подстановок q и l (обозначается q ° l) называется подстановка, которая получается из множества 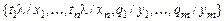 вычеркиванием всех элементов
вычеркиванием всех элементов 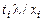 , для которых
, для которых 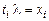 , и всех элементов
, и всех элементов 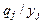 , для которых
, для которых  .
.
Пример. Пусть 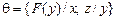 ,
, 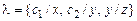 . Тогда =
. Тогда = 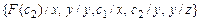 , а так как
, а так как 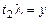 и
и 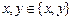 , то
, то 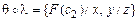 .
.
Определение.Унификатор t для множества формул сигнатуры s называется наиболее общим унификатором (НОУ), если для каждого унификатора q сигнатуры s этого множества существует подстановка l сигнатуры s такая, что 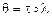 .
.
Так для множества 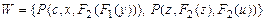 наиболее общим унификатором является подстановка
наиболее общим унификатором является подстановка 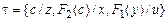 .
.
Определение. Пусть – предложения исчисления предикатов, такие что 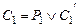 ,
, 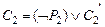 , а атомарные формулы
, а атомарные формулы 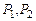 унифицируемы наиболее общим унификатором t. Правило вывода
унифицируемы наиболее общим унификатором t. Правило вывода

называется правилом резолюции исчисления предикатов.
Задание 2. Проверить G |- 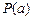 , где
, где
G: 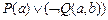 ,
, 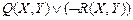 ,
,  ,
, 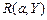 .
.
Решение. Выпишем множество предложений G, ØS, пронумеровав их.
1.
2.
3.
4.
5. 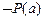
Далее будем добавлять предложения в это множество, применяя правило резолюции с возможной предварительной унификацией. Рядом с новым предложением будем указывать способ его получения (правило резолюции или унификация) и номера предложений, к которым он применялся.
6. 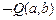 R (1, 5)
R (1, 5)
7. 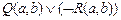
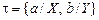 (2, 6)
(2, 6)
8. 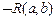 R (6, 7)
R (6, 7)
9. 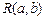
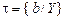 (4, 8)
(4, 8)
10. š R (8, 9)
Следовательно, G |- .
Работа метода резолюций может иметь следующие варианты результатов:
1) на очередном шаге получено пустое предложение и, следовательно, формула S является следствием G (теорема доказана);
2) если во множестве предложений нет новых резольвируемых предложений, то теорема опровергнута;
3) множество предложений постоянно пополняется новыми предложениями (зацикливание), что означает, что средств данной теории недостаточно ни для того, чтобы доказать теорему, ни для того, чтобы её опровергнуть.
Представим алгоритм работы метода резолюций на языке описания алгоритмов. Результат 1 – если S выводимо из G, 0 – в противном случае. Обозначим M – множество предложений, C – множество предложений, полученное из G и ØS. Функция choose выполняет выбор резольвируемых предложений, R – вычисляет резольвенту.
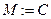
while ÿÏC
begin choose ( 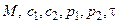 )
)
if 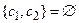 then return 0
then return 0
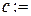 R(
R( 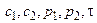 )
)

end
return 1
ТЕОРИЯ АЛГОРИТМОВ
Неформально понятие алгоритма, как последовательности действий направленных на решение некоторой задачи, вводилось ещё в курсе информатики. Далее в курсах технологии программирования, дискретной математики, математической логики рассматривались алгоритмы решения различных типов задач. В данном разделе мы формализуем понятие алгоритма, введём понятие вычислительной сложности алгоритма, классифицируем алгоритмы.
Вид формальной модели алгоритма зависит от тех понятий, которые положены в основание модели.
1) Первый подход основан на представлении об алгоритме, как о программе для некоторого детерминированного устройства. К моделям этого типа относятся машины Тьюринга, канонические системы Поста, нормальные алгорифмы Маркова.
2) Второй подход основан на понятии вычисления и числовой функции, основная теоретическая модель этого вида – рекурсивные функции.
Перед введением формальных определений алгоритма сформулируем понятия, необходимые для дальнейшего изложения.
Всюду далее будет рассматриваться некоторая массовая задача P. Массовая задача P определяется следующей информацией:
1) общим списком параметров задачи;
2) формулировкой свойств, которым должно удовлетворять её решение.
Напомним, что этот набор называют ещё спецификацией задачи.
Индивидуальная задача I получается подстановкой в массовую задачу P данного вида конкретных значений параметров. Будем говорить, что алгоритм решает массовую задачу P, если применим к произвольной индивидуальной задаче I, соответствующей задаче P, и даёт решение задачи I.
В качестве массовой задачи P будем рассматривать задачу распознавания, т.е. задачу решением которой могут быть ответы “да” или “нет”. Например, задачей распознавания является задача определения – делится ли заданное натуральное число нацело на 4. Это не ограничивает общности, так как любая задача может быть сформулирована в терминах задачи распознавания.
Обозначим через
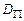 – множество всех индивидуальных задач, соответствующих задаче P,
– множество всех индивидуальных задач, соответствующих задаче P,
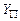 – множество индивидуальных задач с ответом “да”.
– множество индивидуальных задач с ответом “да”.
Таким образом, задача распознавания состоит в определении этих двух множеств.
Для записи задачи распознавания используется естественный формальный эквивалент, называемый языком. Обозначим
S – конечное множество символов (алфавит),
S* – множество всех конечных цепочек, составленных из S (слова),
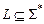 – подмножество S*, называемое языком.
– подмножество S*, называемое языком.
Соответствие между задачами распознавания и языками устанавливается с помощью схем кодирования. Схема кодирования e записывает каждую индивидуальную задачу из P словом в фиксированном алфавите S.
Множество S* делится задачей P и схемой кодирования e на 3 класса:
1) слова, не являющиеся кодами индивидуальных задач из P;
2) слова, являющиеся кодами с отрицательным ответом;
3) слова, являющиеся кодами с положительным ответом.
Третий класс слов обозначим 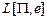 .
.

- Машины Тьюринга
Одноленточная детерминированная машина Тьюринга (ДМТ) представляет собой логическое устройство, которое состоит из:
1) неограниченной в обе стороны ленты, разделенной на одинаковые пронумерованные ячейки;
2) читающей/пишущей головки;
3) управляющего устройства с конечным числом состояний.
Схематически ДМТ можно представить в виде рисунка


Программу 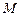 для ДМТ определяют следующие компоненты:
для ДМТ определяют следующие компоненты:
1) G – конечное множество символов, записываемых на ленте, 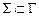 – множество входных символов,
– множество входных символов, 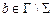 – выделенный пустой символ;
– выделенный пустой символ;
2) Q – конечное множество состояний, в котором выделено начальное состояние 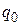 и два конечных –
и два конечных – 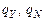 ;
;
3) функция переходов 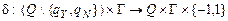 .
.
Т.е. 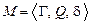 .
.
Порядок работы ДМТ под управлением программы .
1. Входное слово 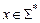 записывается на ленте в ячейках с номерами
записывается на ленте в ячейках с номерами 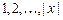 (
( 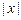 – длина слова x), все другие ячейки содержат пустой символ. Управляющее устройство находится в состоянии
– длина слова x), все другие ячейки содержат пустой символ. Управляющее устройство находится в состоянии 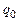 , а читающая/пишущая головка – над ячейкой с номером 1.
, а читающая/пишущая головка – над ячейкой с номером 1.
2. Если текущее состояние q не совпадает с одним из конечных состояний, то машина переходит в следующее состояние, определяемое согласно функции переходов. Пусть 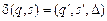 , где s – считанный головкой символ из текущей ячейки. Тогда управляющее устройство переходит в состояние
, где s – считанный головкой символ из текущей ячейки. Тогда управляющее устройство переходит в состояние 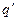 , головка вместо символа s записывает символ
, головка вместо символа s записывает символ 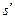 и сдвигается на одну ячейку влево, если
и сдвигается на одну ячейку влево, если 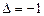 , или вправо, если
, или вправо, если 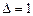 . Затем, текущим становится состояние .
. Затем, текущим становится состояние .
3. Если 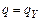 , то вычисления заканчиваются с результатом “да”, если
, то вычисления заканчиваются с результатом “да”, если 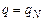 , то – с результатом “нет”.
, то – с результатом “нет”.
В качестве примера рассмотрим упоминавшуюся выше задачу распознавания “делимость на 4”. Построим ДМТ-программу 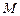 для решения этой задачи.
для решения этой задачи.
Для представления чисел будем использовать символы 0 и 1, а в качестве схемы кодирования – двоичную запись числа. Значит, 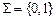 ,
, 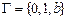 .
.
Опишем словесно действия ДМТ, а затем формализуем в виде программы . Число делится нацело на 4, если два последних символа в его двоичном представлении являются нулями. Поэтому, вначале машина будет считывать, повторять все символы входного слова и двигаться вправо, пока не дойдёт до пустого символа. После чего будет выполняться движение влево и анализ последнего и предпоследнего символа с последующей заменой его на символ b. Если хотя бы один из этих символов не равен 0, то результирующее состояние – 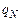 , в противном случае –
, в противном случае –  . При любом конечном состоянии результатом на ленте будет частное от целочисленного деления, причём, если
. При любом конечном состоянии результатом на ленте будет частное от целочисленного деления, причём, если 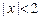 , то им является пустое слово, т.е. 0.
, то им является пустое слово, т.е. 0.
Представим функцию переходов наглядно в виде ориентированного графа. Вершинами графа будут являться состояния управляющего устройства, дуги графа означают переход из одного состояния в другое, причём, над каждой дугой будем писать символ(ы), по которому выполняется переход, а после знака ® – замещающий символ(ы) и направление движения головки.
Следовательно, 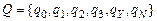 .
.

Функцию переходов d можно также задать табличным способом.
| q | s | ||
| b | |||
| q0 | (q0, 0, 1) | (q0, 1, 1) | (q1, b, -1) |
| q1 | (q2, b, -1) | (q3, b, -1) | (qN, b, -1) |
| q2 | (qY, b, -1) | (qN, b, -1) | (qN, b, -1) |
| q3 | (qN, b, -1) | (qN, b, -1) | (qN, b, -1) |
Программа , имеющая входной алфавит S, принимает слово 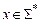 в том и только том случае, когда, будучи применённой ко входу x, она останавливается в состоянии . Язык
в том и только том случае, когда, будучи применённой ко входу x, она останавливается в состоянии . Язык 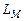 , распознаваемый программой , определяется следующим образом
, распознаваемый программой , определяется следующим образом
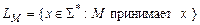 .
.
Если 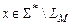 , то работа программы может либо завершиться в состоянии , либо бесконечно продолжаться без остановки. Будем говорить, что ДМТ-программа решает задачу распознавания P при схеме кодирования e, если
, то работа программы может либо завершиться в состоянии , либо бесконечно продолжаться без остановки. Будем говорить, что ДМТ-программа решает задачу распознавания P при схеме кодирования e, если 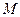 останавливается для любых и
останавливается для любых и 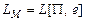 .
.
Работу ДМТ-программы 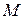 можно рассматривать, как вычисление некоторой функции
можно рассматривать, как вычисление некоторой функции 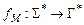 . Если слово
. Если слово 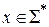 и программа останавливается на любом входе из S*, то результатом вычисления
и программа останавливается на любом входе из S*, то результатом вычисления 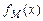 будет слово, составленное из символов, записанных на ленте после остановки машины в ячейках с 1-ой по последнюю непустую ячейку.
будет слово, составленное из символов, записанных на ленте после остановки машины в ячейках с 1-ой по последнюю непустую ячейку.
Функция 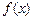 называется вычислимой (по Тьюрингу), если существует вычисляющий её алгоритм, т.е. $ программа , такая что
называется вычислимой (по Тьюрингу), если существует вычисляющий её алгоритм, т.е. $ программа , такая что 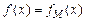 .
.
Свойства вычислимых функций.
1. Суперпозиция 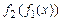 вычислимых функций
вычислимых функций 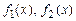 вычислима.
вычислима.
2. Любая вычислимая функция вычислима на машине Тьюринга с правой полулентой.
3. Если функции 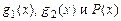 вычислимы, то разветвление
вычислимы, то разветвление  также вычислимо.
также вычислимо.
Выше мы каждому алгоритму поставили в соответствие функцию. Является ли верным обратное утверждение: можно ли для произвольной функции построить алгоритм её вычисляющий? Ответ на этот вопрос отрицательный, т.е. произвольная функция не является вычислимой. Выделим класс функций, для которых вычисляющий их алгоритм существует, таким образом, мы дадим другое определение алгоритма в терминах функций.
Дата добавления: 2016-06-13; просмотров: 2215;