Синтезируемые и наследуемые атрибуты
Каждому символу формальной грамматики присущи класс и значение. Скажем, если символом Е обозначено арифметическое выражение, то с ним может быть связано числовое значение, адрес памяти для числа, тип числа, признак обнаруженной в выражении ошибки и т.д. Все это значения символа Е. Рассмотренный ранее формализм перевода описывает перевод только той составляющей символа, которая характеризует его класс. Дальнейшее развитие теории компиляции касается значений символов.
Найти значение строки КС-языка можно, вычислив так называемые атрибуты в каждом узле дерева ее разбора. Атрибуты вычисляют по формулам, связанным с правилами грамматики языка. Атрибуты подразделяют на синтезируемые и наследуемые.
Синтезируемые атрибуты в некотором узле дерева зависят только от атрибутов в узлах-потомках. Значит, они служат для передачи информации по дереву снизу вверх, а в правилах грамматики — из правой части в левую.
Наследуемые атрибуты в некотором узле являются функциями атрибутов его узла-предка и (или) узлов-потомков этого предка. Такие атрибуты, как видим, могут распространять информацию в противоположном направлении.
Важно отметить, что КС-грамматика, снабженная атрибутами, сохраняет свои обычнее свойства и вместе с тем позволяет формально учесть контекстно-зависимые условия языка. А элементы контекстной зависимости присутствуют во всех языках программирования.
Рассмотрим суть синтезируемых атрибутов на примере, в котором синтаксический анализатор арифметических выражений выдает численное значение выражения. В этом простом примере операндами могут быть только константы. Т-грамматика выражений содержит единственный операционный символ (обозначим его [ЗНАЧ]) и имеет вид:
1) S ->Е[ЗНАЧ] 2)Е->Е+Т 3)E->T $)T->T*F 5) T->F
6) F->(E) 7) F->C
где VN = {S, E, T, F},
VT = {+, *, (,), С},
S — аксиома;
С — константа, значение которой во внутреннем представлении построил лексический анализатор.
Возьмем строку (С3 + С9)*С2 в качестве входной для синтаксического анализатора. В этом выражении подстрочными индексами указаны значения констант, которые и будем считать их атрибутами. Построим дерево разбора активной цепочки (C3+ С9)*С2[ЗНАЧ]24 и снабдим нетерминалы (в узлах дерева) значениями синтезируемых атрибутов (рис. 5.3 а).
Значение выражения формируется из значений его подвыражений по правилам (формулам), соответствующим правилам грамматики. Представим эти формулы математически, для чего в каждом правиле грамматики предусмотрим различные имена для разных значений атрибутов, а затем запишем соответствующие формулы. Атрибутом снабжается каждый нетерминал правила грамматики. Имена атрибутов обычно записывают как подстрочные индексы. Например, правилу Е —> Е+ Т транслирующей грамматики соответствуют правило Ер —> Eq+Tr и формула р=- q + r. Обозначения атрибутов в различных правилах не имеют между собой ничего общего и могут быть одинаковыми.
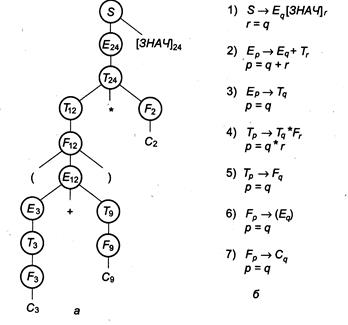
Рисунок 5.3 - а) Дерево разбора активной цепочки (С3+С9)*С2[ЗНАЧ]24
б) АТ-грамматика арифметических выражений
Полученные таким образом правила называют атрибутными, а грамматику с атрибутными правилами и формулами для атрибутов — атрибутной транслирующей грамматикой (АТ-грамматикой). Атрибутная транслирующая грамматика для нашего примера дана на рис. 5.3 б. Заметим, что атрибут операционного символа [ЗНАЧ] не относится к числу синтезируемых, он — наследуемый.
Теперь поясним смысл наследуемых атрибутов на примере, в котором синтаксический анализатор описания переменных помещает признак типа (real, int или boot) имени в соответствующее поле таблицы имен.
Пусть Т-грамматика описания переменных имеет вид:
1) описание —> Т V [тип] список
2) список —>, V [тип] список
3) список —> 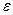
В этой грамматике символы "описание", "список*' — нетерминалы( VN); Т, V,, — терминалы (VT), [тип] 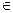
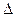 — операционный символ, где V — символ класса имен со значением, представленным указателем на элемент таблицы имен; Т— символ класса ключевых слов со значением, представленным указателем на real, int или bool. Запятая (,) — символ класса ограничителей. Операционный символ [тип] располагается в правилах вслед за именем V и предписывает поместить признак типа Т в поле "тип" записи переменной V таблицы имен. Поэтому значение [тип] определяется парой атрибутов (указ, тип), где "указ" — указатель на запись V в таблице имен, "тип" — значение Т.
— операционный символ, где V — символ класса имен со значением, представленным указателем на элемент таблицы имен; Т— символ класса ключевых слов со значением, представленным указателем на real, int или bool. Запятая (,) — символ класса ограничителей. Операционный символ [тип] располагается в правилах вслед за именем V и предписывает поместить признак типа Т в поле "тип" записи переменной V таблицы имен. Поэтому значение [тип] определяется парой атрибутов (указ, тип), где "указ" — указатель на запись V в таблице имен, "тип" — значение Т.
Введем атрибуты и формулы для их вычисления в грамматику описания переменных. Будем использовать имена ti, где i = 0, 1, 2,..., для обозначения атрибута "тип" (значение Т), именами pi обозначим атрибут "указатель" (значение V). Для передачи типа переменной из правила 1 в последующие снабдим нетерминал "список" атрибутом типа. Тогда АТ-грамматика описания переменных может выглядеть так:
1) описание —> Tr0 Vp0 [тип]р1,r1 список t2
t2,t1 = t0;p1 =p0
2) cnucoкr0 -> , Vp0 [min]p1,t1 списокt2
t2,t1 = t0; р1 =р0
3)списокr0 ->
Формула t2, t1 = t0 означает, что атрибуты t2 и t1 получают значение атрибута t0. Согласно формуле р1 = р1 атрибут р1 получит значение атрибута р0.
Возьмем в качестве примера описание real a, c1, abc. Синтаксический анализатор получит входную строку, которая в наших обозначениях выглядит так: Treal V1, V2 V3. Здесь 1, 2, 3 — номера позиций имен в таблице имен. Построим дерево разбора (рис. 5.1.4) соответствующей активной цепочки
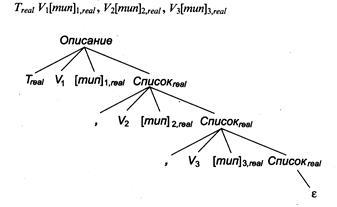
Рисунок 5.4 - Дерево разбора активной цепочки
Как видно из рассмотренных примеров, информация о синтезируемых атрибутах распространяется вверх по дереву (см. рис. 5.3), а информация о наследуемых — вниз по дереву (рис. 5.4).
Дата добавления: 2016-03-27; просмотров: 666;