Существует огромное количество разновидностей баз данных, отличающихся по различным критериям
Классификация БД по модели данных:
Примеры:
§ иерархические,
§ сетевые,
§ реляционные,
§ объектные,
§ объектно-ориентированные,
§ объектно-реляционные.
Классификация БД по среде физического хранения:
§ БД во вторичной памяти (традиционные): средой постоянного хранения является периферийная энергонезависимая память (вторичная память) — как правило жёсткий диск. В оперативную память СУБД помещает лишь кеш и данные для текущей обработки.
§ БД в оперативной памяти (in-memory databases): все данные находятся в оперативной памяти.
§ БД в третичной памяти (tertiary databases): средой постоянного хранения является отсоединяемое от сервера устройство массового хранения (третичная память), как правило на основе магнитных лент или оптических дисков. Во вторичной памяти сервера хранится лишь каталог данных третичной памяти, файловый кеш и данные для текущей обработки; загрузка же самих данных требует специальной процедуры.
Классификация БД по содержимому:
Примеры:
§ географические;
§ исторические;
§ научные;
§ мультимедийные.
Классификация БД по степени распределённости:
§ централизованные (сосредоточенные);
§ распределённые.
Отдельное место в теории и практике занимают пространственные (англ. spatial), временные, или темпоральные (temporal) и пространственно-временные (spatial-temporal) БД.
Итак, простейшая схема работы с базой данных выглядит примерно так

По характеру использования СУБД делят на однопользовательские (предназначенные для создания и использования БД на персональном компьютере) и многопользовательские (предназначенные для работы с единой БД нескольких компьютеров, объединенных в локальные сети). Вообще деление по характеру использования можно представить следующей схемой:
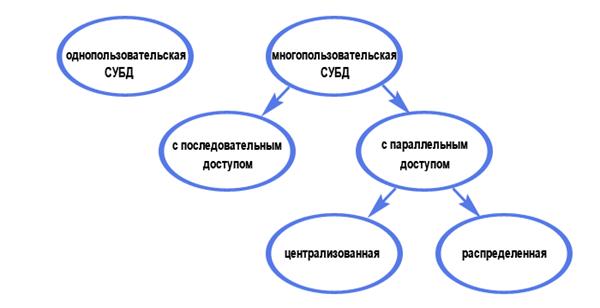
Не вдаваясь далее в подробности, отметим, что на сегодняшний день число используемых СУБД исчисляется десятками. Наиболее известные однопользовательские СУБД - Microsoft Visual FoxPro и Access, многопользовательские - MS SQL Server, Oracle и MySQL.
При размещении БД на ПК, который не находится в сети, БД всегда используется в монопольном режиме. Даже если БД используют несколько пользователей, они могут работать с БД только последовательно. Однако работа на изолированном ПК с небольшой БД в настоящий момент становится уже не характерной для большинства приложений. БД отражает информационную модель реальной ПО, она растет по объему => резко увеличивается количество задач, решаемых с помощью этой БД и в соответствии с этим увеличивается количество приложений, работающих с единой БД. ПК объединяются в локальные сети и необходимость распределения приложений, работающих с единой БД по сети, является несомненной.
Параллельный доступ к одной БД нескольких пользователей, в том случае, если БД расположена на одной машине, соответствует режиму распределенного доступа к центральной БД. Такие системы называются системами распределенной обработки данных.
Если же БД расположена на нескольких ПК, распределенных в сети, и к ней возможен параллельный доступ нескольких пользователей, то мы имеем дело с параллельным доступом к распределенным БД. Такие системы называются системами распределенных (удаленных) баз данных.
Режимы работы с базой данных.


Терминология УБД.
Пользователь БД - это программа или человек, обращающиеся к БД на языке манипулирования данными.
Запрос - это процесс обращения пользователя к БД с целью ввода, получения или изменения информации в БД.
Транзакция - это последовательность операций модификации данных в БД, переводящая БД из одного непротиворечивого состояния в другое непротиворечивое состояние.
Логическая структура БД - это определение БД на физически независимом уровне, ближе всего соответствующем концептуальной модели БД.
Топология БД (структура РБД) - это схема распределения физических БД по сети.
Локальная автономность означает принадлежность локальному владельцу информации локальной БД и связанных с ней определенных данных.
Удаленный запрос - это запрос, который выполняется с использованием модемной связи.
Возможность реализации удаленной транзакции - это обработка одной транзакции, состоящей из множества SQL-запросов, на одном удаленном узле.
Поддержка распределенной транзакции допускает обработку транзакции, состоящей из нескольких SQL-запросов, которые выполняются на нескольких узлах сети (удаленных или локальных), но каждый запрос в этом случае обрабатывается только на одном узле, т.е. запросы не являются распределенными. При обработке одной распределенной транзакции разные локальные запросы могут обрабатываться в разных узлах сети.
1.3. Модель "клиент-сервер"
Модель "клиент-сервер" связана с принципом открытых систем. Термин "клиент-сервер" исходно применялся в архитектуре ПО, которое ориентировало распределение процесса выполнения по принципу взаимодействия 2-х программ, процессов, один из которых в этой модели назывался клиентом, а другой - сервером. При этом предполагалось, что один серверный процесс может обслуживать множество клиентских процессов.
Ранее приложение (пользовательская программа) не разделялось на части, а выполнялось монолитным блоком, но при рациональном использовании ресурсов сети данный принцип не актуален. Теперь все ПК в сети обладают собственными ресурсами и разумно так распределить нагрузку на них, чтобы максимальным образом использовать их ресурсы. Основной принцип технологии "клиент-сервер" в БД заключается в разделении функций стандартного интерактивного приложения на 5 групп:
1. Функция ввода и отображения данных (PL);
2. Прикладные функции, определяющие основные алгоритмы решения задач приложения (BL);
3. Функции обработки данных внутри приложения (DL);
4. Функции управления информационными ресурсами (DML);
5. Служебные функции, играющие роль связок между функциями 1-х и 4-х групп.
Структура типичного приложения, работающего с БД.
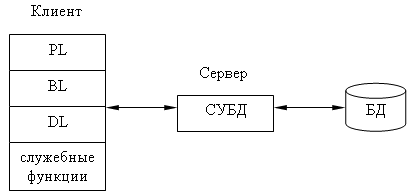
PL - это часть приложения, которая определяется тем, что пользователь видит на экране, когда работает приложение (интерактивные экранные формы, а также все то, что выводится пользователю на экран, результаты решения некоторых промежуточных задач, справочная информация).
Основные задачи PL:
- формирование экранных изображений;
- чтение и запись в экранные формы информации;
- управление экраном;
- обработка движений мыши и нажатий клавиш клавиатуры.
BL - это часть кода приложения, которая определяет алгоритмы решения конкретных задач приложения. Обычно этот код пишется с использованием различных языков программирования.
DL - это часть кода приложения, которая связана с обработкой данных внутри приложения (данными управляет собственно СУБД), где используется язык запросов и средства манипулирования данными стандартного языка SQL.
Процессор управления данными (Data Base Manager System Processing) - это собственно СУБД, которая обеспечивает управление и хранение данных. В идеале СУБД должна быть скрыта от BL-приложения. Однако для рассмотрения архитектуры приложения нам надо их выделить в отдельную часть приложения.
1.4. Двухуровневые модели.
Эти модели фактически являются распределением пяти указанных функций между двумя процессами, которые выполняются на двух платформах - клиенте и сервере.
Модель удаленного управления данными (модель файлового сервера).
В этой модели BL и PL располагаются на клиенте. На сервере располагаются файлы с данными и доступ к ним. Функции управления информационными ресурсами в этой модели находятся на клиенте.
Модель файл-сервера.
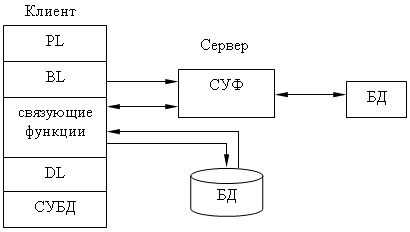
В этой модели файлы БД хранятся на сервере, клиент обращается к серверу с файловыми командами, а механизм управления всеми информационными ресурсами (база метаданных (БМД)) находится на клиенте.
Достоинства:
- разделение монопольного приложения на два взаимодействующих процесса.
- сервер может обслуживать множество клиентов, которые обращаются к нему с запросами.
Алгоритм выполнения запроса клиента.
Запрос клиента формируется в командах ЯМД. СУБД переводит этот запрос в последовательность файловых команд. Каждая файловая команда вызывает перекачку блока информации на клиента. Далее на клиенте СУБД анализирует полученную информацию и если в полученном блоке не содержится ответ на запрос, то принимается решение о перекачке следующего блока информации до тех пор, пока не будет найдено ответа на запрос.
Модель удаленного доступа к данным.
В модели удаленного доступа (RDA) база данных хранится на сервере. На нем же находится и ядро СУБД. На клиенте располагаются PL и BL приложения. Клиент обращается к серверу с запросами на языке SQL.
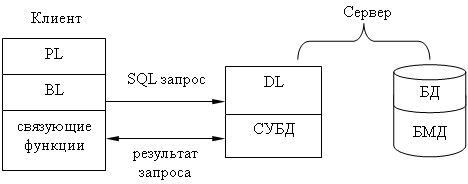
Достоинства:
- перенос компонента представления и прикладного компонента на клиентский ПК существенно разгружает сервер БД, сводя к минимуму общее число процессов в ОС.
- процессор сервера целиком загружается операциями обработки данных, запросов и транзакций.
- резко уменьшается загрузка сети, запросы на ввод-вывод и на SQL уменьшаются в объеме, т.е. в ответ на запросы клиент получает только данные, удовлетворяющие данному запросу.
- унификация интерфейса клиент-сервер.
- стандартным при обращении приложения клиента и сервера становится язык SQL.
Недостатки:
- запросы на SQL при интерактивной работе клиента могут существенно загрузить сеть.
- на клиенте располагаются PL и BL, и если при повторении аналогичных функций в различных приложениях (других клиентов) их код должен быть повторен для каждого клиентского приложения, следовательно, дублирование кода приложения.
- сервер в этой модели играет пассивную роль, поэтому функции управления информационными ресурсами должны выполняться на клиенте => это усложняет клиентское приложение.
Модель сервера баз данных.
Для того, чтобы избавиться от недостатков модели удаленного доступа должны быть соблюдены следующие условия:
1. Данные, которые хранятся в БД в каждый момент времени должны быть непротиворечивы.
2. БД должна отображать некоторые правила ПО, законы ПО.
3. Необходим постоянный контроль за состоянием БД, отслеживание всех изменений и адекватная реакция на них.
4. Возникновение некоторой ситуации в БД четко и оперативно должно влиять на ход выполнения прикладной задачи.
5. Одной из важных проблем СУБД является контроль типов данных через язык описания данных (ЯОД).
Модель активного сервера.
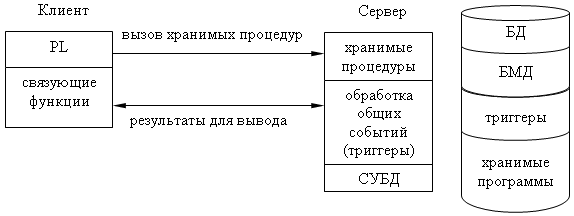
Данную модель поддерживают большинство современных СУБД: Informix, Ingres, Sybase, Oracle, MS SQL Server.
Основу данной модели составляет механизм хранимых процедур (как средства программирования SQL-сервера), механизм триггеров (как механизм отслеживания текущего состояния информационного хранилища) и механизм ограничений на пользовательские типы данных (который иногда называется механизмом поддержки доменной структуры).
В этой модели бизнес логика разделена между клиентом и сервером. На сервере бизнес логика реализована в виде хранимых процедур - специальных программных модулей, которые хранятся в БД и управляются непосредственно СУБД. Клиентское приложение обращается к серверу с командой запуска хранимой процедурой, а сервер выполняет эту процедуру и регистрирует все изменения в БД, которые в ней предусмотрены. Сервер возвращает клиенту данные, релевантные его запросу.
Трафик обмена информацией между клиентом и сервером резко уменьшается.
Централизованный контроль в данной модели выполняется с использованием механизма триггеров, которые являются частью БД.
Триггер - механизм отслеживания специальных событий, которые связаны с состоянием БД. Триггер в БД является как бы некоторым тумблером, который срабатывает при возникновении определенного события в БД. Ядро СУБД проводит мониторинг всех событий, которые вызывают созданные и описанные триггеры в БД, и при возникновении соответствующего события сервер запускает соответствующий триггер => триггер - это программа, которая выполняется над БД и вызывает хранимые процедуры.
Данная модель сервера является активной, потому что не только клиент, но и сам сервер используют механизм триггеров.
Достоинства:
- Хранимые процедуры и триггеры хранятся в словаре БД и могут быть использованы несколькими клиентами => уменьшается дублирование алгоритмов обработки данных в разных клиентских приложениях.
Недостатки:
- Очень большая загрузка сервера.
Функции сервера:
1. Осуществляет мониторинг событий, связанных с описанными триггерами;
2. Обеспечивает автоматическое срабатывание триггеров при возникновении связанных с ними событий;
3. Обеспечивает исполнение внутренней программы каждого триггера;
4. Запускает хранимые процедуры по запросам пользователей;
5. Запускает хранимые процедуры из триггеров;
6. Возвращает требуемые данные клиенту;
7. Обеспечивает все функции СУБД: доступ к данным, контроль и поддержка целостности данных в БД, контроль доступа, обеспечение корректной работы всех пользователей с единой БД.
Для разгрузки сервера была предложена 3-уровневая модель сервера:
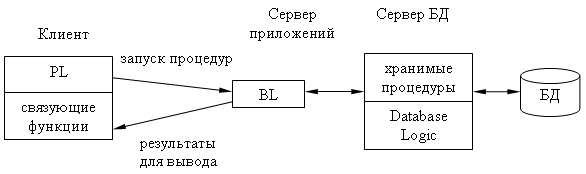
Эта модель является расширением двухуровневой модели, т.е. вводится дополнительный промежуточный уровень между клиентом и сервером. В этой модели компоненты приложения делятся между тремя исполнителями:
1. Клиент - обеспечивает логику представления, включая графический пользовательский интерфейс, локальные редакторы.
2. Серверы приложений - составляют новый, промежуточный уровень архитектуры.
3. Они спроектированы как исполнение общих не загружаемых функций для клиентов, поддерживают функции клиентов, поддерживают сетевую доменную операционную среду, хранят и исполняют общие правила бизнес логики, поддерживают каталоги с данными, обеспечивают обмен сообщениями и поддержку запросов.
4. Серверы этой модели занимаются исключительно функциями СУБД, функции создания резервных копий БД и восстановления БД после сбоев, управление выполнением транзакций и поддержки устаревших (унаследованных) приложений.
Достоинства:
- Обладает большей гибкостью, чем двухуровневая модель.
1.5. Модели серверов баз данных.
Недостатки:
- для обслуживания большого числа клиентов на сервере должно быть запущено большое количество одновременно работающих серверных процессов, а это резко повышает требование к ресурсам ЭВМ, на котором запускались все серверные процессы.
- каждый серверный процесс в этой модели запускается как независимый, поэтому если один клиент сформировал запрос, который был выполнен другим серверным процессом для другого клиента, то запрос, тем не менее, выполняется повторно.
- в этой модели сложно обеспечить взаимодействие серверных процессов.
Взаимодействие серверных и клиентских процессов в модели 1:1.
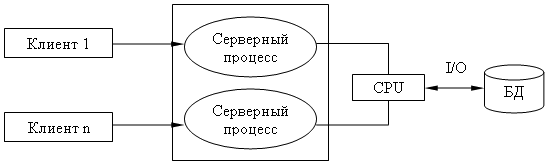
Вышеперечисленные недостатки устраняются в модели (архитектуре) "систем с выделенным сервером", который способен обрабатывать запросы от многих клиентов. Сервер единственный обладает монополией на управление данными и взаимодействует одновременно со многими клиентами. Логически каждый клиент связан с сервером отдельной нитью (tread), или потоком, по которому пересылаются запросы.
Такая архитектура получила название многопотоковой односерверной.
Достоинства:
- уменьшается нагрузка на ОС, возникающая при работе большого числа пользователей.
Многопотоковая односерверная архитектура.
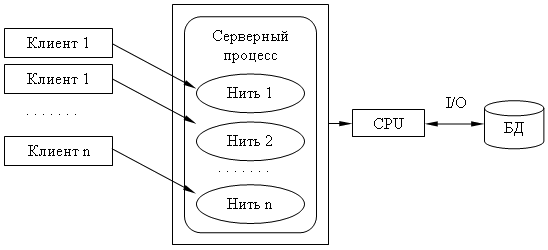
Недостатки:
Т.к. сервер может выполняться только на одном процессоре, возникает ограничение на применение СУБД для мультипроцессорных платформ. Например, если компьютер имеет 4 процессора, то СУБД с одним сервером использует только один из них, не загружая оставшиеся 3.
В некоторых системах эта проблема решается вводом промежуточного диспетчера - архитектура виртуального сервера.
Архитектура виртуального сервера.
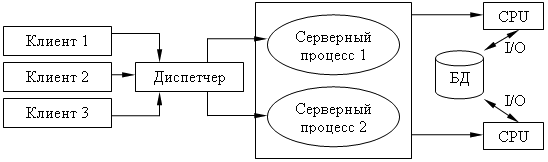
В этой архитектуре клиент подключается не к реальному серверу, а к промежуточному звену (диспетчеру), который выполняет функции диспетчеризации запросов к актуальным сервера. Количество актуальных серверов может быть согласовано с количеством процессоров в системе.
Недостатки:
- невозможно направить запрос от конкретного клиента к конкретному серверу.
- Серверы становятся равноправными, т.е. нет возможности устанавливать приоритеты для обслуживания запросов.
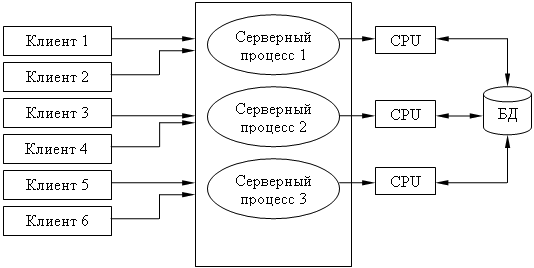
Современное решение проблемы СУБД для мультипроцессорных платформ заключается в возможности запуска нескольких серверов БД, в том числе и на различных процессорах. При этом каждый из серверов должен быть многопотоковым. Данная модель называется многонитевая мультисерверная архитектура. Она связана с вопросами распараллеливания выполнения одного пользовательского запроса несколькими серверными процессами.
Многопотоковая мультисерверная архитектура.
1.6. Типы параллелизма.
Рассмотрим несколько путей распараллеливания запросов.
Горизонтальный параллелизм возникает, когда хранимая в БД информация распределяется по нескольким физическим устройствам хранения - нескольким дискам. При этом информация из одного отношения разбивается на части по горизонтали. Этот вид параллелизма иногда называют распараллеливанием или сегментацией данных. Параллельность здесь достигается путем выполнения одинаковых операций (например, фильтрации).
Результат выполнения целого запроса складывается из результатов выполнения отдельных операций.
Достоинства:
- Сокращается время выполнения запроса.
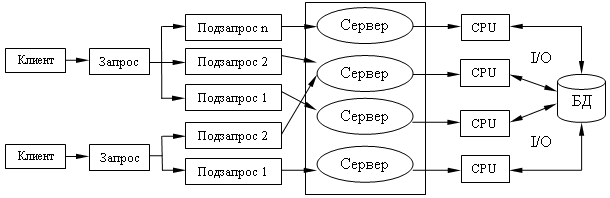
Вертикальный параллелизм достигается конвейерным выполнением операций, составляющих запрос пользователя.
Этот подход требует серьезного усложнения в модели выполнения реляционных операций ядром СУБД.
Достоинства:
- Сокращается время выполнения запроса.
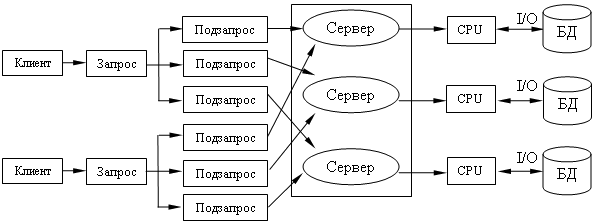
Гибридный параллелизм.
Эти методы позволяют существенно сократить время выполнения сложных запросов над очень большими объемами данных.
Выполнение запроса при вертикальном параллелизме.
Выполнение запроса при гибридном параллелизме.
1.7. Модели транзакций.
Транзакцией называется последовательность операций, производимых над БД и переводящих БД из одного непротиворечивого (согласованного) состояния в другое непротиворечивое состояние.
Транзакция рассматривается как некоторое неделимое действие над БД, осмысленное с точки зрения пользователя. В то же время это логическая единица работы системы. Разработчик БД определяет семантику совокупности операций на БД, которая моделирует с точки зрения разработчика некоторую одну неразрывную работу (это и составляет транзакцию).
Например, принимается заказ в фирме на изготовление компьютера. Компьютер состоит из комплектующих, которые сразу резервируются за данным заказом в момент его оформления. Тогда транзакцией будет вся последовательность операций, включающая следующие:
- ввод нового заказа со всеми реквизитами заказчика;
- изменения состояния для всех выбранных комплектующих на складе на "занято" с привязкой к определенному заказу;
- подсчет стоимости заказа с формированием платежного документа (например, выставляемого счета к оплате);
- включение нового заказа в производство.
С точки зрения работника - это единая последовательность операций. Если она будет прервана, то БД потеряет свое целостное состояние.
1.8. Свойства транзакций. Способы их завершения.
Модели транзакций классифицируются на основании различных свойств:
- структура транзакции
- параллельность внутри транзакции
- продолжительность
Типы транзакций:
1. Плоские (классические)
2. Цепочечные.
3. Вложенные.
Плоские транзакции характеризуются 4 классическими свойствами:
- атомарность;
- согласованность;
- изолированность;
- долговечность (прочность).
Иногда данные транзакции называются ACID-транзакциями.
ACID - Atomicity, Consistency, Isolation, Durability.
Упомянутые выше свойства означают следующее:
Атомарность - выражается в том, что транзакция должна быть выполнена в целом или не выполнена вовсе.
Согласованность - гарантирует, что по мере выполнения транзакций, данные переходят из одного согласованного состояния в другое, т.е. транзакция не разрушает взаимной согласованности данных.
Изолированность - означает, что конкурирующие за доступ к БД транзакции физически обрабатываются последовательно, изолированно друг от друга, но для пользователей это выглядит так, как будто они выполняются параллельно.
Долговечность - если транзакция завершена успешно, то те изменения, в данных, которые были ею произведены, не могут быть потеряны ни при каких обстоятельствах.
Варианты завершения транзакций:
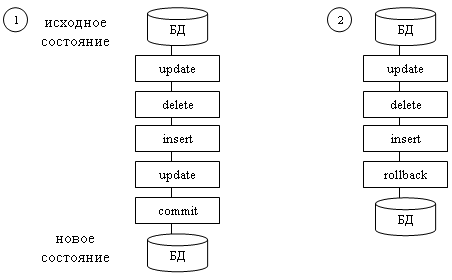
1. Если все операторы выполнены успешно и в процессе выполнения транзакции не произошло никаких сбоев программного или аппаратного обеспечения, то транзакция фиксируется.
Фиксация транзакции - это действие, обеспечивающее запись на диск изменений в БД, которые были сделаны в процессе выполнения транзакций.
Фиксация транзакций означает, что все результаты ее выполнения становятся постоянными, и станут видимыми другим транзакциям только после того, как текущая транзакция будет зафиксирована.
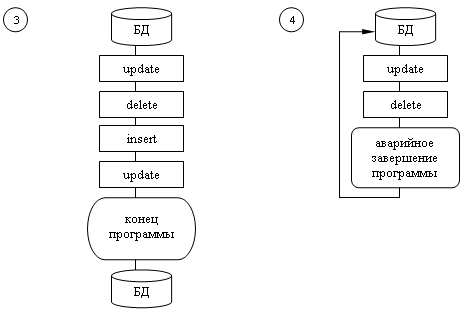
2. Если в процессе выполнения транзакций случилось нечто такое, что делает невозможным ее нормальное завершение, БД должна быть возвращена в исходное состояние.
Откат транзакции - это действие, обеспечивающее аннулирование всех изменений данных, которые были сделаны операторами SQL в теле текущей незавершенной транзакции.
Каждый оператор в транзакции выполняет свою часть работы, но для успешного завершения всей работы в целом, требуется безусловное завершение всех их операторов.
В стандарте ANSI/ISO SQL транзакция завершается одним из 4-х возможных путей:
1. Оператор COMMIT означает успешное завершение транзакции, его использование делает постоянными изменения, внесенные в БД в рамках текущей транзакции.
2. Оператор ROLLBACK прерывает транзакцию, отменяя изменения, сделанные в БД в рамках этой транзакции. Новая транзакция начинается непосредственно после использования ROLLBACK.
3. Успешное завершение программы, в которой была инициирована текущая транзакция, означает успешное завершение транзакции (как будто был использован оператор COMMIT).
4. Ошибочное завершение программы прерывает транзакцию (как будто был использован оператор ROLLBACK).
Журнал транзакций.
Реализация в СУБД принципа сохранения промежуточных состояний, подтверждения или отката транзакции обеспечивается специальным механизмом, для поддержки которого создается некоторая системная структура, называемая журналом транзакций. Он предназначен для обеспечения надежного хранения данных в БД, а также для возможности восстановления согласованного состояния БД после любого рода аппаратных и программных сбоев. Для выполнения восстановления необходима некоторая дополнительная информация, которая поддерживается в виде журнала изменений в БД. Журнализация и восстановление тесно связаны с понятием транзакции.
Общие принципы восстановления:
1. Результаты зафиксированных транзакций должны быть сохранены в восстановленном состоянии БД.
2. Результаты незафиксированных транзакций должны отсутствовать в восстановленном состоянии БД.
Это означает, что восстанавливается последнее по времени согласованное состояние БД.
Ситуации, при которых требуется производить восстановление состояния БД:
1. Индивидуальный откат транзакции. Должен быть применен в следующих случаях:
o оператор ROLLBACK;
o аварийное завершение программы;
o принудительный откат транзакции в случае взаимной блокировки при параллельном выполнении транзакций. Для выхода из тупика данная транзакция может быть выбрана в качестве "жертвы" и принудительно прекращено ее выполнение ядром СУБД.
2. восстановление после внезапной потери содержимого ОП (мягкий сбой). Случаи:
o при аварийном выключении электропитания;
o при возникновении неустранимого сбоя процессора. Такая ситуация характеризуется потерей той части БД, которая к моменту сбоя содержалась в буферах ОП.
3. восстановление после поломки основного внешнего носителя БД (жесткий сбой).
Происходит очень редко, но тем не менее СУБД должна быть в состоянии восстановить базу данных даже в этом случае. Основой восстановления является архивная копия и журнал изменений БД.
Возможны два основных варианта ведения журнальной информации:
1. Для каждой транзакции поддерживается отдельный локальный журнал изменений БД этой транзакцией (локальные журналы). Они используются для индивидуальных откатов транзакций и могут поддерживаться в виртуальной памяти.
2. Общий журнал изменений БД, используемый для восстановления состояния БД после мягких и жестких сбоев.
Достоинства:
- Позволяет выполнять индивидуальные откаты транзакций.
Недостатки:
- Приводит к дублированию информации в локальном и общем журналах, => лучше использовать второй вариант.
1.10. Структура журнала.
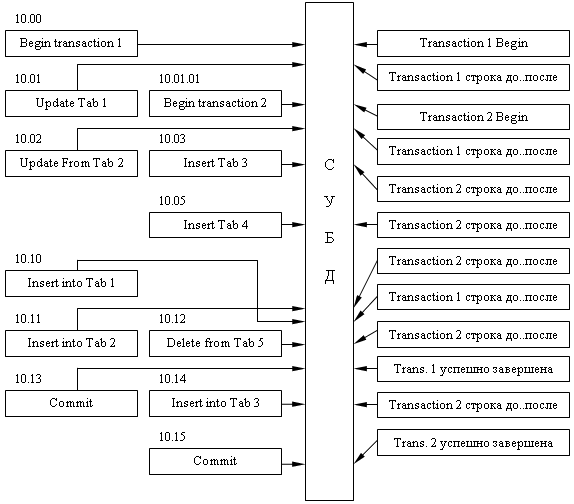
Структура журнала условно может быть представлена в виде некоторого последовательного файла, в котором фиксируется каждое изменение БД, которое происходит в ходе выполнения транзакции.
Все транзакции имеют свои внутренние номера. Каждая запись в журнале транзакций помечается номером транзакции, к которой она относится и значениями атрибутов, которые она меняет, а также команда начала и завершения транзакции.
Имеются два альтернативных варианта журнала транзакций:
1. Протокол с отложенными обновлениями.
2. Протокол с немедленными обновлениями.
Ведение журнала по принципу отложенных изменений предполагает следующий механизм выполнения транзакций:
1. Когда транзакция (T1) начинается, в протокол заносится запись 1 <T1.Begin.Transaction>.
2. На протяжении выполнения транзакции в протоколе для каждой изменяемой записи заносится новое значение: 2 <T1, TD_RECORD, атрибут, новое значение,…>, где ID_RECORD - уникальный номер записи.
3. Если все действия, из которых состоит транзакция T1, успешно выполнены, то транзакция частично фиксируется и в протокол заносится: 3 <T1.COMMIT>.
4. После того как транзакция фиксирована, записи протокола, относящиеся к T1, используются для внесения соответствующих изменений в БД.
5. Если происходит сбой, то СУБД просматривает протокол и выясняет какие транзакции необходимо переделать. Транзакцию T1 необходимо переделать, если протокол содержит обе записи (1, 3). БД может находиться в несогласованном состоянии, однако все новые значения измененных элементов данных содержатся в протоколе, и это требует повторного выполнения транзакции. Для этого используется системная процедура REDO(), которая заменяет все значения элементов данных на новые, просматривая протокол.
6. Если в протоколе не содержится команда фиксации транзакции COMMIT, то никаких действий проводить не требуется, а транзакция запускается заново.
Журнал транзакций:
Существует альтернативный механизм с немедленным выполнением предусмотренных изменений сразу в БД, а в протокол заносятся не только новые, но все и все старые значения изменяемых атрибутов. Строка в журнале транзакций выглядит так: <T1, TD_RECORD, атрибут новое значение старое значение …>. Если транзакция успешно завершена, то все изменения уже внесены в БД, а при откате транзакции выполняется системная процедура UNDO(), которая возвращает все старые значения в отмененной транзакции.
Для восстановления при сбое используется следующий механизм:
1. Если транзакция содержит команду начала транзакции, но не содержит команды фиксации (COMMIT), то выполняется последовательность действий, как при откате транзакции (т.е. восстанавливаются старые значения).
2. Если сбой произошел после выполнения последней команды изменения БД, но до команды фиксации, то команда фиксации выполняется, а с БД никаких изменений не происходит, т.е. работа происходит только на уровне протокола.
3. Изменения заносятся как в журнал транзакций, так и в БД не сразу, а сначала буферируются.
Дата добавления: 2016-01-16; просмотров: 3264;