Диагностика Trypanosoma cruzi
Паразитическое простейшее Trypanosoma cruziвызывает болезнь Чагаса (южноамериканский трипаносомоз), уносящую ежегодно примерно 50 тыс. жизней. Паразит широко распространен в Латинской Америке. Он переносится клопами-хищниками (поцелуйный клоп), проникает в печень, селезенку, лимфатические узлы, центральную нервную систему и, размножаясь, разрушает клетки, в которых паразитирует. Для диагностики острой формы болезни Чагаса обычно проводят микроскопическое исследование свежей пробы периферической крови. Можно использовать и другой тест, более длительный, но выявляющий паразитов с большей вероятностью. Незараженных насекомых кормят кровью пациента и через 30 - 40 суток исследуют под микроскопом их кишечник на предмет наличия паразитов. Оба метода весьма трудоемки, дорогостоящи и требуют длительного времени. Болезнь можно диагностировать и иммунологическими методами, однако они часто дают ложноположительные результаты. В качестве альтернативы этим менее чем удовлетворительным процедурам было разработано несколько подходов, основанных на применении ДНК-ПЦР диагностики. В настоящее время ПЦР-диагностика болезни Чагаса служит дополнением к традиционным, широко используемым методам.
Один из ДНК-ПЦР-тестов основан на выявлении фрагмента ДНК длиной 188 п. н., который присутствует во множестве копий в геноме Т. cruzi, но отсутствует в геномной ДНК нескольких родственных паразитов. После амплификации этот фрагмент без труда обнаруживается с помощью электрофореза в полиакриламидном геле.
Данную методику можно использовать для обнаружения широкого спектра бактерий, вирусов и паразитов.
Лекция №16
1.Геномика, протеомика и биоинформатика. Медицинская биотехнология в “постгеномную эру”
На рубеже ХХ-века возникли три новые науки, которые определяют передовой край развития биотехнологии и сулят человечеству большие перспективы в лечении болезней и создании новых лекарственных препаратов - геномика, протеомика и биоинформатика. Этот новый этап развития биотехнологии получил в научной литературе неофициальное название “биотехнология постгеномной эры”
Начнем с геномики, поскольку она хронологически возникла ранее двух других, остановимся на различиях между ней и генетикой, так как иногда их путают. Классическая генетика - наука о наследственности и изменчивости живых систем; а геномика - это наука,занимающаяся установлением структуры и выяснением механизма функционирования генов в живых системах (геном – совокупность всех генов организма).
Геномика возникла около 20 лет назад вместе с проектом "Геном человека". Работа над реализацией программы «Геном человека» (HGP, Human Genome Project) официально началась 1 октября 1990 г. в США и контролировалась Министерством энергетики (Department of Energy) совместно с Государственным институтом здоровья (National Institutes of Health) США. Ее конечная цель состояла в определении нуклеотидной последовательности всего генома человека с точностью до 0,01процента. Полученная обширная генетическая информация должна была стать основой для более узких проектов исследования всех моногенных генетических заболеваний и послужить трамплином для изучения сложных наследственных патологий. В 1990 г. предполагалось, что работа в рамках HGP займет 15 лет, а ее стоимость составит 2 млрд. долл. HGP представляла собой обширную программу, охватывающую множество различных направлений. За короткое время программа стала международной, ее проекты финансировались правительствами Великобритании, Франции, Канады, Германии и Японии, а в выполнении тех или иных разделов и этапов участвовали различные государственные и межгосударственные агентства, частные компании и некоммерческие исследовательские институты. По данным на конец 2002 г., общие расходы на программу превысили 3 млрд. долларов.
Первая (черновая) версия последовательности нуклеотидов была закончена в 2000 г. Конечная версия, которая больше не будет совершенствоваться (названная «Build 35»), - закончена в 2004 г. На основании полученных результатов было установлено, что число генов у человека составляет 20.000-25.000, что немного меньше, чем предсказывалось раньше (от 30.000 до 40.000 генов). Последняя версия последовательности содержит 2,85 млрд. пар нуклеотидов с 341 брешью, т.е. в этих местах по каким-то причинам секвентировать геномную ДНК не удалось. Аккуратность секвенса в конечной версии - 1 ошибка на 100 тыс. позиций подряд. Еще точнее секвентировать весь геном уже никто не будет. Наиболее значимое научное достижение последних лет - это картирование генома человека, в результате чего созданы атлас последовательности нуклеотидов геномной ДНК человека (референтная последовательность) и базы данных
- о последовательности нуклеотидов транскрибируемых участков ДНК (EST Database, EST - Expressed Sequence Tags);
- о положении и содержании отличий (полиморфизмов, т.е. нуклеотидных замен) других известных последовательностей ДНК человека от референтной последовательности (SNP database, SNP - Single Nucleotide Polymorphism).
Отдельный ген занимает конкретное место (локус) в цепочке ДНК в хромосоме и всегда находится в хромосомах определенного типа. Гены представляют индивидуальные коды для формирования белков в организме. Первоначальная теория о том, что один ген отвечает за синтез одного белка, была признана неверной. Один ген может отвечать за синтез ряда белков или через альтернативный сплайсинг, или через посттрансляционные модификации.
Та часть программы «Геном человека», которая выполнялась в США, включала следующие подпрограммы: построение генетических и физических карт с высоким разрешением; снижение себестоимости и повышение эффективности имеющихся технологий секвенирования ДНК (определения нуклеотидной последовательности); разработка новых технологий картирования генов и секвенирования ДНК; усовершенствование компьютерных технологий для обработки и хранения больших массивов данных; изучение этического, правового и социального аспектов исследований, проводимых в рамках программы. Цель последней подпрограммы состоит в создании руководств для исследователей и врачей и обосновании политики правительства, касающейся использования генетической информации.
В рамках подпрограммы «Новые технологии» консорциумом нескольких групп исследователей был так же полностью секвенирован геном дрожжей Saccharomyces cerevisiae(150 м. п. н.). Кроме того, определены полные нуклеотидные последовательности ДНК других «модельных» организмов, таких как нематоды (Caenorhabditis elegans, 100 м. п. н.), плодовая мушка (Drosophila melanogaster, 120 м. п. н.), бактерии (Е.coli, 4,2 т. п. н.), мышь (Mus musculus, 3000 м. п. н.) и др.
В настоящее время в лабораториях разных стран продолжаются обширные исследования в рамках второго этапа проекта “Геном человека”. Основное внимание при этом уделяется выяснению функций тех или иных обнаруженных генов. Особое внимание будет удаляться потенциальным проонкогенам (генам, продукты которых способствуют злокачественной трансформации клеток), а также генам, которые участвуют в развитии генетически детерминированных заболеваний.
В ходе этого этапа предстоит картографировать и проанализировать все гены человека, в том числе изучить все разновидности одного и того же гена, что, по мнению ученых, необходимо для выявления индивидуальной восприимчивости человека к той или иной болезни. Для выделения функции определенных генов ученые используют разработанный несколько лет назад метод РНК-интерференции. В культуры клеток человека будут вводиться фрагменты РНК, комплементарные продуктам транскрипции исследуемого гена (антисмысловые нуклеотиды) – таким образом, он окажется как бы “выключен” из процесса синтеза белков. Анализ изменений, к которым проведет подобное воздействие, позволит идентифицировать продукт гена.
Другим направлением исследований является разработка более совершенных, быстрых и дешевых методов прочтения и расшифровки генома человека. К 2010-2015 г. планируется снизить стоимость этой процедуры до 1000 долларов.
В рамках фундаментальных исследований по проекту «Геном человека» сформировалось несколько новых научных направлений, использующих основные достижения геномики для решения различных прикладных задач. Это сравнительная геномика, которая позволяет, например, по известным функциям генов мухи или червя нематоды предсказывать функции генов человека. А выявленные у человека гены, работа которых нарушена при тех или иных заболеваниях, могут быть изучены на других животных. Например, у человека найдены гены, мутации в которых приводят к болезни Альцгеймера - одной из форм старческого слабоумия. Оказалось, что изучать действие этих генов и искать способы лечения можно в экспериментах на мухах. Мутации в генах мухи приводят к изменениям в мушиных мозгах, очень сходным с молекулярными нарушениями, происходящими в мозгах пациентов с болезнью Альцгеймера. У слабоумных мух нарушается способность к запоминанию. Ведется поиск генов у мух, связанных с нарушениями памяти, и препаратов, способных замедлить развитие болезни - сначала у мух, а потом, надо надеяться, и у людей.
На стыке геномики и фармакологии появились фармакогеномика – наукаоб особенностях генома человека, с которыми связаны метаболизм и действие лекарственных препаратов, и хемогеномика -исследующая комплексный геномный ответ биологической системы на действие химического вещества. Обе наукипредлагают решения ключевой для всей медицины проблемы - неопределенности относительно того, какие точки приложения действия фармакотерапевтических средств обладают наибольшей клинической значимостью, являющиеся основой преодоления лекарственной резистентности и индивидуальной фармакотерапии.
Это позволит не только тестировать человека на склонность к той или иной болезни, но и при необходимости подбирать максимально подходящее к его генотипу лекарство, т. е. лекарство со стопроцентной эффективностью при полном отсутствии побочных эффектов. Конечно, это не значит, что фармацевтические фирмы будут создавать препарат для каждого отдельно взятого индивида. Нет. Просто лекарства будут разрабатываться для групп людей с одинаковыми «генетическими портретами». По крайней мере, касательно чувствительности к разрабатываемому лекарственному средству. По оптимистическим прогнозам доктора Коллинза, руководителя проекта «Геном человека», появление индивидуализированных лекарств не за горами — в 2020 году все лекарственные средства будут разрабатываться с использованием фармакогеномики.
Важные для медицины и промышленности результаты дали исследования целых геномов бактерий. Уже полностью прочитаны геномы нескольким десятков бактерий. Среди них, кроме уже упоминавшейся кишечной палочки, возбудители социально значимых инфекций - туберкулеза, сифилиса, возбудители тифа, гастрита, некоторые промышленно важные бактерии. Практически все гены в изученных бактериальных геномах выявлены, для многих известны функции белкового продукта. По известным функциям белков проводят реконструкцию обмена веществ - метаболических путей бактерий. Реконструкция основных метаболических процессов организма по последовательности нуклеотидов его генома - одна из важнейших задач геномных исследований. Эту область исследований назвали труднопроизносимым словом метаболомика.Предполагается, что полученные результаты прежде всего позволят эффективно создавать новые высокопроизводительные штаммы промышленно важных микроорганизмов с использованием метода направленного мутагенеза и более эффективно проводить поиск биомишеней для лекарственных препаратов.
Переходя ко второй науке – протеомике, которая занимается изучением совокупности белков и их взаимодействий в живых организмах (протеом – совокупность всех белков организма) - следует сказать, что она совсем молода (сам термин был впервые использован в печати в 1993г) и достижений у нее пока не очень много. Протеомика возникла из понимания того простого факта, что, для эффективного лечения недостаточно просто расшифровать геном или обнаружить конкретный ген, ответственный за патологию. Чтобы знания о генах работали, нужно понять не только их последовательность, но и то, как они работают. А их работа заключается в том, чтобы командовать производством и деятельностью белков, или, по-английски, протеинов. Поэтому, чтобы произвести переворот в медицинской диагностике и терапии, нужны знания о структуре и функциях всех белков, причем как нормальных, так и патологически измененных, а так же об их соотношении.
Объем информации, который в связи с этим предстоит обработать, не имеет аналогов в истории и, на несколько порядков по сложности и объему превышает проект “Геном человека”. Ведь число протеинов в человеческом теле достигает сотен тысяч, а это в десятки раз больше, чем количество генов (около 40 тысяч). Кроме того, набор генов в любой клетке один и тот же, набор белков для каждой клетки индивидуален. Причем разница в содержании различных белков огромна, она достигает девяти порядков — от 1 до 1 миллиарда белков на клетку.
В отличие от генома протеом меняется в соответствии с состоянием клетки - реагирует на все внешние воздействия. При этом может происходить изменение соотношения между белками, исчезновение одних и появление других (новых) белков, изменение в пространственной структуре белковых молекул, приводящее к появлению инвариантов этих белков. Все эти данные необходимо учитывать и рассматривать их в совокупности.
Предложение нарисовать белковый атлас человека прозвучало еще в 1982 году. Оно исходило от известного американского биолога Лейфа Андерсона. Но в начале 1980-х попытки тотального изучения белков казались просто далекой фантастикой, и проект не получил финансирования. Лишь после расшифровки генома протеомика обрела второе дыхание.
В 2001 году международным консорциумом ученых, политиков и бизнесменов была создана организация HUPO (Human Proteom Organization). В ее задачи входит изучение человеческих белков, что позволит со временем нарисовать белковый атлас человека. Но это лишь одна из возможных задач.
Изучение структуры и функций белка позволит диагностировать и предотвращать наследственные заболевания, создавать лекарства нового поколения, а со временем и бороться с неизлечимыми заболеваниями. Проект HUPO еще только складывается и в отличие от предыдущего — HUGO (Human Genome Organization) — не имеет четко обозначенных сроков. Но уже очевидно, что крупные открытия в области протеомики ожидают ученых в самое ближайшее время.
Учитывая предстоящий объем работ и с целью скорейшего получения практических результатов, изначально, в протеомике был взят медицинский уклон: в первую очередь стали изучать те белки, которые важны для понимания механизма заболевания и его диагностики.
В настоящее время для протеомных исследований разработан набор стандартных процедур с использованием самых современных инструментальных методов.
Чтобы получить сведения о протеоме, необходимо сначала его выделить и очистить от других молекул. Поскольку число белков во всем протеоме (т.е. во всем организме) весьма велико, обычно берут только часть организма (его орган или ткань) и различными методами выделяют белковую компоненту (подготовительный этап).
На следующем этапе осуществляется двумерный электрофорез экстрактов нормальной ткани и если необходимо одновременно патологически измененной, например из опухолевых клеток. При этом в одном направлении разделяются молекулы белков, имеющие разную массу, в другом – различный суммарный
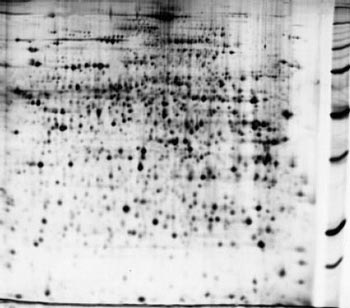
Рис. 1. Пример двумерной электрофореграммы белков из экстракта печени мыши
электрический заряд. В результате этой тончайшей процедуры на специальном носителе одинаковые молекулы группируются, образуя макроскопические пятна различного размера, причем в каждом пятне содержатся только одинаковые молекулы. Число пятен, т.е. число разных белков или пептидов, может составлять многие тысячи (до 10 тыс.), и для их исследования используются автоматические устройства для обработки и анализа. После того как устанавливается, количество каких белков в патологически измененной ткани уменьшилось или увеличилось, эти белки идентифицируются. Во-первых, это важно для установления диагноза, а во-вторых, именно идентифицированные белки могут быть молекулярными мишенями для новых лекарств. Идентификация выполняется с помощью масс-спектрометрии: определяется молекулярная масса этих молекул и, если это необходимо, обычно в случае появления новых неизвестных белков, их секвенируют (определяют аминокислотную последовательность). Для наиболее значимых белков с помощью методов рентгеноструктурного анализа или ЯМР-спектроскопии проводят определение трехмерной структуры.
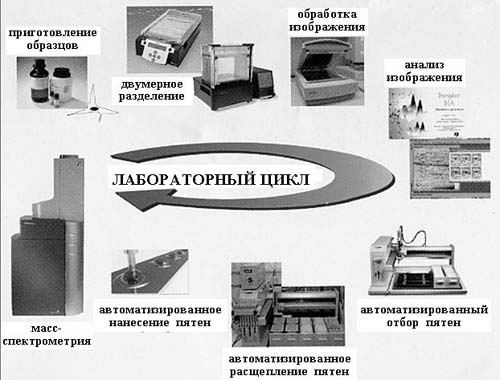
Рис. 2. Инструменты протеомики
В настоящее время, как за рубежом, так и в России проводятся исследования по использованию протеомики для диагностики гепатитов, построении протеомных карт сыворотки крови и амниотической жидкости для диагностики патологии беременности. Перспективны протеомика "молчащих онкологических заболеваний", построение протеомных карт для промышленно используемых микроорганизмов, различных штаммов М.tuberculosis с целью создания новых лекарств и трансгенных растений медицинского назначения. И, наконец, протеомные исследования играют важнейшую роль в нахождении мишеней для действия лекарственных препаратов, о чем мы более подробно поговорим позднее.
Существование огромного количества разнообразных белков привело к необходимости создания информационных массивов – баз (или банков) данных, в которые заносились бы все известные о них сведения. В настоящее время существует множество общих и специализированных баз данных, которые доступны в Интернете каждому желающему. В общих базах содержатся сведения о всех известных белках живых организмов, т.е. о глобальном протеоме всего живого. Примером такой базы является SwissProt-TrEMBL (Швейцария–Германия), в которой на сегодняшний день содержатся структуры почти 200 000 белков, установленные аналитическими методами, и еще почти 2 млн. структур, которые определены в результате трансляции с нуклеотидных последовательностей.
Помимо банков данных аминокислотных последовательностей, таких как, например упомянутый выше SwissProt или PIR, существуют банки данных по трехмерной структуре макромолекул (PDB). Есть банки, содержащие информацию о функционально значимых участках белков (PROSITE), по доменам белков (Prodom), по лиганд-рецепторным комплексам белков (RELIBASE), по движению белковых субъединиц, петель и доменов (ProteinMotionDatabase), по лиганд-рецепторным комплексам и ионам металлов в активных центрах белков (PROMISE).
Однако, успехи геномики и протеомики не решают всех проблем, стоящих перед учеными. На повестке дня стоят еще более грандиозные задачи. Возможно, что в недалеком будущем предметом их внимания окажется состав и количественное соотношение (на данный момент ростового цикла клетки или органа) всех низкомолекулярных метаболитов – продуктов ферментативных реакций. Для этой науки уже придумано название метаболомика. Учитывая, что процессы химиотерапии очень часто базируются на препаратах, являющихся аналогами ферментных субстратов, от таких исследований можно также ожидать принципиального вклада в химиотерапию будущего.
Определение терминов «метаболомика» и других «-омиков» не являются строгими в научном смысле. Слово «метаболомик» впервые было опубликовано в книге «Effect of Slow Growth on Metabolism of Escherichia coli, as Revealed by Global Metabolite Pool (metabolom) Analysis» в 1998 г. Метаболом описывает совокупность метаболических процессов в каждой клетке, ткани, организме или биологической жидкости; следовательно, метаболомика является системой технологий, направленных на объяснение и изучение метаболомов. Подобно геномам и протеомам, существуют различные метаболомы, содержащиеся как в клетках одноклеточных организмов, так и клетках тканей многоклеточных организмов. Также существуют метаболомы и в биологических жидкостях - моче, спинномозговой жидкости и плазме. В биологических жидкостях человека и животных можно обнаружить различные метаболиты при нормальных метаболических процессах и при воздействии ксенобиотиков на организм.
Начиная с 2002 г., активно развивается метабономика - новая технология количественного измерения динамического мультипараметрического метаболического ответа живых систем при патофизиологических или генетических изменениях. Изучение динамического и зависимого от времени профиля метаболитов in vivo уже сегодня приносит полезную информацию. Токсические эффекты, генетические и соматические заболевания могут проявляться нарушением синтеза некоторых белков. Однако, в конечном счете, происходит изменение управления биохимическими процессами, что отражается на соотношении концентраций многих простых по строению эндогенных веществ-метаболитов в потоках биологических жидкостей. Нарушение динамического равновесия в биологических жидкостях организма, вызванное заболеванием или интоксикацией, изменяет их качественный и (или) количественный состав. Для установления факта происходящих изменений необходимо одновременно определить множество метаболитов в широком диапазоне концентраций в плазме крови, моче или желчи. При этом используют образцы как после типовой пробоподготовки, так и без предварительного выделения. Для метаболомных исследований используют самые современные инструментальные методы анализа, такие как жидкостная хроматография, спектроскопия ЯМР, масс-спектрометрия.
Третья наука – биоинформатика, занимающаяся изучением биологической информации с помощью математических, статистических и компьютерных методов – возникла на стыке целого ряда наук. По сути дела биоинформатика - это анализ биологических текстов (генов) с построением соответствующих структур макромолекул, предсказанием их функции и создание новых лекарственных препаратов. Иное определение биоинформатики - это путь от генов к лекарствам через структуру макромолекул, то есть биоинформатика позволяет сделать в компьютере (in silico) все то, что раньше делали в эксперименте.
Таким образом, биоинформатика - это область науки, которая занимается примерно тем, чем занимались классическая биохимия, молекулярная биология и биотехнология, но не в пробирке, а с помощью вычислительной, компьютерной техники. Это, так называемая, "сухая" биохимия. Биоинформатика - это путь от гена к лекарству через соответствующую структуру белковой макромолекулы. Все, что раньше исследователи делали с помощью, различных экспериментальных методов, включая ЯМР, рентгеноструктурный анализ, сейчас можно сделать с помощью вычислений. Если известна структура генома, его можно разметить и найти границы гена не при помощи генной инженерии (клонирования отдельных генов), а с помощью определенных компьютерных программ. Далее из нуклеотидной последовательности гена необходимо транслировать аминокислотную последовательность интересующего белка. Потом следует ее сравнение с библиотекой уже известных последовательностей и определяется, существует ли аналогичный или близкий по структуре белок. Если да, то мы можем предсказать с различной степенью точности и структуру, и функцию этого белка, а так как библиотеки структур постоянно растут, то возрастают шансы на успех. Базы данных этих библиотек используются для сравнительного моделирования трехмерной структуры белков. Для предсказания некоторых участков белка расчетное построение уже сейчас достигает разрешения электронного микроскопа. После этого на основании пространственных моделей можно сконструировать определенные лекарства, оптимизированные под структуру изучаемого белка (молекулярный дизайн лекарств, докинг).
Так, например в 1999 г. в США профессор Айзенберг, проанализировав 20 полных геномов микроорганизмов, нашел среди 6 тыс. белков дрожжей более 98 тыс. функционально связанных пар белков и предсказал функцию 2,5 тыс. белков. Сколько понадобилось бы времени и средств обычной биохимии, чтобы сделать такую работу ели учесть, что не так давно биохимики тратили всю жизнь, чтобы определить структуру одного белка и выявить его функцию и даже получали за это Нобелевские премии?
Не все фармакологи принимают биоинформатику восторженно, но эта наука бурно развивается за рубежом, и несмотря ни на что и у нас в России.
В настоящее время не вызывает сомнений, что все болезни - от гена: одни - следствие его дефекта (наследственные заболевания), другие - следствие нарушения регуляции его функции (нарушение экспрессии нормального гена). Известно, что наследственные заболевания дают лишь 2 проц. всех заболеваний, а, нарушение регуляции - причина ненаследственных болезней, которые составляют 98 проц. Если говорить о наследственных заболеваниях, то здесь перспективна генная терапия, остальные болезни требуют создания новых, более эффективных и безопасных лекарств.
В настоящее же время протеомика, вместе с геномикой и биоинформатикой, ориентирована, прежде всего, на создание новых лекарственных препаратов (рис. 3), для которых молекулярными мишенями будут служить те или иные белки. Процесс нахождения новых мишеней для действия лекарств решается с помощью биоинформатики, причем объектом анализа является геном. Однако после анализа генома необходимо получить доказательства того, что данный белок интенсивно экспрессируется и находится в клетке в рабочем состоянии. Эту задачу решает протеомика. Таким образом, выявляется молекулярная генетическая мишень для лекарства.
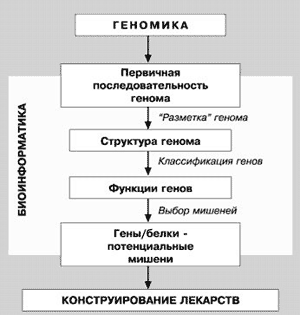
Рис. 3. Взаимосвязь геномики, протеомики и биоинформатики при решении проблемы конструирования новых лекарственных средств
Именно союз геномики, протеомики и биоинформатики дает новое понимание молекулярных механизмов заболеваний, новые подходы к созданию лекарств и диагностических тестов.
Л Е К Ц И Я № 17
Дата добавления: 2016-01-30; просмотров: 1228;