Дополнительные материалы: Е2Е-проекты по системному анализу и моделированию
Данные проекты могут быть использованы как для обычной проектной работы (обучения), так в качестве тем для курсовых, дипломных проектов и научных исследований. Введем, по аналогии с B2B, P2P, С2С, мнемонический код E2E для обозначения "Экология для экономики" или "Экономика для экологии". Это обозначение может ассоциироваться также с системами типа "Электроника для экологии", или "Электроника для экономики", или "Электроника для эколого-экономического моделирования". Этот класс проблем наиболее важен для современного общества. Нижеследующие проекты предназначены для выработки навыков системного подхода и исследования, моделирования Е2Е-систем. 

А. Цель проекта и этапы выполнения проекта:
- изучение литературы общего (по системному анализу) и предметного характера (по рассматриваемой проблеме), выявление и описание элементов, целей, их приоритетов;
- определение и описание ресурсов исследования (математических, предметных, программных, технических, технологических);
- информационное обследование системы (сбор и изучение данных о системе, разработка необходимых спецификаций);
- выбор и описание критериев адекватности, устойчивости, эффективности системы;
- выбор метода (методов) и построение морфологической, функциональной и инфологической моделей системы;
- выбор и описание критериев адекватности, устойчивости, эффективности, идентификации модели, на основе соответствующих критериев системы;
- обсуждение и определение возможных критериев эффективности (полезности) принятия решений;
- алгоритмизация и программирование;
- отладка, тестирование, имитационные расчеты;
- оформление проектного решения (отчета).
Б. Структура группы разработчиков:
- постановщик проблемы - предметник (1 человек);
- системный аналитик (1);
- предметный аналитик (1-3, в зависимости от сложности выбранной системы);
- системный программист (1);
- прикладной программист (1-2);
- специалист по тестированию, тестировщик (1);
- специалист по презентациям (1);
- приемная комиссия - эксперты, консультанты (1, 3 или 5).
Возможно совмещение функций.
В. Критерии оценки проекта: актуальность темы (системы), полнота, адекватность, информативность, качество и другие системные критерии.
С. Ориентировочный перечень проблем (темы могут быть выбраны и по желанию преподавателя и/или студента):
1. Прогноз поливов и величины урожая - важная социально-экономическая и сельскохозяйственная задача. Наиболее известные способы определения влажности почвы - метеорологический и термостатно-весовой. Первый может не дать желаемой точности, а второй связан с большими материальными и временными затратами. Поэтому важно разработать имитационную процедуру, дающую достаточную точность и учитывающую физиологические характеристики сельхозкультур. Уравнение водного баланса расчетного корнеобитаемого слоя растений можно записать: W'(t)=q(t)P(t)+P1(t)-E(t)-(t), где P(t) - величина осадков; q(t) - коэффициент использования осадков (определяется, например, экспертно или по формуле Харченко С.И., через Wmin - наименьшую влагоемкость почвы и Wz - влажность завядания); P1(t) - подпитывание (приток) из грунтовых вод; E(t) - суммарное испарение из корнеобитаемого слоя; H(t) - уровень (сток) грунтовых вод, W(t) - средняя по слою влажность почвы (с учетом поливов или на межполивной период). Оценить и учесть влияние накопившейся к некоторому моменту времени биомассы растений на экологически обоснованную величину суммарного испарения в каждый момент времени. Величину суммарного испарения из корнеобитаемой зоны растений представить в виде суммы интенсивности транспирации растениями E1(t) и интенсивности испарения с поверхности почвы E0(t): E(t)=E0(t)+E1(t). Прирост биомассы описывается, например, уравнением x'(t)=a(t)E1(t)-b(t)x(t), где x(t) - биомасса культуры; a(t) - эффективность транспирации; b(t) - коэффициент расхода на дыхание. Для определения динамики накопления биомассы может использоваться банк различных моделей, из которых подбирается по тем или иным критериям адекватности наилучшая модель (по результатам идентификации). В рассматриваемой нами процедуре моделирования будем использовать простую для идентификации модель Ферхюльста-Пирла: x'(t)=[ε(t)-λ(t)x(t)]x(t), где ε - коэффициент роста (автоприроста), λ - коэффициент сопротивления среды (нехватки воды). Динамика прироста биомассы хорошо описывается уравнением Давидсона-Филиппа: х'(t)=e0(t)(F(t)-R(t)), где e0 - коэффициент перехода от массы усвоенной СО2 к сухой фитомассе; F - суммарный фотосинтез растений; R - суммарное дыхание растений. Интенсивность дыхания за сутки зависит от величины накопившейся биомассы. Экспериментально получено, что R(t)=b(t)x(t)+e1F(t), где e1 - коэффициент затрат на рост биомассы растений. Коэффициенты е0, е1 - экспериментально определяемые, для ряда культур ε0=0,68, ε1=0,27. Принимая во внимание приведенные уравнения и соотношения, имеем следующую модель расчета влажности почвы, с учетом динамики накапливаемой биомассы: W'(t)=q(t)P(t)+P1(t)-E(t)-H(t), E1'(t)=[ε(t)-λ(t)x(t)+b(t)]x(t)/a(t), Из этих соотношений имеем: b(t)=(1-e1)F(t)/x(t)-(ε(t)-λ(t)x(t))/e0. Для нахождения влажности почвы нам необходимо идентифицировать ε и λ. При постоянстве этих параметров (для простоты) можно использовать имитационную процедуру на основе метода наименьших квадратов:
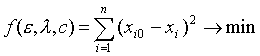
где i - номер фазы вегетации растения (i=1,2, ..., n); n - число фаз вегетации; xi0 - экспериментальные величины урожайности культуры за репрезентативный период времени; xi - теоретические величины урожайности сельхозкультур, определяемые по приведенной выше формуле. Фотосинтез F возможно учесть, например, с помощью формулы: F(t)=Fmaxe-μ[s(t)-z][λ(t)x(t)/ε(t)]2/3, где s(t) - текущая сумма биологически активных температур, z - сумма биологически активных температур для максимального развития листовой поверхности, m - эмпирический коэффициент. Одним из наиболее важных условий увеличения урожайности сельхозкультур является необходимая влажность почвы, которая позволит получить оптимальный режим орошения и, как следствие, - высокий урожай. Определить проектную урожайность для сравнительно длительных промежутков времени (фаз вегетации):
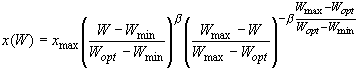
где x(W) - прогнозная урожайность; xmax - максимальная урожайность сельхозкультур; W - влагообеспеченность корнеобитаемого слоя почвы, определяется как описано выше; Wmin, Wmax - соответственно, нижняя и верхняя границы влагообеспеченности почвы, при которой урожай равен нулю; Wopt - влагообеспеченность, соответствующая xmax; β - параметр, характеризующий темпы роста урожая с увеличением влагообеспеченности.
2. Рассмотрим социо-эколого-экономическую проблему оценки степени загрязнения среды и воздействия загрязнителей на человека (животное, растение), а именно, интегральной оценки степени загрязненности среды для некоторых основных загрязнителей и оценки их влияния на человека и животное. При выборе загрязнителей учитываются: степень воздействия на экосистему; степень вредности (класс опасности) для человека; распространенность в биосфере; пороговый уровень содержания загрязнителя в атмосфере, при котором загрязнитель начинает свое воздействие; действие смеси загрязнителей, эффект суммирования воздействий. Например, для описанной ниже модельной ситуации были выбраны следующие загрязнители: сероводород, аммиак, двуокись углерода, двуокись азота, серная кислота, ацетон, двуокись серы, стирол, фтористый водород, окись углерода, этилацетат. Их выбор определялся как важностью для рассматриваемого объекта (гидрометаллургический объект), так и применением найденных открытых источников данных. С использованием многофакторного нелинейного анализа был получен ряд регрессионных зависимостей, а затем на их основе вычислены нормированные интегральные оценки загрязнения (приведенные к единице). Имитационная процедура строилась следующим образом. Пусть интегральная оценка загрязнения среды обозначается через y. Будем, для простоты, различать только 3 случая:
- слабо выраженное загрязнение - 0
 y(1)<1/3;
y(1)<1/3; - средне выраженное загрязнение - 1/3 y(2)<2/3;
- сильно выраженное загрязнение - 2/3 y(3) 1.
Под у понимается некоторая интегральная характеристика, оценка суммарного воздействия загрязнителей, например, она может быть ассоциирована с вероятностью загрязнения; оценки y(1), y(2) и y(3) могут быть выражениями оптимистической, реалистической и пессимистической оценок загрязнения среды. Используя регрессионный и корреляционный анализ, получаем экспериментальные зависимости уi=f(xi), где xi - фактор (загрязнителя) номер i, уi - оценка загрязнения по xi. Получены следующие результаты:
| Номер фактора | Зависимость для человека | Зависимость для животного |
| y=1,00000x | y=0,35714x | |
| y=0,0000029+1,17647x | y=0,09524x | |
| y=x/(0,0016+0,00007x) | y=x/(0,0014+0,00011x) | |
| y=2,10521x | y=1,11111x | |
| y=x/(0,0055+0,000068x) | у=x/(0,00666+1,00001x) | |
| Y=0,000013+0,351x | y=0,02857x | |
| y=x/(0,21+0,000115x) | y=0,02873x | |
| y=0,2941x | y=0,08x | |
| Y=0,0000991+2,41x | y=2,50x | |
| y=-0,00004+0,26317x | y=0,125x | |
| y=0,03634х | y=-0,00004+0,02778x |
Остаточная дисперсия этих зависимостей не более 0,0001. Затем, используя эти зависимости в качестве базисных функций, в результате нелинейного регрессионного анализа по базисной системе {fi} строятся зависимости вида y(j)=F(y1, y2,..., yn), j=1, 2, 3. При этом учитывается эффект суммирования влияния отдельных загрязнителей. Далее определяются оценки среднего ожидаемого загрязнения и его дисперсии для данной экологической системы. Приведенная процедура имитационного моделирования, при всей ее простоте, - технологична и позволяет оценивать загрязнение экосистемы, что актуально не только при экологическом, но и при социально-экономическом краткосрочном прогнозировании. Для слабо-, средне- и сильнозагрязненных участков (вдали, на среднем удалении, и вблизи от загрязнителя, например, от трубы гидрометаллургического завода) были получены зависимости для оценки интегрального влияния концентрации этих загрязнителей на человека:
y(1)=exp(-1,79+2,89x1+1732,87x2+11002,4x3+93,67x4+1980,42x5+1,58x6+26,14x7 +34,657x8+42,001x9+3,466x10+0,046x11)y(2)=exp(-0,81+0,58x1+67,58x2+2534,16x3+0,92x4+540,62x5+0,34x6+10,14x7 +0,20x8+8,11x9+0,37x10+0,02x11)y(3)=exp(-0,02+0,01x1+0,12x2+6,28x3+0,01x4+1,83x5+0,004x6+0,05x7 +0,003x8+0,02x9+0,003x10+0,37x11)Для тестового примера (случай слабого загрязнения): х1=х2=х3=0, х4=х5=х6=х7=0,0001, х8=х9=0,001, х10=х11=0,01 (мг/л) получаем оценку загрязненности этого имитационного полигона среды y(1)=0,23. При этом, используя аналогичные оценки для случаев средне- и сильнозагрязненных участков, получим y(2)=0,56 и y(3)=0,98, что согласуется с вышеприведенными гипотетическими оценками, для которых строилась модель. Математическое ожидание загрязнения среды и дисперсия: М=0,57, σ=0,02. Отметим, что если все хi=0 (i=1, 2, :, 11), то, например, y(1)=0,09. Это может быть отражением как меры адекватности модели, так и, скорее всего, присутствием в среде фонового загрязнения даже при нулевом загрязнении, что подтверждают известные экологи (Р.Г. Хлебопрос). Из приведенного модельного примера видно, что модель может быть полезна для планирования экологических и эколого-экономических мероприятий, например, последствий (штрафов) за экологические нарушения. Обобщить, усложнить ситуацию и провести аналогичное исследование.
3. При исследовании ряда экологических и социально-экономических систем часто достаточно бывает качественно оценить воздействия, особенно наиболее существенные, и определить причинно-следственные связи между воздействиями (человека, например) и вектором х состояния системы, x=(x1, x2, ..., xn), где хi - фактор экологического состояния, i=1, 2,..., n. Такого рода модели не позволяют нам оценить всю сложную и динамическую цепь взаимовлияний экологических параметров среды, но являются когнитивным инструментарием на начальных стадиях исследования системы, например, на этапе формализации и структурирования системы. Рассмотрим следующую процедуру проведения экспертизы и основанного на ней моделирования. Сформируем профессиональную (эффективную качественно и количественно) группу экспертов. Требования к качественному составу: общая эрудиция; профессионализм в данной области; психологическая совместимость; научный интерес и отсутствие материального интереса к проблеме; опыт, умения и навыки; самокритичность и критичность. Обычно это осуществляется анкетным опросом, тестированием. Количественная оценка компетентности потенциального i-го эксперта:
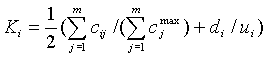
где cij - вес градации, перечеркнутой i-ым экспертом по j-ой характеристике в анкете, cjmax - максимальный вес (предел шкалы) j-ой характеристики в баллах, m - общее количество характеристик в анкете, di - вес ячейки, перечеркнутой экспертом в шкале самооценки в баллах, ui - предел шкалы самооценки эксперта в баллах. Оптимальная численность экспертной группы оценивается сложнее. Необходимо обеспечить высокий уровень компетентности экспертной группы и стабилизацию средней оценки прогнозируемой системы. Максимальная ее численность может быть оценена как
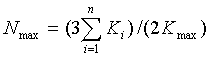
где Kmax - максимально возможная компетентность в выбранной системе шкал, n - количество испытуемых. Минимальная численность может быть оценена как Nmin=0,5(3/h+5), где h - допустимая величина изменения средней оценки в группе, при условии, что экспертная группа считается сформированной, если за нее голосовали не менее 2/3 испытуемых. Численность экспертной группы должна быть от Nmin до Nmax . После того, как экспертная группа сформирована, приступаем, собственно говоря, к процедуре моделирования. Выбирается, например, эмпирическим путем вектор состояния системы x  Ω, Ω - рассматриваемая область (среда), а также некоторые граничные векторы состояния среды a=(a1, a2, ..., an), b=(b1, b2, ..., bn), ai=min{xi}, bi=max{xi}, где минимум и максимум берется по всей области Ω. Составляется матрица V из элементов vij, где vij - степень влияния xi на xj, i=1,2,...,n. При этом можно использовать, например, подмодели корреляционного анализа. Далее выбираем начальное состояние х0 и проводим имитационные расчеты по заданной временной сетке. Управление моделью (траекторией поведения системы) можно осуществлять изменениями параметров xi, ai, bi, vij или выбором новой модели взаимодействия из некоторого банка моделей. Простыми моделями этого банка могут быть квадратичная, кубическая, дробно-рациональная, экспоненциальная, логарифмическая и другие зависимости. Используется также динамическое переупорядочивание связей в системе, модели (например, переход от одной модели к другой, более оптимальной по остаточной дисперсии). Наконец, оцениваем эффективность j-й траектории (имитационного варианта номер s, приводящего к решению номер r, 1 r R):
Ω, Ω - рассматриваемая область (среда), а также некоторые граничные векторы состояния среды a=(a1, a2, ..., an), b=(b1, b2, ..., bn), ai=min{xi}, bi=max{xi}, где минимум и максимум берется по всей области Ω. Составляется матрица V из элементов vij, где vij - степень влияния xi на xj, i=1,2,...,n. При этом можно использовать, например, подмодели корреляционного анализа. Далее выбираем начальное состояние х0 и проводим имитационные расчеты по заданной временной сетке. Управление моделью (траекторией поведения системы) можно осуществлять изменениями параметров xi, ai, bi, vij или выбором новой модели взаимодействия из некоторого банка моделей. Простыми моделями этого банка могут быть квадратичная, кубическая, дробно-рациональная, экспоненциальная, логарифмическая и другие зависимости. Используется также динамическое переупорядочивание связей в системе, модели (например, переход от одной модели к другой, более оптимальной по остаточной дисперсии). Наконец, оцениваем эффективность j-й траектории (имитационного варианта номер s, приводящего к решению номер r, 1 r R):

где N - число траекторий, cs - экспертная оценка значимости цели номер s, gsr(x) - функционал эффективности траектории s, приводящей к цели r. Определяем вероятность pzk предпочтения траектории номер z другой траектории с номером k и функцию правдоподобия этого предпочтения W:

где pz и pk - вероятности предпочтений для траекторий номер z, k, соответственно, dzk - экспертная (сравнительная) оценка траекторий z и k (ее можно взять, в частности, равной сумме оценок или баллов, при которых траектория z предпочиталась траектории k). Заметим, что более сложная и формализованная модель получается, если повторять имитационные расчеты с различными вероятностями pz и pk, уточняемыми каждый раз, например, следующим образом (qz - экспертная оценка траектории z, например, сумма баллов, в которой отмечалась траектория номер z):

Данная процедура и ее модификации могут быть использованы при реализации экспертных систем в различных областях. Реализуйте данную процедуру в одной информационной системе (например, в экспертной системе).
4. В качестве конкретного примера реализации имитационных вычислительных экспериментов рассмотрим модель качественного прогнозирования системы (процесса). При решении многих Е2Е-проблем, когда из-за длительности экологических процессов экспериментальное изучение становится практически невозможным, построение математических и компьютерных моделей часто является единственным способом принятия ключевых решений. Для разрешения многих эколого-экономических задач достаточно качественно промоделировать динамику развития системы. В рассматриваемой системе (модели) ключевую роль играют факторы состояния системы. Так как при построении модели учесть все факторы влияния практически невозможно, то модель данного типа не позволяет проследить всю сложную цепь взаимовлияния экологических параметров среды, но с ее помощью становится возможным оценить наиболее существенные эколого-экономические воздействия, а также определить причинно-следственные связи в данной экосистеме. Для каждого определяющего фактора задается его текущее, максимальные и минимальные значения границ его изменения или задается вектор состояния экосистемы x=(x1, x2,...:, xn) и два вектора границ его изменения: xmax=(x1max, x2max,..., xnmax), xmin=(x1min, x2min,..., xnmin), где n - число факторов. При этом для каждого фактора: ximin<xi<ximax. Для каждого фактора задается коэффициент влияния его на каждый из остальных, в том числе и на самого себя, т.е. строится матрица воздействий A:
| ... | n | |||
| a11 | a12 | ... | a1n | |
| a21 | a22 | ... | a2n | |
| ... | ... | ... | ... | ... |
| n | an1 | an2 | ... | ann |
Матрица имеет порядок n, где n - число рассматриваемых факторов. Коэффициент aij показывает степень влияния фактора xi на фактор xj. При равном взаимном влиянии факторов, элементы матрицы можно брать как коэффициенты парной корреляции. В дальнейшем, по этой заданной матрице воздействия, на каждом временном шаге будет вычисляться новое состояние каждого фактора в зависимости от состояния других. Затем проводится формирование вектора состояния системы. При нормировании каждому фактору присваивается значение, лежащее от 0 до 1, которое зависит от максимального и минимального значений:

В различных системах факторы взаимосвязаны между собой различным образом. Определяет эту связь не только матрица воздействия, но и функциональная зависимость одного фактора от других. В данной модели для простоты использованы два основных метода взаимосвязи, а именно линейная и экспоненциальная зависимость (расширение банка функций не принципиально). Основным предназначением данной системы является проведение учебных имитационных экспериментов для получения данных, качественно характеризующих состояние экосистемы в заданный момент времени. В ходе эксперимента на экран выводятся графики, показывающие состояние каждого из факторов в тот или иной момент времени. На каждом временном шаге система вычисляет новое состояние каждого фактора. В зависимости от выбранной гипотезы взаимодействия факторов, выбираем зависимость вида fi(x1,x2,...,xn), например,
fi(x1,x2,...,xn)=a1ix1+a2ix2+...+anixnдля линейной зависимости или
fi(x1,x2,...,xn)=exp(a1ix1+a2ix2+...+anixn)для экспоненциальной. Текущее состояние экосистемы можно представить точкой n-мерного пространства. В эксперименте экосистема пребывает во множестве таких точек, и совокупность их является траекторий развития системы. Управление экосистемой, траекторией ее развития, происходит при помощи изменения текущего состояния факторов, минимального и максимального их значений, редактирования матрицы влияния. Реализована возможность "записи и считывания экосистемы" в файл, что избавляет от необходимости каждый раз вводить параметры экосистемы. На экране отображается продолжительность эксперимента, факторы и приписываемая каждому фактору палитра цветов. После окончания эксперимента выводятся конечные значения факторов. Пользователь может сохранить их в отдельном файле для последующего использования. Реализовать соответствующую информационную систему прогнозирования.
5. Рассмотрим рынок жилья. Можно выделить два подхода к оценке жилья - использование математических и компьютерных оценок и использование экспертных оценок. В основе математической и компьютерной оценки лежит принцип статистической обработки большого массива объектов недвижимости и анализа зависимости цены объекта от его характеристик, таких как местоположение, износ, наличие улучшений и т.д. В процессе сбора данных поступает весьма разнородная информация. В случае неудовлетворительной адекватности производится корректировка модели путем изменения ее вида и введения новых переменных либо путем рекалибровки ее коэффициентов. Обычно набирается достаточное количество подобных объектов, и получаемый результат усредняется. Существует много статистических и моделирующих процедур для анализа рынка и построения модели, в частности, NCSS, AEP, Microcal Origin и др. Они достаточно сложны в использовании, хотя и предоставляют специалисту большие возможности. Имея хорошую базу данных, можно построить и настроить успешно работающую модель в течение 1-2 недель. Если же эксперту нужно разобраться в чужом рынке и начать выдавать приемлемые оценки, то среднее отклонение оценок рынка жилья по моделям относительно реальных цен не будет сильно отличаться от этой величины, причем эта оценка может выигрывать по среднему отклонению за счет фильтрации шумов во временных данных стоимости жилья. При условии достаточно полной, корректной и представительной базы данных, реальные и прогнозные средние примерно равны, и последние будут отражать наиболее вероятные цены сделок. С другой стороны, рыночная стоимость никогда не определена абсолютно точно, существует вариация стоимости каждого конкретного объекта и, соответственно, средняя вариация по базе. Моделирование рынка жилья, как правило, подстегивает инвестиции в недвижимость. В предлагаемой процедуре моделирования предпринята попытка анализа рынка жилья г. Нальчика и построения экономико-статистических оценок рынка. К сожалению, из-за отсутствия реальных данных по объему и ценам сделок, рынок пришлось моделировать на основе данных, полученных путем анализа объявлений в газетах "Синдика-Информ" и "Из рук в руки". Такие данные достаточно приблизительны и дают возможность анализа лишь предложения на рынке жилья, но этот подход вкупе с математическим и компьютерным анализом данных может оказаться одним из эффективных приемов при оценке качественного и среднестатистического состояния рынка жилья. При наличии данных не представляет трудностей переход и к проблеме анализа цен и спроса на рынке жилья. Цена на жилье зависит от ряда объективных качественных параметров, к которым можно отнести: месторасположение и время постройки дома; количество комнат; смежность комнат; общая площадь; жилая площадь; площадь кухни; этаж; этажность дома; материал стен; наличие балконов и лоджий; наличие телефона; удаленность от центра города; расположение относительно станций ж/д и автомагистралей; расположение относительно центров локального влияния (места работы); дата оценки. Цены на жилье в г. Нальчике сравнимы с ценами многих курортных и промышленных центров России. Материальную основу жилищного рынка в КБР составляет приватизированное жилье г. Нальчика. По данным различных источников в КБР, доля приватизированных квартир составляет 55 %, что близко к данным по Ставропольскому краю (56%), Ростовской области (51%), Северной Осетии - Алании (54%). Так как использовалась методика сбора данных по газетным объявлениям, необходимо было до компьютерного анализа (построения моделей) осуществить предварительную статистическую обработку. Простая процедура предварительной статистической обработки такова:
- Вычисляются средние величины x0 по 1, 2, 3, 4-комнатным квартирам.
- Вычисляются наибольшее xmax и наименьшее xmin в каждой из групп.
- Вычисляются наибольшие отклонения от среднего в каждой группе (или размах): dmax=| xmin (max) - x0|.
- Вычисляются относительные отклонения: w=dmax /x0 .
- Находим по таблице Стьюдента процентные точки для t(5%) и t(0,1%).
- Вычисляем соответствующие точки w(5%; n), w(0,1%; n).
- Если w(5%; n)>t(5%) (w(0,1%; n)>t(0,1%)), то отсеиваем грубое значение цены жилья и пересчитываем все заново (повторяем п.1-7).
По результатам, полученным после работы этого алгоритма, было проведено математическое и компьютерное моделирование по нахождению регрессионных зависимостей наилучшей адекватности вида: x=x(t), y=y(t), где x - оценка ($) стоимости 1 м2 жилья общей площади; y - оценка стоимости 1 м2 жилья жилой площади; t - время: t=1 - январь, t=2 - февраль и т.д. В результате проведенных достаточно громоздких и объемных расчетов (не приводимых по этой причине) выявлено, что наиболее адекватной формой модели является обратно-пропорциональная зависимость:
x(t)=1/(At+B), y(t)=1/(Ct+D),где регрессионные параметры A, B, C, D определяются на основе экспериментальных данных с использованием метода наименьших квадратов и линеаризующих замен:
X(t)=1/x(t), Y(t)=1/y(t).В результате такой замены обратно-пропорциональная зависимость линеаризуется, т.е. приводится к виду:
X(t)=At+B, Y(t)=Ct+D.Далее, в соответствии с методом наименьших квадратов, находим неизвестные A, B, C, D. После нахождения решений A, B, C, D можно осуществить обратную замену в обратно-пропорциональных зависимостях и найти регрессионные зависимости вида (с оценкой адекватности): x=x(t), y=y(t). Получены в результате моделирования адекватные модели регрессионного типа. Оценки адекватности этих моделей примерно равны 10-6 (остаточная дисперсия). Приведем ряд построенных моделей. Модель оценки средней стоимости 1 м2 общей площади по всем типам квартир по 1997-1998 годах: x(t)=1/(0,0044-0,00006 t). Модель средней стоимости 1 м2 жилой площади по всем типам квартир по 1997-1998 годах: x(t)=1/(0,0018-0,0009 t). Для сравнительного анализа и оценки адекватности модели были проделаны соответствующие расчеты по более точным данным риэлторских групп Москве. Были получены, соответствующие модели: x(t)=1/(0,000008 t+0,00098); y(t)=1/(0,000006 t+0,00061). Итак, наилучшей формой зависимостей при моделировании рынков жилья гг. Москвы и Нальчика (возможно, и других) является зависимость
x(t)=(a+bt)-1 , y(t)=(c+dt)-1 .Полученные модели можно использовать для прогнозных расчетов. Например, используя полученную для стоимости 1 м2 общей площади жилья г. Москвы формулу, можно рассчитать значение на февраль 1998 года (берем t=26):
x(26)=1/(0,000008×26+0,00098)=1/0,001188=941,75 ($).Это достаточно близко к данным риэлторских групп г. Москвы на февраль 1998 года - 957$. Отклонение составляет 1,5 %, модель приемлема. Необходимо проделать вышеприведенную работу (информационное обследование рынка жилья в Вашем городе и сбор данных, выполнение приведенной или более "тонкой" процедуры предварительной обработки, регрессионный анализ) для рынка жилья Вашего города.
6. Пусть относительное число лиц, желающих поменять свой Е2Е-выбор номер 1 на выбор номер 2 пропорционально числу x1 тех, кто уже сделал выбор 1 и относительной привлекательности выбора 2, т.е. числу a2x1/(a1+a2). Аналогично, число лиц, желающих поменять свой выбор 2 на выбор 1, будет пропорционально числу a1x2/(a1+a2). Если k1 и k2 - указанные коэффициенты пропорциональности, то можно записать модель динамики выбора решений из двух возможных:
x'1(t)=k1x1(a1x2/(a1+a2)-a2x1/(a1+a2)), x1(0)=x10 ,x'2(t)=k2x2(a2x1/(a1+a2)-a1x2/(a1+a2)), x2(0)=x20 .На выбор решения влияют различные факторы. Осуществить системный анализ этих факторов для некоторой выбранной Вами Е2Е-системы, построить соответствующую модификацию приведенной выше модели с "расщеплением" параметров модели (например, для простоты рассуждений, аддитивно), выполнить жизненный цикл моделирования с целью: а) выработки тактики увеличения (уменьшения) k1 и k2; б) идентификации параметров k1 и k2.
7. Популяцию рассматривают в качестве структурной единицы вида и единицы эволюции. Каждая популяция характеризуется определенной численностью (частотой, процентом или долей) особей с тем или иным признаком, ее изменениями во времени. В природе происходит постоянное колебание численности популяций: число особей то сокращается, то увеличивается. Неравномерность распределения особей одного вида в ареале обитания связана с колебаниями урожаев кормов, климатических условий (влажность, температура, освещенность), возрастным и половым составом особей, интенсивностью их размножения и продолжительностью жизни. К факторам эволюции, помимо естественного отбора - процесса, в результате которого выживают и оставляют после себя потомство преимущественно особи с полезными в данных условиях признаками, - относится также изоляция, т.е. возникновение различных преград к свободному скрещиванию особей. Перечисленные факторы повышают или понижают частоту различных генотипов в популяции и значительно усложняют зависимости в уравнении эволюции. Сокращение численности за некоторые пределы может привести к вымиранию генотипов популяции или к стационарности плотности особей. Пусть популяция состоит из трех генотипов с частотами x, y, z. Будем считать, что действует только естественный отбор, и вероятности доживания особей до репродуктивного возраста каждого генотипа определяются, соответственно, как a, b, c. Уравнения эволюции можно взять в виде
xi+1=xi+xi(a-axi-byi-czi), xo=d,yi+1=yi+yi(b-axi-byi-czi), y0=e,zi+1=zi+zi(c-axi-byi-czi), z0=m.Вероятности a, b, c, d, e, m можно задавать (как численно, так и с помощью функции распределения вероятностей) или генерировать датчиком случайных чисел. Осуществить системный анализ аналогичной Е2Е-системы, построить соответствующую модификацию приведенной выше модели, выполнить жизненный цикл моделирования с целью а) вычисления численности генотипов в каждый момент времени; б) определения, происходит ли вымирание особей каждого генотипа или же возникает ли момент, когда численность особей каждого генотипа становится стационарной; г) определения вероятности дожития особей до репродуктивного возраста; д) выяснения, как можно использовать эту систему (исследования) в пенсионном или страховом деле, например, для расчета страхового риска.
8. Рассмотрим базу знаний и экспертную Е2Е-системы с использованием аппарата нечетких множеств и нечеткой логики, которая позволит оценивать (в том числе - качественно) социо-экономико-экологическое состояние некоторой среды по задаваемым пользователем (экспертом) количественным оценкам тех или иных параметров среды (выбираемых из базы знаний системы). Для каждого входного фактора в диалоговом режиме задаются относительные (от 0 до 1) оценки влияния этого фактора (вес фактора). После анализа этих данных (этой экологической обстановки) система принимает, на основе базы знаний, решение о состоянии социо-экономико-экологической среды, используя количественную оценку (от 0 до 1) и десятибалльную (0-9) качественную систему оценок. Для автоматического получения базы знаний используется алгоритм классификации заданного класса. Пусть имеется набор объектов, которые необходимо разделить на группы. Определяется функция f(x,y) принадлежности нечеткого отношения типа "сходство" на заданном множестве объектов (для каждой пары объектов x, y). По этой функции определяется обычное (не нечеткое) отношение на множестве объектов, по которому эти объекты разбиваются на классы эквивалентности (классы, в которые попадают только элементы, эквивалентные по данному отношению). Для создания базы знаний (какого типа?) и обучения можно использовать процедуру вида:
- определение начальной выборки объектов;
- получение частотной таблицы на основе знаний экспертов (первый анализ выборки);
- фиксирование начальных правил вывода по этой таблице, например, правил типа "Если ... то ... ", "Если ... и если ... то ... ", "Если ... или если ... то ... " и др.;
- итерация (проход) по выборке, с попыткой предсказать исход для каждого объекта по текущим правилам;
- если предсказание - неудовлетворительное, то модификация правила;
- если процент ошибок неудовлетворителен или стабилизировался, то переход к пункту 4; иначе - вывод заключения системы об обстановке. Фрагмент базы знаний (до обучения) для фактора (параметра) "Состояние почвы" приведен в таблице. 16.1.
| Таблица 16.1. Фрагмент базы знаний | |
| Параметр | Частотная таблица |
| Контроль над эррозией | 5 5 5 6 8 10 12 14 16 15 16 |
| Сооружения для отдыха | 30 30 30 30 30 30 30 30 30 30 30 |
| Ирригация | 5 5 5 6 8 10 12 14 15 16 15 |
| Сжигание отходов | 5 5 5 6 8 10 12 14 16 15 16 |
| Строительство дорог | 15 16 15 14 12 10 8 6 5 5 5 |
| Строительство каналов | 5 5 5 6 8 10 12 14 16 15 16 |
| Плотины | 15 16 15 14 12 10 8 6 5 5 5 |
| Туннели | 16 15 16 14 12 10 8 6 5 5 5 |
| Буровые работы | 20 20 19 17 14 10 6 3 1 0 0 |
| Открытые разработки | 20 20 19 17 14 10 6 3 1 0 0 |
| Вырубка лесов | 15 16 15 14 12 10 8 6 5 5 5 |
| Охота и рыболовство | 30 30 30 30 30 30 30 30 30 30 30 |
| Растениеводство | 16 15 16 14 12 10 8 6 5 5 5 |
| Скотоводство | 15 16 15 14 12 10 8 6 5 5 5 |
| Химическое производство | 30 30 30 30 30 30 30 30 30 30 30 |
| Лесопосадки | 5 5 5 6 8 10 12 14 16 15 16 |
| Удобрения | 0 0 1 3 6 10 14 17 19 20 20 |
| Регулирование животных | 5 5 5 6 8 10 12 14 15 16 15 |
| Автомобильное движение | 16 15 16 14 12 10 8 6 5 5 5 |
| Трубопроводы | 30 30 30 30 30 30 30 30 30 30 30 |
| Хранение отходов | 15 16 15 14 12 10 8 6 5 5 5 |
| Борьба с сорняками | 16 15 16 14 12 10 8 6 5 5 5 |
| Течи и разливы | 30 30 30 30 30 30 30 30 30 30 30 |
Ниже приведен сценарий и протокол диалога с такой системой.
Протокол диалога (23.02.1998 - Понедельник, 11: 23: 37)
Входные данные:
- Контроль над эрозией: 0,6
- Сооружения для отдыха: 0,1
- Ирригация: 0,9
- Сжигание отходов: 1,0
- Строительство мостов и дорог: 0,6
- Искусственные каналы: 0,5
- Плотины: 0,3
- Туннели и подземные сооружения: 0,9
- Взрывные и буровые работы: 0,45667
- Открытая разработка: 0,567
- Вырубка лесов: 0,345
- Охота и рыболовство: 0,234
- Растениеводство: 0,678
- Скотоводство: 0,648
- Химическая промышленность: 0,2456
- Лесопосадки: 0,54846
- Удобрения: 0,6
- Регулирование диких животных: IGNORE (игнорируется фактор)
- Автомобильное движение: 0,6
- Трубопроводы: 0,0
- Хранилища отходов: 0,0
- Использование ядохимикатов: 0,2
- Течи и разливы: 0,0
Принятие решения о социо-экономико-экологической обстановке:
- Состояние почвы: 0,55177 (слабое положительное)
- Состояние поверхностных вод: 0,52969 (слабое положительное)
- Качественный состав вод: 0,62299 (некоторое положительное)
- Качественный состав воздуха: 0,61298 (некоторое положительное)
- Температура воздуха: 0,48449 (слабое отрицательное)
- Эрозия: 0,59051 (слабое положительное)
- Деревья и кустарники: 0,54160 (слабое положительное)
- Травы: 0,59051 (слабое положительное)
- Сельхозкультуры: 0,51698 (слабое положительное)
- Микрофлора: 0,48702 (слабое отрицательное)
- Животные суши: 0,59804 (слабое положительное)
- Рыбы и моллюски: 0,51525 (слабое положительное)
- Насекомые: 0,56000 (слабое положительное)
- Заболачивание территории: 0,50000 (слабое положительное)
- Курорты на суше: 0,52729 (слабое положительное)
- Парки и заповедники: 0,54668 (слабое положительное)
- Здоровье и безопасность: 0,62870 (некоторое положительное)
- Трудовая занятость людей: 0,51196 (слабое положительное)
- Плотность населения: 0,55539 (слабое положительное)
- Соленость воды: 0,48750 (слабое отрицательное)
- Солончаки: 0,57000 (слабое положительное)
- Заросли: 0,62935 (некоторое положительное)
- Оползни: 0,70588 (выраженное положительное)
9. Разработать экспертную систему для консультирования и экспертных суждений при решении задач: выработки (оптимизации) политики предоставления налоговых отчетов с целью уменьшения налоговых платежей законными методами (например, прогноза налоговых последствий операций с активами); легализации доходов и уменьшения сокрытия доходов. Ядро экспертной системы взаимодействует с приложениями типа "Мастер" для решения конкретных проблем. Данные вводятся из Книги доходов и расходов. Ядро экспертной системы взаимодействует (рис. 16.1) с приложениями типа "Мастер" для решения конкретных проблем: 1) Мастер Р (регистраций) решает задачу формулировки пользователем исходного состояния, заполнения отчетных документов; 2) Мастер Т (расходов и доходов) представляет необходимую информацию о доходах и расходах; Мастер О (оптимизации) решает задачу оптимальной легализации доходов, т.е. приведения в соответствие доходов и расходов; Мастер Д (отчетных документов) решает задачу своевременного и полного представления необходимых документов в налоговые органы; Мастер К (консультаций) решает задачи эксперта-консультанта при представлении данных.
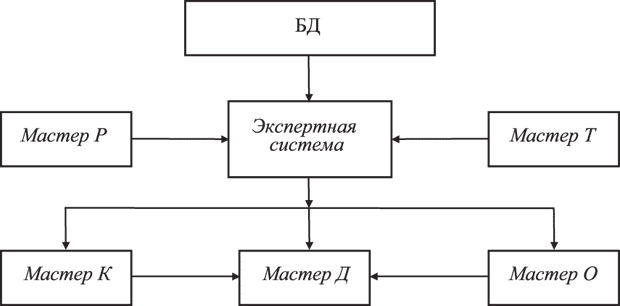
Рис. 16.1. Структура экспертной системы
10. Моделирование процесса обучения иностранному языку относится к классу плохо формализуемых и плохо структурируемых систем. Причина в том, что язык с его законами и правилами, которые имеют массу исключений, усложняющих процесс универсализации языковых явлений, плохо поддается формализации, а, следовательно, математическому описанию. Тем не менее, в последние годы уделяется большое внимание компьютерному и математическому моделированию процесса обучения иностранному языку. Известно, что лексический фонд любого языка достаточно велик и овладеть им полностью человек не в состоянии. Как правило, активный словарный запас взрослого равен приблизительно 10% всего запаса языка. Овладение языком зависит от наличия или отсутствия языковой среды. Практика показывает, например, что человек, изучающий иностранный язык вне языковой среды в течение 6 лет, должен овладеть 3000 слов. Это количество специально отобранных слов позволяет понять 95% любого текста. Специалисты в области преподавания языка (в частности, неродного) утверждают, что человек в течение одного двухчасового занятия может усвоить приблизительно 15 слов. Поэтому предполагается, что вначале можно усваивать 20-25 слов, а далее это количество уменьшить. Это мнение не распространяется на все системы обучения языку. Например, на протяжении ряда лет проводился обучающий эксперимент в Рижском педагогическом институте, который показал, что в состоянии релаксации (психического и физического расслабления, вызываемого внушением) за 20 минут студенты усваивали объем информации в виде фраз до 200 слов. Результаты и других экспериментов подтвердили, что в состоянии релаксации усваивается большой объем лексики. Она прочно запоминается и легко извлекается из памяти в процессе разговора. Существенную помощь в обучении языку может оказать компьютерное и математическое моделирование этого процесса, в частности, процесса обогащения (запоминания) словарного запаса учащихся. Выдвинем гипотезу: если человек обладает максимальной способностью запоминать слова, то словарный запас можно определять как xmax=const. Оставшийся до уровня насыщения xmax запас слов в момент времени t равен величине xmax-x(t)=y(t), где x(t) - количество слов, которые обучаемый запоминает в момент времени t (0<t T). Если исходить из гипотезы, согласно которой скорость изменения словарного запаса (темп изучения) прямо пропорционален x(t), то получаем уравнение:
где k - коэффициент пропорциональности, отражающий динамические характеристики темпа изучения. Решая это уравнение, можно получить закон изменения словарного запаса обучаемого:
x(t)=xmax(1-exp(-kt))+x0exp(-kt).В гипотезе не учитывались некоторые характеристики обучаемого и факторы, тормозящие обучение. Построить и исследовать новую аналогичную модель при новой гипотезе: k зависит от x по простому закону k=ax, где a>0 - некоторый параметр. Построить банк функций k и обучить модель на них. Предположив, что k колеблется в течении всего времени занятий, например, по закону k=A(C+sint), где A - коэффициент, определяемый с помощью уровня памяти, C - число, зависящее от t, определяющее работоспособность, построить и исследовать соответствующую модель. Рассмотреть во всех случаях 3 режима моделирования: а) скорость запоминания слов известна; б) скорость запоминания слов неизвестна; в) максимальный запас слов неизвестен. Для определения уровня памяти использовать простейший тест: пользователю предлагаются буквы, которые надо запомнить, а затем воспроизвести; уровень памяти - число правильно воспроизведенных букв, деленное на число всех букв и затем умноженное на 0,06. Применить к проблеме оценки времени достижения некоторого задаваемого запаса слов, например, сдачи TOEFL. Усложнить (улучшить) и исследовать модель.
Дата добавления: 2016-06-13; просмотров: 733;