Сущность ошибок репрезентативности и порядок их расчета
Один из центральных вопросов по выборочному методу – теоретический расчет основных статистических характеристик и прежде всего среднего значения признака в генеральной статистической совокупности. Это означает, что теоретически рассчитанная средняя выборочная величина и другие выборочные характеристики должны лишь минимально отличаться от соответствующих им генеральных статистических характеристик, т.е. выборка всегда должна давать достоверные, надежные, репрезентативные результаты.
Значение средней величины в генеральной совокупности может быть теоретически рассчитано по данным выборочной статистической совокупности следующим образом:
 , (8.1)
, (8.1)
где  – среднее значение признака в генеральной совокупности;
– среднее значение признака в генеральной совокупности; 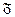 – среднее значение признака в выборочной совокупности; Δх – предельная ошибка выборки (предельная погрешность).
– среднее значение признака в выборочной совокупности; Δх – предельная ошибка выборки (предельная погрешность).
Формула 8.1 показывает, что среднее генеральное значение теоретически может отклоняться от среднего выборочного значения в большую или меньшую сторону на некоторую величину предельной погрешности.
Предельную ошибку выборки (Δх) теоретически можно рассчитать по формуле:
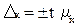 (8.2)
(8.2)
гдe t – доверительной коэффициент, зависящий от уровня вероятности Р;
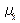 – средняя ошибка выборки.
– средняя ошибка выборки.
Доверительный коэффициент (t) означает, что по расчетному признаку генеральная совокупность "накрывается" доверительной областью. Он должен быть достаточно большим, т.е. отвечать принципу практической дoстоверности, надежности.
Доверительный коэффициент находится по специальной таблице, представляющей собой интегральную математическую функцию нормального распределения (приложение I).
Величина средней ошибки выборки зависит от вариации изучаемого признака в генеральной совокупности, объема (доли) выборки и способа отбора единиц для наблюдения. В связи с этим есть несколько приемов расчета средней ошибки выборки.
Средняя ошибка случайной и механической выборки, доля которой в генеральной совокупности относительно невелика, рассчитывается следующим образом:
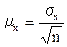 (8.3)
(8.3)
гдe – средняя ошибка выборки; 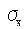 – среднее квадратическое отклонение признака в выборочной совокупности; n – число вариант выборочной совокупности (численность выборки).
– среднее квадратическое отклонение признака в выборочной совокупности; n – число вариант выборочной совокупности (численность выборки).
Допустим, необходимо рассчитать среднюю ошибку по массе меда, полученного от одной пчелосемьи, если известно, что выборочным обследованием охвачено 25 пчелосемей, а среднее квадратическое отклонение составило 10 кг. меда на одну пчелосемью. Для расчета средней ошибки выборки воспользуемся формулой 6.3 и получим:
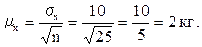
Таким образом, для заданных условий средняя ошибка составит 2 кг меда на одну пчелосемью.
В тех случаях, где доля выборки в генеральной совокупности довольно значительна, при использовании случайного и механического отбора средняя ошибка выборки может быть найдена по следующей формуле
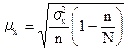 , (8.4)
, (8.4)
где 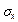 – дисперсия признака в выборочной совокупности; N – число единиц в генеральной совокупности (численность генеральной совокупности).
– дисперсия признака в выборочной совокупности; N – число единиц в генеральной совокупности (численность генеральной совокупности).
Если сравнить среднюю ошибку выборки, рассчитанную по формулам (8.3) и (8.4), то можно заметить, что с повышением численности выборки и ее приближения к генеральной численности величина средней ошибки неизбежно сокращается. Например, если дополнить условие предыдущей задачи показателем общей (генеральной) численности, которая составила допустим, 100 пчелосемей, то средняя ошибка выборки, рассчитанная по формуле (8.4), составит:
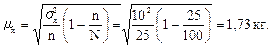
Таким образом, при случайном отборе, охватившем каждую четвертую пчелосемью, средняя ошибка составит 1,73 кг меда на одну пчелосемью.
В некоторых случаях варианты признака могут быть представлены в форме удельного веса (доли), например, доля сортовых посевов в общей посевной площади культур, доля чистопородного поголовья в общей численности голов и дp. В связи с этим при расчете средней ошибки выборки необходимо учитывать некоторые особенности. Причем не следует смешивать выборочную долю с долей выборки, так как выборочная доля – это варианта, выражающая удельный вес значения признака, а доля выборки представляет собой удельный вес численности выборки в составе генеральной совокупности.
Среднюю ошибку выборочной доли при случайном и механическом отборе, где удельный вес выборки относительно невелик, можно рассчитать следующим образом:
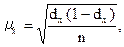 (8.5)
(8.5)
гдe dх – выборочная доля признака; n – численность выборки.
Если же удельный вес выборки в генеральной совокупности сравнительно высок, то при случайном и механическом отборе среднюю ошибку выборочной доли можно найти по формуле:
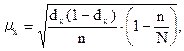 (8.6)
(8.6)
где N – численность генеральной совокупности.
Например, необходимо рассчитать среднюю ошибку выборки по доле чистопородных коров в стаде, насчитывающем 1000 голов, если по ее данным (100 голов) доля чистопородных коров составляет 0,4 (40 %), а среднеквадратическое отклонение доли коров — 0,2 (20 %). Воспользовавшись формулой (6.6), находим:
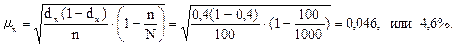
Следовательно средняя ошибка выборки по доле чистопородных коров во всем стаде составляет 0,046 (4,6 %}.
Целесообразно обратить внимание на то, что при использовании механического отбора обычно применяются те же приемы расчета средней ошибки выборки, что и при случайном отборе.
Расчет средней ошибки пропорциональной типической выборки имеет свои особенности. Дело в том, что разбивка генеральной совокупности на типические группы позволяет избегать влияния межгрупповой вариации на точность выборки, так как в типической выборке должны быть обязательно представлены статистические единицы всех типических групп, что может не иметь места при случайном отборе. Поэтому средняя ошибка типической выборки зависит только от средней из внутригрупповых дисперсий, а не от общей дисперсии, как это имеет место в случайной выборке.
Средняя ошибка пропорциональной типической выборки при случайном отборе рассчитывается следующим образом:
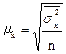 , (8.7)
, (8.7)
где  – средняя внутригрупповая дисперсия признака; n – численность выборки.
– средняя внутригрупповая дисперсия признака; n – численность выборки.
Если необходимо найти среднюю ошибку пропорциональной типической выборки при случайном отборе, где выборка из генеральной совокупности довольно значительна, то расчет этой ошибки проводится по формуле:
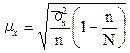 , (8.8)
, (8.8)
где N – численность единиц в генеральной совокупности.
Пример. Проведение типической пропорциональной случайной выборки для определения средней урожайности картофеля в крестьянских и личных подсобных хозяйствах характеризуется следующими данными (табл.8.1). По этим данным необходимо рассчитать среднюю ошибку выборки.
Т а б л и ц а 8. 1. Порядок расчета дисперсии при типическом отборе
| Категория хозяйств | Число хозяйств | Урожайность ц/га | Линейные отклонения урожайности, ц/га | Квадраты линейных отклонений | Взвешенные квадраты линейных отклонений | |
| всего | в т.ч. обследовано | |||||
| N | n | х0 | 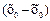
| 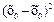
| 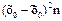
| |
| Фермерские | -85 | |||||
| Крестьянские | -35 | |||||
| Личные подсобные | ||||||
| ИТОГО | - | - | - |
Целесообразно рассчитать прежде всего среднюю выборочную урожайность картофеля во всех категориях частных хозяйств (по формуле средней арифметической взвешенной величины):
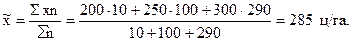
В свою очередь выборочная дисперсия урожайности картофеля по всем категориям частных хозяйств составит:

Теперь можно рассчитать среднюю ошибку выборки для условий, приведенных в табл. 8.1 по формуле (8.8):
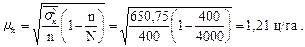
Следовательно, типический отбор в частных хозяйствах области показало, что средняя ошибка выборки по урожайности картофеля составит не менее 1,2 ц/га.
В условиях применения серийного отбора для расчета средней ошибки выборки обычно используют следующую формулу:
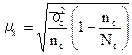 , (8.9)
, (8.9)
где 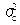 – дисперсия признака по выборочным сериям; nc – численность отобранных серий; Nс – общее число серий в генеральной совокупности.
– дисперсия признака по выборочным сериям; nc – численность отобранных серий; Nс – общее число серий в генеральной совокупности.
Известно, что при серийном способе отбора каждая серия выступает в качестве самостоятельной статистической единицы. Поэтому при таком способе средняя ошибка выборки зависит только от дисперсии, сформированной за счет колеблемости признака от серии к серии. Совершенно очевидно, что для расчета дисперсии необходимо взять средние значения признака по каждой отобранной серии и среднюю величину признака по выборочной совокупности в целом.
Пример. Выборочное наблюдение урожайности луговых земель в области проводилось при помощи отбора районов. По каждому отобранному району рассчитана средняя урожайность луговых земель. Необходимо определить среднюю ошибку выборки по урожайности луговых земель в области (табл. 8.2).
Т а б л и ц а 8.2. Порядок расчёта дисперсии при серийном отборе
| № серии | Число районов в каждой серии | Обследовано | Урожайность по сериям, ц/га | Линейные отклонения урожайности | Квадраты линейных отклонений |
| Nc | nc | 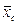
| 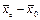
| 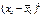
| |
| -40 | |||||
| -20 | |||||
| Σ |
Данные табл. 8.2 позволяют рассчитать прежде всего среднюю урожайность луговых земель по отобранным сериям:

Дисперсия урожайности луговых земель в отобранных сериях составит:
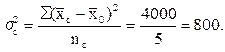
Теперь можно найти среднюю ошибку выборки по урожайности луговых земель в области, применив формулу (8.9):
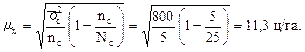
Следовательно, средняя ошибка серийного бесповторного отбора по урожайности луговых земель в области составляет 11,3 ц/га.
Дата добавления: 2016-02-20; просмотров: 789;