Парная регрессия и корреляция. Функциональная и статистическая зависимость. Сущность регрессионного анализа.
Парная регрессия представляет собой регрессию между двумя переменными – y и x , т. е. модель вида: y f x = (y), где y – зависимая переменная (результативный признак); x – независимая, или объясняющая, переменная (признак-фактор). Знак «^» означает, что между переменными x и y нет строгой функциональной зависимости, поэтому практически в каждом отдельном случае величина y складывается из двух слагаемых: ɵ x y y = + ε , где y – фактическое значение результативного признака; ɵ x y – теоретическое значение результативного признака, найденное исходя из уравнения регрессии; ε – случайная величина, характеризующая отклонения реального значения результативного признака от теоретического, найденного по уравнению регрессии. Случайная величина ε называется также возмущением. Она включает влияние не учтенных в модели факторов, случайных ошибок и особенностей измерения. Ее присутствие в модели порождено тремя источниками: спецификацией модели, выборочным характером исходных данных, особенностями измерения переменных. От правильно выбранной спецификации модели зависит величина случайных ошибок: они тем меньше, чем в большей мере теоретические значения результативного признака ɵ x y , подходят к фактическим данным y . К ошибкам спецификации относятся неправильный выбор той или иной математической функции для ɵ x y и недоучет в уравнении регрессии какого-либо существенного фактора, т. е. использование парной регрессии вместо множественной.
Если зависимость между признаками указывает на линейную корреляцию, рассчитывают коэффициент корреляции r, который позволяет оценить тесноту связи переменных величин, а также выяснить, какая доля изменений признака обусловлена влиянием основного признака, какая – влиянием других факторов. Коэффициент варьирует в пределах от –1 до +1. Если r=0, то связь между признаками отсутствует. Равенство r=0 говорит лишь об отсутствии линейной корреляционной зависимости, но не вообще об отсутствии корреляционной, а тем более статистической зависимости. Если r = ±1, то это означает наличие полной (функциональной) связи. При этом все наблюдаемые значения располагаются на линии регрессии, которая представляет собой прямую.
Практическая значимость коэффициента корреляции определяется его величиной, возведенной в квадрат, получившая название коэффициента детерминации.
Выборочный коэффициент корреляции определяется равенством
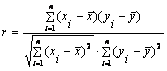 , (4.4)
, (4.4)
где хi, уi – варианты (наблюдавшиеся значения) признаков Х и Y; n – объем выборки; 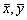 – выборочные средние.
– выборочные средние.
Функциональная зависимость – это связь, при которой каждому значению независимой переменной х соответствует точно определенное значение зависимой переменной y
Статистическая зависимость – это связь, при которой каждому значению независимой переменной х соответствует множество значений зависимой переменной y, причем неизвестно заранее, какое именно значение примет y
Регрессионный анализ заключается в определении аналитической формы связи, в которой изменение результативного признака обусловлено влиянием одного или нескольких факторных признаков, а множество всех прочих факторов, также оказывающих влияние на результативный признак, принимается за постоянные и средние значения
Цель
Оценка функциональной зависимости условного среднего значения результативного признака от факторных признаков.
Основной предпосылкой регрессионного анализа является то, что только результативный признак подчиняется нормальному закону распределения, а факторные признаки – произвольному закону распределения.
Уравнение регрессии, или модель связи социально-экономических явлений, выражается функцией
Линейная модель множественной регрессии. Спецификация эконометрической модели. Отбор факторов, включаемых в модели множественной регрессии. Фиктивные переменные. Линейное уравнение множественной регрессии.
Построение модели множественной регрессии является одним из методов характеристики аналитической формы связи между зависимой (результативной) переменной и несколькими независимыми (факторными) переменными.
Модель множественной регрессии строится в том случае, если коэффициент множественной корреляции показал наличие связи между исследуемыми переменными.
Общий вид линейной модели множественной регрессии:
yi=
где yi – значение i-ой результативной переменной,
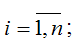
x1i…xmi – значения факторных переменных;
– неизвестные коэффициенты модели множественной регрессии;
– случайные ошибки модели множественной регрессии.
При построении нормальной линейной модели множественной регрессии учитываются пять условий:
1) факторные переменные x1i…xmi – неслучайные или детерминированные величины, которые не зависят от распределения случайной ошибки модели регрессии
2) математическое ожидание случайной ошибки модели регрессии равно нулю во всех наблюдениях:
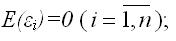
3) дисперсия случайной ошибки модели регрессии постоянна для всех наблюдений:
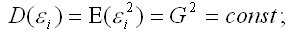
4) между значениями случайных ошибок модели регрессии в любых двух наблюдениях отсутствует систематическая взаимосвязь, т.е. случайные ошибки модели регрессии не коррелированны между собой (ковариация случайных ошибок любых двух разных наблюдений равна нулю):
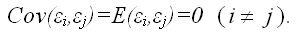
Это условие выполняется в том случае, если исходные данные не являются временными рядами;
5) на основании третьего и четвёртого условий часто добавляется пятое условие, заключающееся в том, что случайная ошибка модели регрессии – это случайная величина, подчиняющейся нормальному закону распределения с нулевым математическим ожиданием и дисперсией G2:
Общий вид нормальной линейной модели парной регрессии в матричной форме:
Y=X*
Где
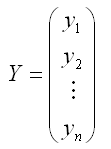
– случайный вектор-столбец значений результативной переменной размерности (n*1);

– матрица значений факторной переменной размерности (n*(m+1)). Первый столбец является единичным, потому что в модели регрессии коэффициент умножается на единицу;
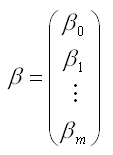
– вектор-столбец неизвестных коэффициентов модели регрессии размерности ((m+1)*1);
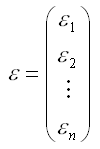
– случайный вектор-столбец ошибок модели регрессии размерности (n*1).
Включение в линейную модель множественной регрессии случайного вектора-столбца ошибок модели обусловлено тем, что практически невозможно оценить связь между переменными со 100-процентной точностью.
Условия построения нормальной линейной модели множественной регрессии, записанные в матричной форме:
1) факторные переменные x1j…xmj – неслучайные или детерминированные величины, которые не зависят от распределения случайной ошибки модели регрессии . В терминах матричной записи Х называется детерминированной матрицей ранга (k+1), т.е. столбцы матрицы X линейно независимы между собой и ранг матрицы Х равен m+1<n;< em=""></n;<>
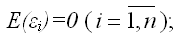
2) математическое ожидание случайной ошибки модели регрессии равно нулю во всех наблюдениях:
3) предположения о том, что дисперсия случайной ошибки модели регрессии является постоянной для всех наблюдений и ковариация случайных ошибок любых двух разных наблюдений равна нулю, записываются с помощью ковариационной матрицы случайных ошибок нормальной линейной модели множественной регрессии:
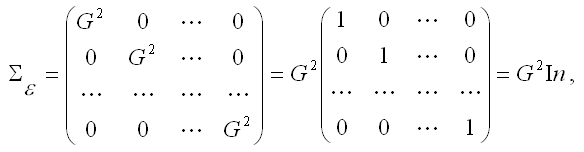
где
G2
In – единичная матрица размерности (n*n).
4) Х случайной величиной, подчиняющейся многомерному нормальному закону распределения с нулевым математическим ожиданием и дисперсией G2:
В нормальную линейную модель множественной регрессии должны входить факторные переменные, удовлетворяющие следующим условиям:
1) данные переменные должны быть количественно измеримыми;
2) каждая факторная переменная должна достаточно тесно коррелировать с результативной переменной;
3) факторные переменные не должны сильно коррелировать друг с другом или находиться в строгой функциональной зависимости.
Определение явного вида эконометрической модели называется спецификацией эконометрической модели.
При спецификации эконометрических моделей принято учитывать четыре принципа:
1) эконометрические утверждения и закономерности должны быть переведены на математический язык;
2) количество уравнений в модели должно быть равно числу эндогенных переменных;
3) переменные должны быть датированы;
4) в модель должен быть включён параметр случайной ошибки, чтобы охарактеризовать влияние случайных факторов.
Существуют следующие формы спецификации моделей:
1) структурная форма модели, когда эндогенные переменные не выражены явно через предопределенные переменные;
2) приведенная форма модели, когда эндогенные переменные представляют собой явно выраженные функции от предопределенных переменных.
Экономическим объектом в эконометрической модели Самуэльсона-Хикса является закрытая экономика.
Состояние закрытой экономики в текущем периоде t характеризуется переменными (Yt, Ct, It, Gt),
где Yt – валовой внутренний продукт (ВВП);
Ct – уровень потребления;
It – величина инвестиций;
Gt – государственные расходы.
При составлении спецификации модели Самуэльса-Хикса необходимо учесть следующие экономические утверждения:
1) текущее потребление объясняется уровнем валового внутреннего продукта в предыдущем периоде, увеличиваясь одновременно с ним, но с меньшей скоростью;
2) величина инвестиций прямо пропорциональна приросту валового внутреннего продукта за предшествующий период (прирост ВВП за предшествующий период определяется как разность Yt-lи Yt-2);
3) государственные расходы возрастают с постоянным темпом роста;
4) текущее значение валового внутреннего продукта представляет собой сумму текущих уровней потребления, инвестиций и государственных расходов (тождество системы национальных счетов).
Если вышеперечисленные экономические утверждения перевести на математический язык, то мы придём к спецификации модели вида (1):
Ct=a0+a1Yt–1,
It=b*(Yt–1–Yt-2),
Gt=g*Gt–1,
Yt=Ct+It+Gt,
при ограничениях:
0<a1<1,
b>0,
g>0.
Спецификация (1) модели близка к приведённой форме: текущие переменные Ct, It и Gt являются явными функциями предопределен–ных переменных, а переменную Yt можно сделать явной функцией путём подстановки правых частей первых трёх уравнений в правую часть четвёртого уравнения.
В итоге получим приведённую форму (2) модели Самуэльсона-Хикса:
Ct=a0+a1Yt–1,
It=b*(Yt–1–Yt-2),
Gt=g*Gt–1,
Yt=a0+a1Yt–1– b*(Yt–1–Yt-2)+g*Gt–1,
при ограничениях:
0<a1<1,
b>0,
g>0.
Основное отличие эконометрических моделей от других видов моделей заключается в обязательном включении в модель случайной ошибки.
Случайная ошибка характеризуется следующими свойствами:
1) математическое ожидание случайной ошибки при всех значениях эндогенной переменной равно нулю;
2) дисперсии случайной ошибки удовлетворяют свойству гомоскедастичности, т. е. постоянства дисперсий.
Запишем спецификацию модели вида (1) с учётом случайной ошибки:
Ct=a0+a1Yt–1, (3)
It=b*(Yt–1–Yt-2),
Gt=g*Gt–1,
Yt=Ct+It+Gt,
при ограничениях:
0<a1<1,
b>0,
g>0,
E(ut|Yt–1)=0,
σ(ut|Yt–1)=σu,
σ(νt|Yt–1,Yt-2)=σν,
E(wt|Gt–1)=0.
С учётом первой и третьей спецификаций модели Самэльсона-Хикса, получим приведённую форму данной модели (4):
Ct=a0+a1Yt–1,
It=b*(Yt–1–Yt-),
Gt=g*Gt–1,
Yt=a0+(a1+b)Yt–1– b*Yt–2+g*Gt–1+(ut+νt+wt)
при ограничениях:
0<a1<1,
b>0,
g>0.
Наиболее часто применяются два метод отбора факторов:
1. Метод исключения предполагает построение модели, включающей всю совокупность факторов, с последующим сокращением их числа до тех пор, пока все коэффициенты при факторах не будут иметь t-статистики, превышающие по модулю единицу. На каждом шаге исключается тот фактор, коэффициент при котором незначим и имеет наименьшую t-статистику.
2. Метод включения состоит в последовательном добавлении в модель факторов до тех пор, пока скорректированный коэффициент детерминации не перестанет увеличиваться. Первыми в модель включаются факторы, имеющие больший парный коэффициент корреляции с результатом Y.
Включение в уравнение множественной регрессии того или иного набора факторов связано прежде всего с представлениями исследователя о природе взаимосвязи моделируемого показателя с другими экономическими явлениями.
К факторам, включаемым в модель, предъявляются следующие требования:
1. Факторы должны быть количественно измеримы.Включение фактора в модель должно приводить к существенному увеличению доли объясненной части в общей вариации зависимой переменной. Поскольку данная величина характеризуетсякоэффициентом детерминации, включение нового фактора в модель должно приводить к заметному изменению коэффициента. Если этого не происходит, то включаемый в анализ фактор не улучшает модель и является лишним.
Например, если для регрессии, включающей 5 факторов, коэффициент детерминации составил 0,85, и включение шестого фактора дало коэффициент детерминации 0,86, то вряд ли целесообразно дополнять модель этим фактором.
Если необходимо включить в модель качественный фактор, не имеющий количественной оценки, то нужно придать ему количественную определенность. В этом случае в модель включается соответствующая ему «фиктивная» переменная, имеющая конечное количество формально численных значений, соответствующих градациям качественного фактора (балл, ранг).
Например, если нужно учесть влияние уровня образования (на размер заработной платы), то в уравнение регрессии можно включить переменную, принимающую значения: 0 – при начальном образовании, 1 – при среднем, 2 – при высшем.
Несмотря на то, что теоретически регрессионная модель позволяет учесть любое количество факторов, на практике в этом нет необходимости, т.к. неоправданное их увеличение приводит к затруднениям в интерпретации модели и снижению достоверности результатов.
2. Факторы не должны быть взаимно коррелированыи, тем более, находиться в точной функциональной связи. Наличие высокой степени коррелированности между факторами может привести к неустойчивости и ненадежности оценок коэффициентов регрессии, а также к невозможности выделить изолированное влияние факторов на результативный показатель. В результате параметры регрессии оказываются неинтерпретируемыми.
До сих пор в качестве факторов рассматривались экономические переменные, принимающие количественные значения в некотором интервале. Вместе с тем может оказаться необходимым включить в модель фактор, имеющий два или более качественных уровней. Это могут быть разного рода атрибутивные признаки, такие, например, как профессия, пол, образование, климатические условия, принадлежность к определенному региону. Чтобы ввести такие переменные в регрессионную модель, им должны быть присвоены те или иные цифровые метки, т.е. качественные переменные преобразованы в количественные. Такого вида сконструированные переменные в эконометрике принято называть фиктивными переменными.
Исследование зависимости заработной платы от наличия у работника высшего образования.
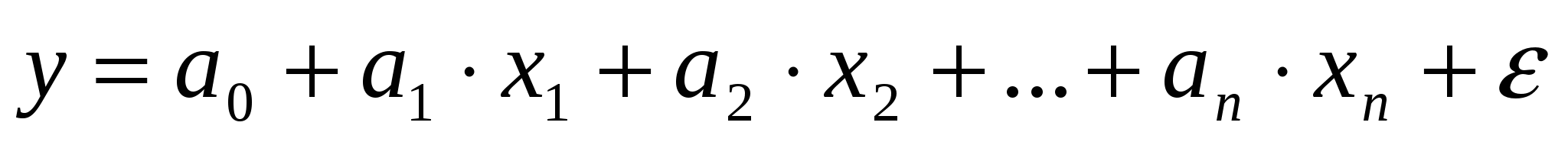
В дополнение к этим переменным введем фиктивную булеву переменную z:
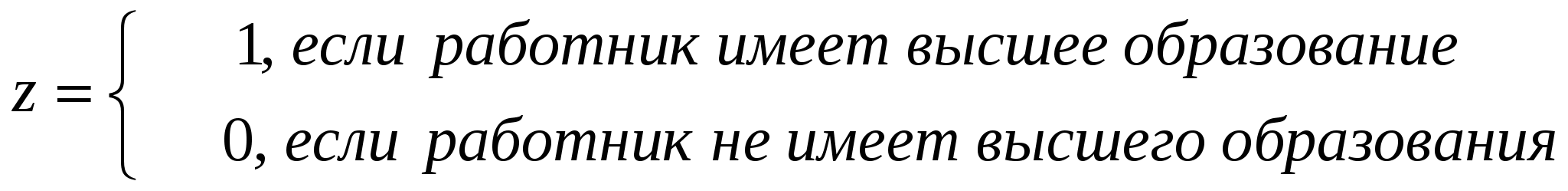 ;
;
Тогда уравнение регрессии будет иметь вид:
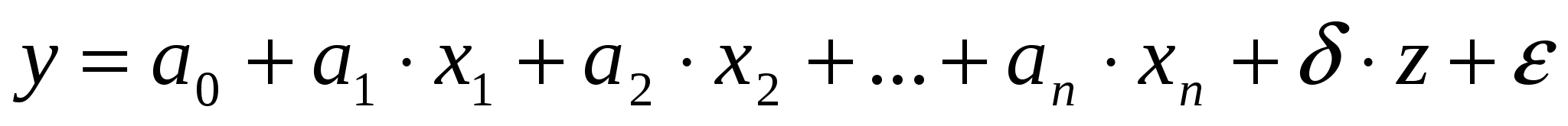
По статистическим данным, используя метод наименьших квадратов, мы получим оценки, в том числе и параметра 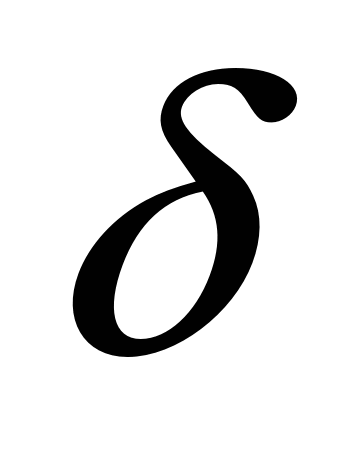 :
:
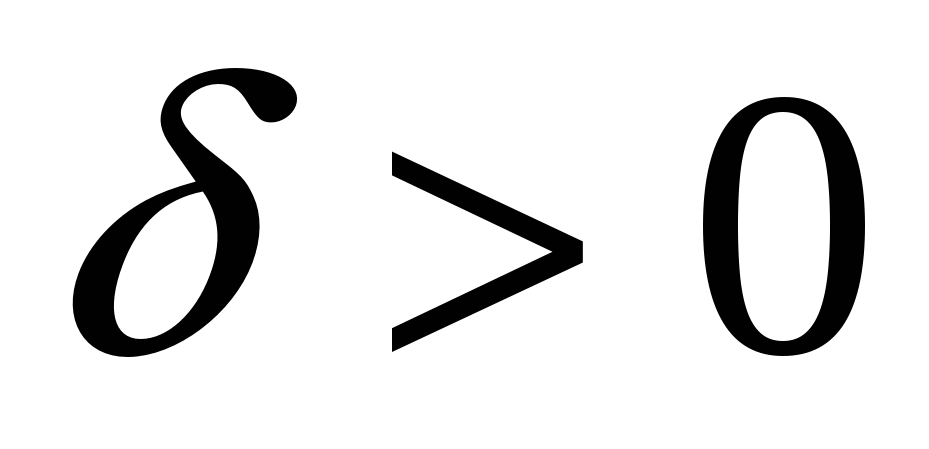 - высшее образование положительно влияет на заработную плату,
- высшее образование положительно влияет на заработную плату,
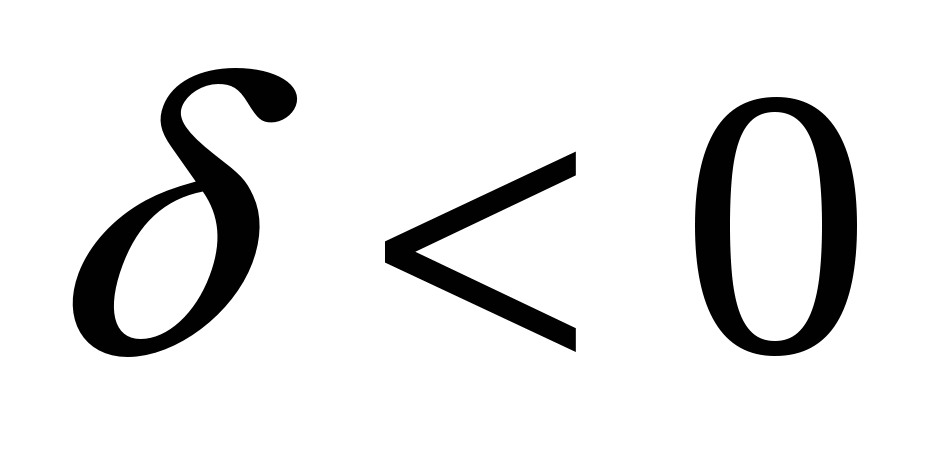 - работники с высшим образованием получают меньше, чем без высшего.
- работники с высшим образованием получают меньше, чем без высшего.
Задачей множественной линейной регрессии является построение линейной модели связи между набором непрерывных предикторов и непрерывной зависимой переменной. Часто используется следующее регрессионное уравнение:
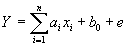 (1)
(1)
Здесь аi - регрессионные коэффициенты, b0 - свободный член(если он используется), е - член, содержащий ошибку - по поводу него делаются различные предположения, которые, однако, чаще сводятся к нормальности распределения с нулевым вектором мат. ожидания и корреляционной матрицей  .
.
Такой линейной моделью хорошо описываются многие задачи в различных предметных областях, например, экономике, промышленности, медицине. Это происходит потому, что некоторые задачи линейны по своей природе.
Приведем простой пример. Пусть требуется предсказать стоимость прокладки дороги по известным ее параметрам. При этом у нас есть данные о уже проложенных дорогах с указанием протяженности, глубины обсыпки, количества рабочего материала, числе рабочих и так далее.
Ясно, что стоимость дороги в итоге станет равной сумме стоимостей всех этих факторов в отдельности. Потребуется некоторое количество, например, щебня, с известной стоимостью за тонну, некоторое количество асфальта также с известной стоимостью.
Возможно, для прокладки придется вырубать лес, что также приведет к дополнительным затратам. Все это вместе даст стоимость создания дороги.
При этом в модель войдет свободный член, который, например, будет отвечать за организационные расходы (которые примерно одинаковы для всех строительно-монтажных работ данного уровня) или налоговые отчисления.
Ошибка будет включать в себя факторы, которые мы не учли при построении модели (например, погоду при строительстве - ее вообще учесть невозможно).
Уравнение множественной регрессии может быть представлено в виде:
Y = f(β , X) + ε
где X = X(X1, X2, ..., Xm) - вектор независимых (объясняющих) переменных; β - вектор параметров (подлежащих определению); ε - случайная ошибка (отклонение); Y - зависимая (объясняемая) переменная.
теоретическое линейное уравнение множественной регрессии имеет вид:
Y = β0 + β1X1 + β2X2 + ... + βmXm + ε
β0 - свободный член, определяющий значение Y, в случае, когда все объясняющие переменные Xj равны 0.
Метод наименьших квадратов (МНК). Оценка параметров линейных уравнений регрессии. Предпосылки МНК, методы их проверки. Свойства оценок параметров эконометрической модели, получаемых при помощи МНК.
Метод наименьших квадратов (МНК) — математический метод, применяемый для решения различных задач, основанный на минимизации суммы квадратов отклонений некоторых функций от искомых переменных. Он может использоваться для «решения» переопределенных систем уравнений (когда количество уравнений превышает количество неизвестных), для поиска решения в случае обычных (не переопределенных) нелинейных систем уравнений, для аппроксимации точечных значений некоторой функции. МНК является одним из базовых методов регрессионного анализа для оценки неизвестных параметров регрессионных моделей по выборочным данным.
Для оценки параметров уравнения множественной регрессии применяют метод наименьших квадратов (МНК). Для линейных уравнений регрессии (и нелинейных уравнений, приводимых к линейным) строится система нормальных уравнений, решение которой позволяет получить оценки параметров регрессии. В случае линейной множественной регрессии y = a + b • x + b • x0 +... + b • x
J 112 2 p p
система нормальных уравнений имеет следующий вид:
Z y=п •a+ь Z xi+Ь2 Z X2 +...+bp Z xp; Z yxi = aZ xi+bi Zx2+b2 Z x2 xi +...+bp Z xpxi;
Z yxp = aZ xp+bi Z xi xP+b2 Z x2 xP+...+bp Z x?.
Для определения значимости факторов и повышения точности результата используется уравнение множественной регрессии в стандартизованном масштабе
'y=b • tx,+b • fx, +...+bp • t4 (?.3)
где ty, tx ,..., tx - стандартизованные переменные
y - y x. - x.
t = , t .=-? L, (2.4)
y 67 xi S
y xi
для которых среднее значение равно нулю ty = tx = 0, а среднее квадратичес- кое отклонение равно единице s = s = 1.
y xi
Величины в; называются стандартизованными коэффициентами регрессии.
К уравнению множественной регрессии в стандартизованном масштабе применим МНК. Стандартизованные коэффициенты регрессии (в-коэффициенты) определяются из следующей системы уравнений:
Z % =b Z +b Z 'x, +b Z 'з +...+bP Z 4 ;
Z tytXl =bi Z tx, tx, + b Z '1 +b Z tx, tx3 +...+ bP Z tx, txp;
2Z 'y'xp =b Z 'xi 'xp +b2 Z 'x, 'xp +b Z 'x3 'xp + ... + bp Z '
либо из системы уравнений
ryx, = Pi + Arx,x + brx3xi + ... + ;
ryx, = birxix2 + p2 + p3rx3x, + ... + Pprxpx, ;
ryxp =birxixp +P2 rx, xp +P3 rx3xp + ... + bp .
Стандартизованные коэффициенты регрессии показывают, на сколько сигм (средних квадратических отклонений) изменится в среднем результат, если со-ответствующий фактор х изменится на одну сигму при неизменном среднем уровне других факторов. В силу того, что все переменные заданы как центрированные и нормированные, стандартизованные коэффициенты регрессии сравнимы между собой. Сравнивая их друг с другом, можно ранжировать факторы по силе их воздействия на результат. В этом основное достоинство стандартизованных коэффициентов регрессии в отличие от коэффициентов «чистой» регрессии, которые несравнимы между собой.
В парной зависимости стандартизованный коэффициент регрессии в есть не что иное, как линейный коэффициент корреляции гух.
Связь коэффициентов множественной регрессии bi со стандартизованными коэффициентами в і описывается соотношением ?
i Hi 8xi
Параметр а определяется из соотношения a = у - b1 x1 - b2 x2 -... - bpxp.
При оценке параметров уравнения регрессии применяется МНК. При этом делаются определенные предпосылки относительно составляющей 
 , которая представляет собой в уравнении
, которая представляет собой в уравнении 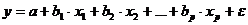 ненаблюдаемую величину.
ненаблюдаемую величину.
Исследования остатков 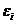 предполагают проверку наличия следующих пяти предпосылок МНК:
предполагают проверку наличия следующих пяти предпосылок МНК:
1) случайный характер остатков. С этой целью строится график отклонения остатков от теоретических значений признака. Если на графике получена горизонтальная полоса, то остатки представляют собой случайные величины и применение МНК оправдано. В других случаях необходимо применить либо другую функцию, либо вводить дополнительную информацию и заново строить уравнение регрессии до тех пор, пока остатки не будут случайными величинами.
2) нулевая средняя величина остатков, т.е. 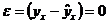 , не зависящая от хi. Это выполнимо для линейных моделей и моделей, нелинейных относительно включаемых переменных. С этой целью наряду с изложенным графиком зависимости остатков от теоретических значений результативного признака ухстроится график зависимости случайных остатков от факторов, включенных в регрессию хi . Если остатки на графике расположены в виде горизонтальной полосы, то они независимы от значений xj. Если же график показывает наличие зависимости и хj то модель неадекватна. Причины неадекватности могут быть разные.
, не зависящая от хi. Это выполнимо для линейных моделей и моделей, нелинейных относительно включаемых переменных. С этой целью наряду с изложенным графиком зависимости остатков от теоретических значений результативного признака ухстроится график зависимости случайных остатков от факторов, включенных в регрессию хi . Если остатки на графике расположены в виде горизонтальной полосы, то они независимы от значений xj. Если же график показывает наличие зависимости и хj то модель неадекватна. Причины неадекватности могут быть разные.
3. Гомоскедастичность — дисперсия каждого отклонения одинакова для всех значений хj. Если это условие применения МНК не соблюдается, то имеет место гетероскедастичность. Наличие гетероскедастичности можно наглядно видеть из поля корреляции.
4. Отсутствие автокорреляции остатков. Значения остатков распределены независимо друг от друга. Автокорреляция остатков означает наличие корреляции между остатками текущих и предыдущих (последующих) наблюдений. Отсутствие автокорреляции остаточных величин обеспечивает состоятельность и эффективность оценок коэффициентов регрессии.
5. Остатки подчиняются нормальному распределению.
В тех случаях, когда все пять предпосылок выполняются, оценки, полученные по МНК и методу максимального правдоподобия, совпадают между собой. Если распределение случайных остатков не соответствует некоторым предпосылкам МНК, то следует корректировать модель, изменить ее спецификацию, добавить (исключить) некоторые факторы, преобразовать исходные данные, что в конечном итоге позволяет получить оценки коэффициентов регрессии aj, которые обладают свойством несмещаемости, имеют меньшее значение дисперсии остатков, и в связи с этим более эффективную статистическую проверку значимости параметров регрессии.
Метод наименьших квадратов (МНК), при котором рассчитывается сумма квадратов отклонений наблюдаемых значений результативной переменной 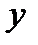 от теоретических значений
от теоретических значений 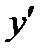 (рассчитанных на основании функции регрессии
(рассчитанных на основании функции регрессии 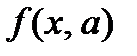 ). Согласно методу наименьших квадратов неизвестные параметры
). Согласно методу наименьших квадратов неизвестные параметры 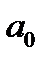 и
и 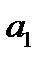 выбираются таким образом, чтобы сумма квадратов отклонений эмпирических значений
выбираются таким образом, чтобы сумма квадратов отклонений эмпирических значений 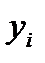 от теоретических значений
от теоретических значений 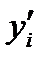 была минимальной. С учетом этого параметры уравнения регрессии определяются следующим образом:
была минимальной. С учетом этого параметры уравнения регрессии определяются следующим образом:
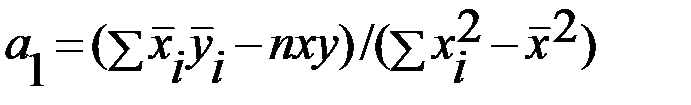 ,
,
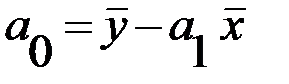 .
.
Достоинства МНК: сведение всех вычислительных процедур к простому вычислению неизвестных коэффициентов; доступность математических выводов.
Недостатки МНК: чувствительность оценок к резким выбросам, встречающимся в исходных данных. Метод наименьших квадратов является наиболее распространенным методом оценки неизвестных параметров модели парной линейной регрессии.
Дата добавления: 2016-05-25; просмотров: 2288;