Глава 1. Описание набора признаков
МНОГОМЕРНЫЕ АНАЛОГИ ОДНОМЕРНЫХ СТАТИСТИЧЕСКИХ
МЕТОДОВ
Глава 1. Описание набора признаков
1.1 В одномерной биометрии рассматривалась ситуация изучения вариации одного отдельно взятого признака. Его величина у некоторого j-го индивида Xj была скаляром. Вся выборка таких значений у N индивидов с учетом матричных обозначений может считаться некоторым вектором. Пусть теперь мы имеем не один, а m признаков, рассматриваемых как нечто единое. Пусть этот набор показателей измерен у некоторого j-го индивида. Тогда этот набор индивидуальных значений признаков может быть записан в виде вектора-строки, имеющего длину соответствующую числу признаков m
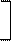
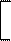
Xj' = X 1j X 2j X 3j …X mj . (1.1)
Такой вектор называется вектором индивидуальных наблюдений. Его реальным аналогом является антропологический бланк, на котором в определенной последовательности записаны значения всех изучаемых показателей у некоторого человека. Вектор наблюдений является многомерным аналогом отдельного наблюдения по какому-то признаку.
При исследовании некоторой выборки N индивидов мы будем иметь дело с N векторами индивидуальных наблюдений, из которых как из строк одинаковой длины можно составить прямоугольную матрицу
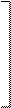


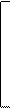
X'1 X11 X12 X13 …X1m
X'2 X21 X22 X23 …X2m
X= X'3 = X31 X32 X33 …X3m , (1.2)
… … … … … …
X’N XN1 XN2 XN3 …XNm
которая называется матрицей данных. Ее строками являются индивидуальные векторы наблюдений, а каждый столбец включает значения некоторого признака у всех N индивидов. Поэтому, она имеет размер m * N. Аналогом таблицы данных является электронная таблица с введенными в нее значениями признаков. Возможность формирования таких таблиц содержится в большинстве компьютерных статистических пакетов программ.
В одномерной биометрии для выборки N индивидуальных значений отдельного признака использовалось получение компактного описания, которое включало небольшую батарею показателей, таких как средняя арифметическая величина, среднее квадратическое отклонение, коэффициенты асимметрии и эксцесса и др.
- 5 -
По их значениям можно было сделать суждение о центральном уровне значений признака, его изменчивости, форме кривой его распределения.
Пусть теперь нам необходимо получить сходное описание для набора признаков X1, X2, X 3, …, X m. Для каждого i-го показателя мы можем вычислить среднюю арифметическую величину
N
 Mi = ∑ Xij
Mi = ∑ Xij
N j = 1
где N - объем выборки, i = 1, 2, 3, ..., m и j = 1, 2, 3, ..., N. Из совокупности средних арифметических величин для всех признаков можно составить вектор
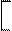
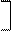
M' = M 1 M 2 M 3 …M m , (1.3)
который называется вектором средних и содержит всю необходимую информацию для суждения о размещении центров распределений всех признаков на числовых осях измерения их величины.
К понятию вектора средних можно придти иначе. Поступая с векторами индивидуальных наблюдений Xj как с отдельными значениями признака, когда необходимо получить его среднюю величину, можно найти вектор средних по обычной формуле
N
M= ∑ Xj
N j = 1
где j = 1, 2, 3, ..., N. Таким образом, вектор средних может рассматриваться как средняя арифметическая величина для векторов индивидуальных наблюдений. Он оказывается естественным многомерным аналогом средней арифметической величины по какому-то признаку.
1.3. В качестве показателя вариации каждого из m признаков можно вычислить дисперсию
1 N
 si2 = ∑ (Xij - Mi)2,
si2 = ∑ (Xij - Mi)2,
N – 1 j = 1
где N - объем выборки, i = 1, 2, 3, ..., m, и j = 1, 2, 3, ..., N. В одномерной статистике используется также корень квадратный из нее si - среднее квадратическое отклонение.
В качестве показателя соотносительной изменчивости любых двух i-го и k-го признаков может быть использована их ковариация
1 N
 covik = ∑ (Xij - Mi)(Xkj - Mk) .
covik = ∑ (Xij - Mi)(Xkj - Mk) .
N – 1 j = 1
Нетрудно видеть, что дисперсия и ковариация являются сходными показателями, описывающими изменчивость. Это становится еще более очевидным, если основу дисперсии – сумму квадратов отклонений наблюдений от средней -
- 6-
∑(Xij - Mi)2 переписать в ином виде - ∑(Xij - Mi)(Xij - Mi) . Тогда можно видеть, что дисперсия является своего рода ковариацией признака с самим собой. Это позволяет свести дисперсии m признаков и ковариации всех их попарных сочетаний в единую матрицу. Для достижения стандартного обозначения ее элементов можно воспользоваться символом sii для дисперсии i-го признака и sik- для ковариации i-го и k-го признака. Тогда такая матрица может быть записана в виде
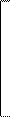 | 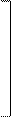 |
s11 s12 s13 … s1m
s12 s22 s23 … s2m
S = s13 s23 s33 …s3m . (1.4)
… … … … …
s1m s2m s3m … smm
Она называется ковариационной матрицей набора m признаков. Эта матрица - симметрическая, так как любой внедиагональный элемент sik, являющийся ковариацией i-го и k-го признаков, равен ski - ковариации k-го и i-го признаков. На главной диагонали находятся дисперсии всех отдельных m признаков - s11, s12, s33,. …smm. Ковариационная матрица является многомерным аналогом обычной дисперсии и включает все показатели изменчивости, которые можно найти для набора признаков.
Для любого признака можно перейти к нормированной его z-форме в соответствии с формулой
Xij - Mi
 zij = ,
zij = ,
si
где Xij - исходное значение i-го признака у j-го индивида, Mi - средняя арифметическая величина и si - среднее квадратическое отклонение i-го признака. Для нормированных значений zij характерно то, что они выражены в относительных неименованных величинах, имеют среднюю арифметическую величину, равную нулю, и среднее квадратическое отклонение, равное единице.
Для нормированных величин признаков ковариация превращается в коэффициент корреляции, так как его формула предполагает
covik
 rik =
rik =
si si
а средние квадратические отклонения нормированной формы i-го и k-го признаков равны единице (si = 1 и sk = 1).
Для нормированного набора признаков, составляющего векторы индивидуальных наблюдений,
zj' = z 1j z 2j z 3j … z mj . (1.5)
вектор средних включает нули
- 7 -

Mz' = 0 0 0 … 0 . (1.6)
В силу того, что для нормированного набора признаков дисперсии равны единице, а ковариации равны коэффициентам корреляции, ковариационная матрица приобретает специальный вид
| |  |
r11 r12 r13 … r1m
r12 r22 r23 … r2m
R = r13 r23 r33 …r3m , (1.7)
… … … … …
r1m r2m r3m … rmm
называемый корреляционной матрицей.
1.5. Ковариационная матрица S, являясь многомерным аналогом дисперсии отдельно взятого признака, в ряде случаев все же не вполне удобна для использования, так как не позволяет оценить интегративную величину вариации набора признаков одним скалярным числовым показателем. Для такой цели часто используется ее определитель │S│, который называется обобщенной дисперсией набора признаков. Наглядно пояснить смысл такого показателя удобнее на примере простейшего набора двух признаков X1 и X2.
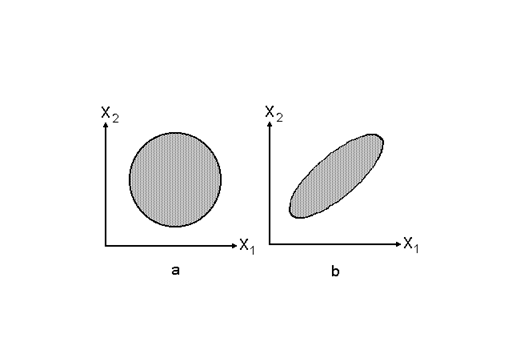
Рисунок 1.1. К определению обобщенной дисперсии двух признаков X1 и X2 при их взаимной некоррелированности (a) и в случае ненулевой тесноты связи (b)
- 8 -
В этом случае ковариационная матрица имеет вид
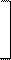

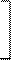
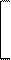
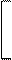 s11 s12 s12 cov12 s12 s1s2r
s11 s12 s12 cov12 s12 s1s2r
S = = =
s12 s22 cov12 s22 s1s2r s22
где s1 и s2- средние квадратические отклонения признаков, а r - коэффициент корреляции между ними. Определитель этой ковариационной матрицы или обобщенная дисперсия набора двух признаков X1 и X2 равен
│S│ = s11s22 - s12s12 = s12s22(1 - r2) . (1.8)
Рассмотрим его свойства. Пусть два признака нескоррелированы (r = 0). Тогда обобщенная дисперсия
│S│ = s12s22 (1.9)
равна произведению дисперсий двух признаков. Она будет тем больше, чем больше окажется суммарная величина показателей вариации каждого из двух признаков. Интуитивно этот результат вполне ясен.
В ситуации, когда между двумя признаками наблюдается ненулевая корреляция, эту статистическую связь можно описать при помощи прямолинейной регрессии
X2 = ao + a1X1.
В этом случае изменчивость признака X1 будет измеряться дисперсией s12, тогда как с учетом наличия регрессионной связи остаточную вариацию признака X2 опишет частная дисперсия
so22 = s22(1 - r2) .
Обобщенная дисперсия двух скоррелированных признаков может быть представлена в виде
│S│ = s12 sо22 , 1.10)
то есть как произведение двух дисперсий, описывающих два независимых компонента вариации. Ясно, что в ситуации коррелированности двух признаков их обобщенная дисперсия уменьшается тем сильнее, чем выше корреляция. При максимальной тесноте корреляционной связи (r = 1) обобщенная дисперсия становится равной нулю │S│ = 0.
Сказанное можно представить графически (рис.1.1) для признаков с равными дисперсиями. Ситуации r = 0 соответствует корреляционный эллипс, являющийся кругом. При появлении связи и по мере ее увеличения этот эллипс приобретает все более вытянутую форму. При этом его площадь сокращается и соответственно уменьшается разброс точек, соответствующих отдельным наблюдениям. Этому явно соответствует и уменьшение обобщенной дисперсии. В предельном случае, когда r = 1, все возможные значения X1 и X2 размещаются на линии регрессии, и никакой вариации наблюдений около нее не существует. В этой ситуации, естественно, обобщенная дисперсия становится нулевой.
Следует заметить, что существует рекомендация Л.А.Животовского (1984) в качестве обобщенной дисперсии использовать не определитель ковариационной матрицы │S│, а применять значения корня степени m из него (│S│)1/ m, где m - число признаков в наборе. Такой показатель не зависит от числа признаков.
- 9 -
Дата добавления: 2016-02-13; просмотров: 979;