Конвейерная обработка данных
При реализации конвейерной обработки выполнение каждой команды разбивается на несколько этапов (ступеней), аналогично сборке автомобиля на конвейере. Работа каждой ступени завершается за 1 такт работы МП. Результат на выходе конвейера появляется с каждым тактом МП (в идеальном случае).
Если команды однотипны, то появление результата на выходе не тормозится в ожидании завершения предыдущей команды.
| ВК | ДК | ФА | ПО | ВО | РР | |
| ВК | ДК | ФА | ПО | ВО | РР | |
| ВК | ДК | ФА | ПО | ВО | РР |
Если же используются разные типы команд, то возникает простой, когда на какой-то ступени конвейера ничего не выполняется.
| ВК | ДК | ПР | ПР | ВО | ПР | |||
| ВК | ДК | ОЖ | ОЖ | ФА | ПО | ВО | ПР | |
| ВК | ДК | ФА | ПО | ОЖ | ОЖ | ВО | ПР |
На рисунке приведен 6-ти ступенчатый конвейер. Весь процесс выполнения команды разбивается на 6 частей:
ВК – выборка очередной команды
ДК – декодирование очередной команды
ФА – формирование адреса операнда
ПО – прием операнда из памяти
ВО – выполнение операции
РР – размещение результата в памяти
ПР – простой
ОЖ – ожидание
Если возникает ситуация, когда нет данных с предыдущей команды для выполнения следующей команды, то происходит замедление работы конвейера, для приведенного на нижнем рисунке примера скорость падает в 5/3 раза. Эффективность работы конвейера будет тем ниже, чем более разнородные команды будут использованы (более эффективно работает конвейер при использовании RISC архитектуры, а при использовании CISC архитектуры наблюдается самая неэффективная работа).
С повышением тактовой частоты микрооперации приходится делать более элементарными, чтобы успеть выполнить их за 1 такт (1ГГц à такт 1 нс), следовательно, повышается количество ступеней конвейера для того, чтобы микрооперация успевала выполняться за 1 такт.
Команды условного ветвления могут сильно замедлить работу конвейера. Для того, чтобы повысить эффективность работы конвейера при работе с командами ветвления используются механизмы предсказания ветвления.
Простой механизм предсказания ветвления предполагает, что в очередной раз все будет так же, как в предыдущий. Вероятность правильного предсказания - до 80%.
Более сложный механизм предполагает использование статистики. Вероятность правильного предсказания – до 95%.
Суперскалярная структура.Возможность повышения производительности процессора достигается также путем включения в его структуру нескольких параллельных функционирующих операционных устройств, обеспечивающих одновременное выполнение нескольких операций, т.е. в процессоре имеется несколько исполнительных конвейеров, работающих параллельно. Такая структура МП называется суперскалярной. В идеале, в МП может одновременно обрабатываться столько команд, сколько в нем имеется операционных устройств. Реально при использовании от 4 до 10 операционных устройств удается обеспечить выполнение за такт от 2 до 6 команд, т.к. сложно обеспечить равномерную загрузку операционных устройств. Эффективная одновременная работа нескольких исполнительных конвейеров обеспечивается путем предварительной выборки и декодирования ряда команд и выделения среди них группы команд, которые могут использоваться одновременно. Обычно в МП используется несколько устройств для выполнения целочисленных операций, одно или несколько устройств для выполнения операций с плавающей точкой и отдельное устройство для обработки специальных форматов аудио и видео данных. Параллельно с ними работают устройства для формирования адресов и выборки операндов для исполняемых команд. Здесь реализуется спекулятивная (предварительная) выборка операндов.
В итоге результаты последующих команд могут быть доступны раньше результатов предыдущих. Результаты выполнения команд могут быть получены не в том порядке, в каком они записаны в программе. Для упорядочивания вводится специальный буфер, который устанавливает требуемый порядок выдачи результатов.
Одновременное выполнение команд может оказаться невозможным, если они обращаются к одному и тому же регистру. При ограниченной емкости РЗУ эта ситуация может возникать часто. Чтобы ее нейтрализовать, вводят специальные регистровые блоки, дублирующие основное РЗУ. Тогда, если происходит одновременное обращение к одному и тому же регистру, то один из запросов перенаправляется к дублирующему регистру – «переименование регистра».
На рис. 1.8 представлена суперскалярная структура Гарвардской архитектуры. В ней используются 2 конвейера по 6 степеней в каждом. Устройство управления обеспечивает выборку, декодирование и распределение команд.
В структуре присутствуют 2 устройства, которые работают с целочисленными данными (SIU1, SIU2), 1 устройство работает с данными в форме с плавающей запятой (FPU) и 1 устройство (MIU) выполняет сложные операции с целыми числами (умножение, деление).
Блок работы с числами с плавающей запятой обслуживается собственным набором регистров по 64 бита (блок FPR); дополнительно имеется буфер - 1 набор из 8 регистров по 32 бита, т.е. каждый из регистров блока имеет дублирующий регистр.
Блок DSU обеспечивает выборку операндов из памяти.
После выполнения операнды накапливаются в специальном буфере (блоке завершения), который и записывает их в память в требуемой последовательности.
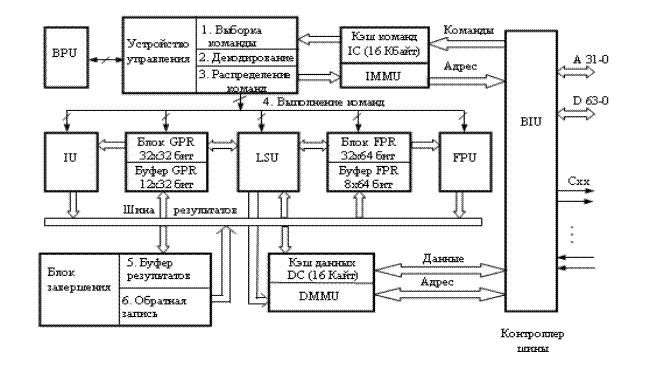 Рис. 1.8 Суперскалярная структура Гарвардской архитектуры Рис. 1.8 Суперскалярная структура Гарвардской архитектуры
|
Контрольные вопросы и задания
1. Приведите определение микропроцессора.
2. Что понимается под микропроцессорным комплектом?
3. Из каких блоков состоит микропроцессорная система?
4. В чем состоят различия между принстонской и гарвардской архитектурами?
5. Охарактеризуйте понятия линии, шины и магистрали.
6. Как работает мультиплексированная шина?
7. В чем особенности CISC, RISC и VLIW архитектур?
8. Чем отличается структура МП от архитектуры МП?
9. Дайте определение синхронных и асинхронных магистралей.
10. В чем состоит специфика шин адреса, данных и управления?
11. Как работает конвейер в МП?
12. Что такое суперскалярная структура МП?
Дата добавления: 2016-03-10; просмотров: 3459;