Метод наименьших квадратов. Модель парной регрессии
Модель парной регрессии
В модели парной линейной регрессии зависимость между переменными в генеральной совокупности представляется в виде:
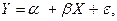 (2.1)
(2.1)
где X – неслучайная величина, а Y и e – случайные величины.
Величина Y называется объясняемой (зависимой) переменной, а X – объясняющей(независимой) переменной. Постоянные a, b – параметры уравнения.
Наличие случайного члена e (ошибки регрессии) связано с воздействием на зависимую переменную других неучтенных в уравнении факторов.
На основе выборочного наблюдения оценивается выборочное уравнение регрессии (линия регрессии):
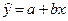 ,
,  (2.2)
(2.2)
где (а; b) – оценки параметров (a; b).
Метод наименьших квадратов
Рассмотрим задачу «наилучшей» аппроксимации набора наблюдений 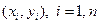 линейным уравнением (2.2).
линейным уравнением (2.2).
На рис. 8 приведены диаграмма рассеяния наблюдений и график линии регрессии.

Рис. 8
Величина  описывается как расчетное значение переменной yi, соответствующееxi. Наблюдаемые значения yi не лежат в точности на линии регрессии, то есть не совпадают с
описывается как расчетное значение переменной yi, соответствующееxi. Наблюдаемые значения yi не лежат в точности на линии регрессии, то есть не совпадают с  .
.
Определим остаток ei в i-ом наблюдении как разность между фактическим и расчетным значениями зависимой переменной, т.е.
 .
.
Неизвестные значения (a; b) определяются методом наименьших квадратов (МНК).
Сущность МНК заключается в минимизации суммы квадратов остатков:
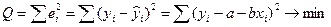 .
.
Здесь (хi, yi) – известные значения (числа), (а; b) – неизвестные.
Запишем необходимые условия экстремума:
 .
.
После преобразования получим следующую систему нормальных уравнений:
 .
.
Решение системы:
 (2.3)
(2.3)
Линия регрессии (расчетное значение зависимой переменной):
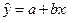 ,или
,или  .
.
Линия регрессии проходит через точку  и выполняются равенства:
и выполняются равенства:
 .
.
Коэффициентb есть угловой коэффициент регрессии и показывает, на сколько единиц в среднем изменяется переменная y при увеличении независимой переменной xна единицу.
Постояннаяa дает прогнозируемое значение зависимой переменной при x = 0. Это может иметь смысл в зависимости от того, как далеко находится x = 0 от выборочных значений x.
Можно показать, что
 ,
,
где r – коэффициент корреляции между x, y, а sx, sy – их стандартные отклонения.
Если коэффициент r уже рассчитан, то можно получить коэффициенты (a, b) парной регрессии.
После построения уравнения регрессии наблюдаемые значения y находим по:
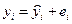 . (2.4)
. (2.4)
Остатки ei, как и ошибки ei являются случайными величинами, однако они, в отличие от ошибок ei, наблюдаемы.
Докажем, что  .
.
Действительно, используя равенства
 ,
,
получим
 .
.
Определим выборочные дисперсии величин  :
:
 – дисперсия наблюдаемых значений y;
– дисперсия наблюдаемых значений y;
 – дисперсия расчетных значений ;
– дисперсия расчетных значений ;
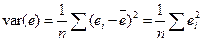 – дисперсия остатков e.
– дисперсия остатков e.
Дата добавления: 2016-02-16; просмотров: 1767;