Эффективное кодирование
Сообщения, передаваемые с использованием систем связи (речь, музыка, телевизионные изображения и т.д.) в большинстве своем предназначены для непосредственного восприятия органами чувств человека и обычно плохо приспособлены для их эффективной передачи по каналам связи. Поэтому они в процессе передачи, как правило, подвергаются кодированию.
Что такое кодирование и зачем оно используется?
Под кодированием в общем случае понимают преобразование алфавита сообщения A{ xi }, ( i = 1,2…K ) в алфавит некоторым образом выбранных кодовых символов Â{ A{ xj }, (j = 1,2…N).
Кодирование сообщений может преследовать различные цели. Например, это кодирование с целью засекречивания передаваемой информации. При этом элементарным сообщениям xi из алфавита A{xi }ставятся в соответствие последовательности, к примеру, цифр или букв из специальных кодовых таблиц, известных лишь отправителю и получателю информации.
Другим примером кодирования может служить преобразование дискретных сообщений xi из одних систем счисления в другие (из десятичной в двоичную, восьмеричную и т. п., из непозиционной в позиционную, преобразование буквенного алфавита в цифровой и т. д.).
Кодирование в канале, или помехоустойчивое кодирование информации, может быть использовано для уменьшения количества ошибок, возникающих при передаче по каналу с помехами.
Наконец, кодирование сообщений может производиться с целью сокращения объема информации и повышения скорости ее передачи или сокращения полосы частот, требуемых для передачи. Такое кодирование называют экономным, безызбыточным, или эффективным кодированием, а также сжатием данных. В данном разделе будет идти речь именно о такого рода кодировании. Процедуре кодирования обычно предшествуют (и включаются в нее) дискретизация и квантование непрерывного сообщения x(t), то есть его преобразование в последовательность элементарных дискретных сообщений {xiq}.
Прежде чем перейти к вопросу экономного кодирования, кратко поясним суть самой процедуры кодирования.
Любое дискретное сообщение xi из алфавита источника A{ xi }объемом в Kсимволов можно закодировать последовательностью соответствующим образом выбранных кодовых символов xj из алфавита Â{xj }.
Например, любое число (а xi можно считать числом) можно записать в заданной позиционной системе счисления следующим образом:
xi = an-1×X n-1 + an-2×X n-2 +… + a0×X 0,
где X – основание системы счисления; a0 … an-1 – коэффициенты при имеющие значение от 0 до X –1.
Пусть, к примеру, значение xi = 59 , тогда его код по основанию X = 8, будет иметь вид
xi = 59 = 7·81+ 3·80=738 .
Код того же числа, но по основанию X = 4 будет выглядеть следующим образом:
xi = 59 = 3×42 + 2×41+ 3×40 = 3234.
Наконец, если основание кода X = 2, то
xi = 59 = 1×25 + 1×24 + 1×23 + 0×22 + 1×21 + 1×20 = 1110112 .
Таким образом, числа 73, 323 и 111011 можно считать, соответственно, восьмеричным, четверичным и двоичным кодами числа M = 59.
В принципе основание кода может быть любым, однако наибольшее распространение получили двоичные коды, или коды с основанием 2, длякоторых размер алфавита кодовых символов Â{ xj }равен двум, xj Ì 0,1.Двоичные коды, то есть коды, содержащие только нули и единицы, очень просто формируются и передаются по каналам связи и, главное, являются внутренним языком цифровых ЭВМ, т. е. без всяких преобразований могут обрабатываться цифровыми средствами. Поэтому, когда речь идет о кодировании и кодах, чаще всего имеют в виду именно двоичные коды. В дальнейшем будем рассматривать в основном двоичное кодирование.
Самым простым способом представления или задания кодов являются кодовые таблицы, ставящие в соответствие сообщениям xi соответствующие им коды (табл. 7.1).
Таблица 7.1
Соответствие кодовых комбинаций сообщения
| Буква xi | Число xi | Код с основанием 10 | Код с основанием 4 | Код с основанием 2 |
| А | ||||
| Б | ||||
| В | ||||
| Г | ||||
| Д | ||||
| Е | ||||
| Ж | ||||
| З |
Другим наглядным и удобным способом описания кодов является их представление в виде кодового дерева (рис. 7.1). Для того, чтобы построить кодовое дерево для данного кода, начиная с некоторой точки - корня кодового дерева – проводятся ветви – 0 или 1. На вершинах кодового дерева находятся буквы алфавита источника, причем каждой букве соответствуют своя вершина и свой путь от корня к вершине. К примеру, букве А соответствует код 000, букве
В – 010, букве Е – 101 и т.д.
Код, полученный с использованием кодового дерева, изображенного на рис. 7.1, является равномерным трехразрядным кодом.
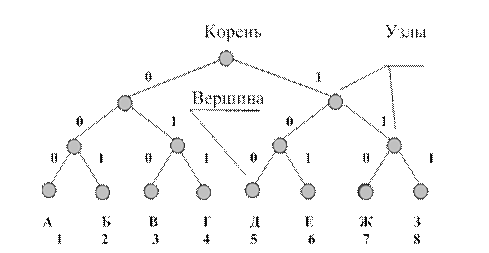
Рис. 7.1. Графическое представление кодового дерева
Равномерные коды очень широко используются в силу своей простоты и удобства процедур кодирования-декодирования: каждой букве – одинаковое число бит; принял заданное число бит – ищи в кодовой таблице соответствующую букву.
Наряду с равномерными кодами могут применяться и неравномерные коды, когда каждая буква из алфавита источника кодируется различным числом символов, к примеру, А - 10, Б – 110, В – 1110 и т.д.
Кодовое дерево для неравномерного кодирования может выглядеть, например, так, как показано на рис. 7.2.
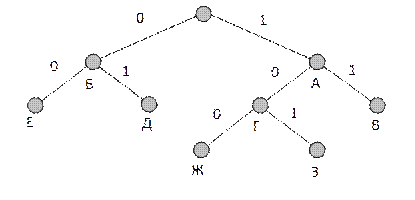
Рис. 7.2. Кодовое дерево для неравномерного кодирования
При использовании этого кода буква А будет кодироваться, как 1, Б – как 0, В – как 11 и т.д. Однако можно заметить, что, закодировав, к примеру, текст АББА = 1001 , мы не сможем его однозначно декодировать, поскольку такой же код дают фразы: ЖА = 1001, АЕА = 1001 и ГД = 1001. Такие коды, не обеспечивающие однозначного декодирования, называются приводимыми, или непрефиксными, кодами и не могут на практике применяться без специальных разделяющих символов. Примером применения такого типа кодов может служить азбука Морзе, в которой кроме точек и тире есть специальные символы разделения букв и слов. Но это уже не двоичный код.
Однако можно построить неравномерные неприводимые коды, допускающие однозначное декодирование. Для этого необходимо, чтобы всем буквам алфавита соответствовали лишь вершины кодового дерева, например, такого, как показано на рис. 7.3. Здесь ни одна кодовая комбинация не является началом другой, более длинной, поэтому неоднозначности декодирования не будет. Такие неравномерные коды называются префиксными.
Прием и декодирование неравномерных кодов - процедура гораздо более сложная, нежели для равномерных. При этом усложняется аппаратура декодирования и синхронизации, поскольку поступление элементов сообщения (букв) становится нерегулярным. Так, к примеру, приняв первый 0, декодер должен посмотреть в кодовую таблицу и выяснить, какой букве соответствует принятая последовательность. Поскольку такой буквы нет, он должен ждать прихода следующего символа. Если следующим символом будет 1, тогда декодирование первой буквы завершится – это будет Б, если же вторым принятым символом снова будет 0, придется ждать третьего символа и т.д.
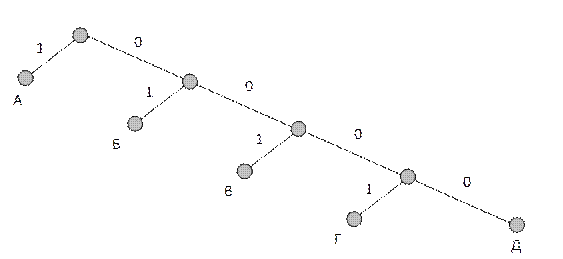
Рис. 7.3. Кодовое дерево для префиксного кода
Зачем же используются неравномерные коды, если они столь неудобны?
Рассмотрим пример кодирования сообщений xi из алфавита объемом K= 8с помощью произвольного n-разрядного двоичного кода.
Пусть источник сообщения выдает некоторый текст с алфавитом от Адо З и одинаковой вероятностью букв Р(xi )= 1/8.
Кодирующее устройство кодирует эти буквы равномерным трехразрядным кодом (см. табл. 7.1).
Определим основные информационные характеристики источника с таким алфавитом:
– энтропия источника 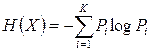 ,
, 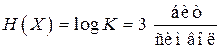 ;
;
– избыточность источника  ;
;
– среднее число символов в коде 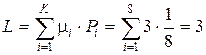 ;
;
– избыточность кода 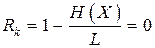 .
.
Таким образом, при кодировании сообщений с равновероятными буквами избыточность выбранного (равномерного) кода оказалась равной нулю.
Пусть теперь вероятности появления в тексте различных букв будут разными (табл. 7.2).
Таблица 7.2
Вероятности появления букв
| А | Б | В | Г | Д | Е | Ж | З |
| Ра=0,6 | Рб=0,2 | Рв=0,1 | Рг=0,04 | Рд=0,025 | Ре=0,015 | Рж=0,01 | Рз=0,01 |
Энтропия источника 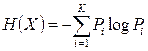 в этом случае, естественно, будет меньшей и составит H(X) = 1,781 бит/символ
в этом случае, естественно, будет меньшей и составит H(X) = 1,781 бит/символ 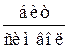 .
.
Среднее число символов на одно сообщение при использовании того же равномерного трехразрядного кода
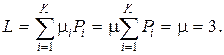
Избыточность кода в этом случае будет
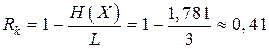 ,
,
или довольно значительной величиной (в среднем 4 символа из 10 не несут никакой информации).
В связи с тем, что при кодировании неравновероятных сообщений равномерные коды обладают большой избыточностью, было предложено использовать неравномерные коды, длительность кодовых комбинаций которых была бы согласована с вероятностью выпадения различных букв.
Такое кодирование называется статистическим.
Неравномерный код при статистическом кодировании выбирают так, чтобы более вероятные буквы передавались с помощью более коротких комбинаций кода, менее вероятные - с помощью более длинных. В результате уменьшается средняя длина кодовой группы в сравнении со случаем равномерного кодирования.
Операция кодирования тем более эффективна (экономична), чем меньшей длины кодовые слова сопоставляются сообщениям. Поэтому за характеристику эффективности кода примем среднюю длину кодового слова:

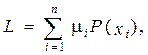 (7.1)
(7.1)
где 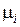 – длина кодового слова, сопоставляемая
– длина кодового слова, сопоставляемая  сообщению.
сообщению.
При установлении оптимальных границ для L исходят из следующих соображений. Во-первых, количество информации, несомое кодовым словом, не должно быть меньше количества информации, содержащегося в соответствующем сообщении, иначе при кодировании будут происходить потери в передаваемой информации. Во-вторых, кодирование будет тем более эффективным, чем большее количество информации будет содержать в себе каждый кодовый символ. Это количество информации максимально, когда все кодовые символы равновероятны, и равно 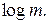 При этом i-е кодовое слово будет нести количество информации, равное
При этом i-е кодовое слово будет нести количество информации, равное 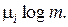
Шенноном сформулирована следующая теорема. При кодировании сообщений 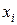 в алфавите, насчитывающем m символов, при условии отсутствия шумов, средняя длина кодового слова не может быть меньше, чем
в алфавите, насчитывающем m символов, при условии отсутствия шумов, средняя длина кодового слова не может быть меньше, чем
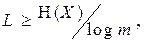 (7.2)
(7.2)
где H(X) – энтропия сообщения.
Если вероятности сообщений не являются целочисленными степенями числа m, точное достижение указанной границы невозможно, но при кодировании достаточно длинными группами к этой границе можно сколь угодно приблизиться.
Данная теорема не дает явных рецептов для нахождения кодовых слов со средней длиной (7.2), а поэтому она является теоремой существования. Важность этой теоремы состоит в том, что она определяет предельно возможную эффективность кода, позволяет оценить, насколько тот или иной конкретный код близок к самому экономному, и, наконец, придает прямой физический смысл одному из основных понятий теории информации – энтропии множества сообщений как минимальному числу двоичных символов (m = 2), приходящихся в среднем на одно сообщение.
Приведем два известных способа построения кодов, которые позволяют приблизиться к равновероятности и независимости кодовых символов.
Код Шеннона-Фано.
Для построения этого кода все сообщения Xi выписываются в порядке убывания их вероятностей (табл. 7.3).
Таблица 7.3
Построение кода Шеннона-Фано
| xi | P(xi) | Разбиение сообщений на подгруппы | Код | mi | Lxi | ||||||||
| x1 | 0,35 | 0,70 | |||||||||||
| x2 | 0,15 | 0,30 | |||||||||||
| x3 | 0,13 | 0,39 | |||||||||||
| x4 | 0,09 | 0,27 | |||||||||||
| x5 | 0,09 | 0,36 | |||||||||||
| x6 | 0,08 | 0,32 | |||||||||||
| x7 | 0,05 | 0,20 | |||||||||||
| x8 | 0,04 | 0,20 | |||||||||||
| x9 | 0,02 | 0,10 |
Записанные таким образом сообщения затем разбиваются на две по возможности равновероятностные подгруппы. Всем сообщениям первой подгруппы присваивают цифру 1 в качестве первого кодового символа, а сообщениям второй подгруппы – цифру 0. Аналогичное деление на подгруппы продолжается до тех пор, пока в каждую подгруппу не попадает по одному сообщению.
Найденный код весьма близок к оптимальному. В самом деле, энтропия сообщений:
|
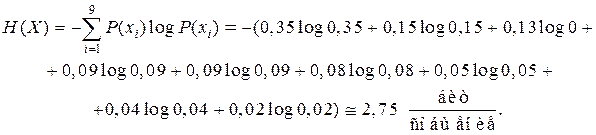
Средняя длина кодового слова:
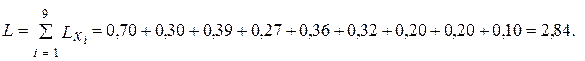 (7.4)
(7.4)
Среднее число нулей:
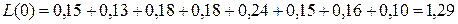 . (7.5)
. (7.5)
Среднее число единиц:
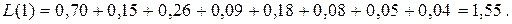 (7.6)
(7.6)
Вероятность появления нулей:
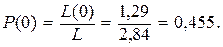 (7.7)
(7.7)
Вероятность появления единиц
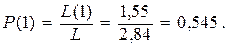 (7.8)
(7.8)
Таким образом, получили код близкий к оптимальному.
Код Хаффмана.
Для получения кода Хаффмана все сообщения выписывают в порядке убывания вероятностей. Две наименьшие вероятности объединяют скобкой (табл. 7.4) и одной из них присваивают символ 1, а другой – 0.
Затем эти вероятности складывают, результат записывают в промежутке между ближайшими вероятностями. Процесс объединения двух сообщений с наименьшими вероятностями продолжают до тех пор, пока суммарная вероятность двух оставшихся сообщений не станет равной единице. Код для каждого сообщения строится при записи двоичного числа справа налево путем обхода по линиям вверх направо, начиная с вероятности сообщения, для которого строится код.
Средняя длина кодового слова (табл. 7.4) L = 2,82, что несколько меньше, чем в коде Шеннона-Фано (L = 2,84). Кроме того, методика Шеннона-Фано не всегда приводит к однозначному построению кода. Ведь при разбиении на подгруппы можно сделать большей по вероятности как верхнюю, так и нижнюю подгруппы. От этого недостатка свободна методика Хаффмана. Она гарантирует однозначное построение кода с наименьшим для данного распределения вероятностей средним числом символов на букву. Однако, как следует из приведенных выше цифр, некоторая избыточность в кодовых комбинациях осталась. Из теоремы Шеннона следует, что эту избыточность также можно устранить, если перейти к кодированию достаточно большими блоками.
Рассмотрим процедуру эффективного кодирования двух сообщений X1 и X2 с вероятностями P(X1) = 0,9 и P(X2) = 0,1 по методу Хаффмана: отдельных сообщений; сообщений, составленных по два в группе; сообщений, составленных по три в группе. Сравним коды по эффективности L , по скорости передачи Rt и по избыточности R, если длительности кодовых символов одинаковы и равны  .
.
Таблица 7.4
Построение кода Хаффмана
| Xi | P(Xi) | Объединение сообщений | Код | ||||||||||
   
X1 | 0,35 | 0,35 | 0,35 | 0,35 | 0,35 | 0,35 | 0,37 | 0,63 | |||||
X2 | 0,15 | 0,15 | 0,15 | 0,17 | 0,20 | 0,28 | 0,35 | 0,37 | |||||
X 3
| 0,13 | 0,13 | 0,13 | 0,15 | 0,17 | 0,20 | 0,28 | ||||||

X4 | 0,09 | 0,09 | 0,11 | 0,13 | 0,15 | 0,17 | |||||||
X5
| 0,09 | 0,09 | 0,09 | 0,11 | 0,13 | ||||||||
X6 | 0,08 | 0,08 | 0,09 | 0,09 | |||||||||

X7 | 0,05 | 0,06 | 0,08 | ||||||||||
X8 | 0,04 | 0,05 | |||||||||||
| X9 |
 0,02 0,02
|
Энтропия источника в соответствии с (2.14)
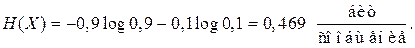 (7.8)
(7.8)
При кодировании отдельных сообщений методом Хаффмана сообщению X1 сопоставляется кодовый символ 1, а сообщению X2 – 0. Средняя длина кодового символа при этом:
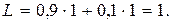 (7.9)
(7.9)
Скорость передачи:
 (7.10)
(7.10)
что составляет 46,9% от пропускной способности 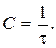 Избыточность кода равна избыточности источника сообщений:
Избыточность кода равна избыточности источника сообщений:
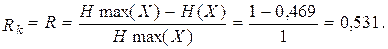
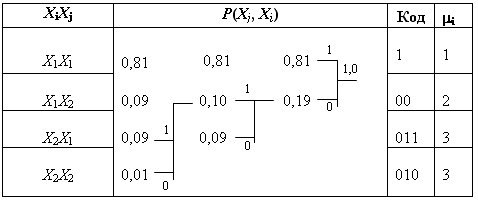
Для повышения эффективности кода перейдем к кодированию групп сообщений (табл. 7.5)
Средняя длина кодового слова, приходящего на одно сообщение:
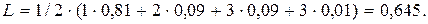 (7.11)
(7.11)
Скорость передачи при этом
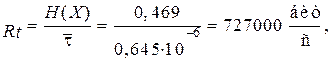 (7.12)
(7.12)
что составляет 72,7% от максимально возможной скорости передачи
(106 бит/с).
Чтобы найти избыточность кода, вычислим вероятность появления кодового символа 0 и 1:

Энтропия кода:
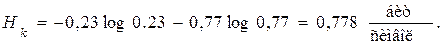
Избыточность:
Rk = 1 – Hk = 0,222.
Таблица 7.5
Кодирование сообщений, составленных по два в группе
А сейчас перейдем к кодированию групп сообщений, содержащих три сообщения в группе (табл. 7.6)
Таблица 7.6
Кодирование сообщений, составленных по три в группе
| XjXiXk | P(xixjxk) | Объединение сообщений | Код | |||||||||||||
| ||||||||||||||||

| 0,729 | 0,729 | 0,729 | 0,729 | 0,729 | 0,729 | 0,729 | |||||||||
 
X1X1X2
| 0,081 | 0,081 | 0,081 | 0,081 | 0,109 | 0,162 | 0,271 | |||||||||
|
1X2X1
| 0,081 | 0,081 | 0,081 | 0,081 | 0,081 | 0,109 | ||||||||||
|
| 0,081 | 0,081 | 0,081 | 0,081 | 0,081 | |||||||||||
   
X1X2X2
| 0,009 | 0,010 | 0,018 | 0,028 | ||||||||||||

| 0,009 | 0,009 | 0,010 | |||||||||||||
 
| 0,009 | 0,009 | ||||||||||||||
X2X2X2
| 0,001 |


Средняя длина кодового слова, приходящаяся на одно сообщение, в этом случае будет:
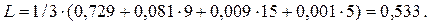
При этом скорость передачи:

что составляет 88% от пропускной способности.
Вероятность появления символов 0 и 1:

Найдем энтропию и избыточность кода в этом случае:

Сведем полученные результаты в табл. 7.7.
Таблица 7.7
Результаты, полученные при кодировании
| Вычисляемые величины | Число сообщений в группе | Предельные значения вычисляемой величины | ||
| L | 0,645 | 0,533 | H(X)/log2 = 0,469 | |
| Rt, бит/с | C =1/t = 10-6 | |||
| P(0) | 0,9 | 0,23 | 0,32 | P(0) = 0,5 |
| P(1) | 0,1 | 0,77 | 0,68 | P(1) = 0,5 |
| Rk, % | 53,1 | 23.2 | 9,6 | Rk = 0 |
Если кодировать группы по 4 и более сообщений, мы еще более приблизимся к предельным значениям вычисляемых величин.
Следует подчеркнуть, что увеличение эффективности кодирования при укрупнении блоков не связано с учетом все более далеких систематических связей, так как нами рассматривались алфавиты с некоррелированными знаками. Повышение эффективности определяется лишь тем, что набор вероятностей, получающихся при укрупнении блоков,можно делить на более близкие по суммарным вероятностям подгруппы.
Префиксные коды
Рассмотрев методики построения эффективных кодов, нетрудно убедиться в том, что эффект достигается благодаря присвоению более коротких кодовых комбинаций более вероятным сообщениям и более длинных менее вероятным сообщениям. Таким образом, эффект связан с различием в числе символов кодовых комбинаций. А это приводит к трудностям при декодировании. Конечно, для различения кодовых комбинаций можно ставить специальный разделительный символ, но при этом значительно снижается эффект, которого мы добивались, так как средняя длина кодовой комбинации по существу увеличивается на символ.
Более целесообразно обеспечить однозначное декодирование без введения дополнительных символов. Для этого эффективный код необходимо строить так, чтобы ни одна комбинация кода не совпадала с началом более длинной комбинации. Коды, удовлетворяющие этому условию, называют префиксными кодами. Последовательность 100000110110110100 комбинаций префиксного кода, например,
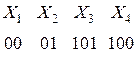
декодируется однозначно:

Последовательность 000101010101 комбинаций непрефиксного кода, например,
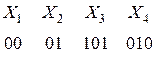
(комбинация 01 является началом комбинации 010), может быть декодирована по-разному:


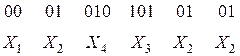
Нетрудно убедиться, что коды, получаемые в результате применения методики Шеннона-Фано или Хаффмана, являются префиксными.
Дата добавления: 2016-02-04; просмотров: 3785;